Part 01
业务背景
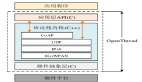
和家亲APP作为中国移动智慧家庭业务入口,承载了大量智能设备告警推送和家庭业务推送。到目前为止,平台每天产生将近30亿的推送量,如何将这些推送数据进行存储、查询和分析是一个比较棘手的问题。最初我们使用的是mysql集群分库分表方案,但随着数据量的增加,遇到了数据写入和查询的瓶颈,而且运维复杂且不便管理。结合业务特点,同时也是响应集团去IOE的要求,我们开始调研新的存储方案--国产开源时序数据库(Time Series Database)。

图1 和家亲业务数据存储方案演进
目前国产时序数据库中比较有影响力的就IoTDB和TDengine,经过我们多维度的选型测试,最终确定选择TDengine作为新的数据存储引擎,我们发现业务数据某些特点非常契合TDengine:
- 高频写入,峰值写入高达7W条/秒
- 数据很少更新且查询简单低频
- 数据存储周期自动调整
- 数据带有时间戳
Part 02
数据建模
区别于传统关系型数据库,数据写入之前需要提前建表,TDengine有超级表的概念,具备自动建表的功能。这样业务数据入库只需要建一个库和一张与业务需求相关的超级表,就可以在数据第一次入库的时候自动创建子表。自动创建子表在第一次入库时会有性能折损,但是经过测试TDengine的自动建表效率非常高,几乎可以忽略不计。在我们的业务场景中,我们把每个用户对应成一个设备一张表,用户每天产生的告警写入到自己的表中。
建库语句如下:
CREATE DATABASE `hjq_push` BUFFER 900 CACHESIZE 1 CACHEMODEL 'none' COMP 2 DURATION 180m WAL_FSYNC_PERIOD 3000 MAXROWS 4096 MINROWS 10 STT_TRIGGER 16 KEEP 10080m,10080m,10080m PAGES 160 PAGESIZE 128 PRECISION 'ms' REPLICA 3 WAL_LEVEL 1 VGROUPS 200 SINGLE_STABLE 0;超级表语句如下:
CREATE STABLE s_push (ts TIMESTAMP, guid BIGINT, source NCHAR(30),msgName NCHAR(64), msgContent NCHAR(1024), status SMALLINT, updateTime TIMESTAMP) TAGS(flag TINYINT);利用超级表写入语句:
INSERT INTO u_#{phone} USING s_push TAGS #{tag} (ts, guid, source, msgName, msgContent, status,updateTime) VALUES(#{ts},#{guid}, #{source}, #{msgName}, #{msgContent}, #{status},#{updateTime});Part 03
性能表现
3.1 高效写入
采用时序数据库的一个重要原因就是支持高频写入。TDengine写入速度极高,写接近硬盘的连续写入性能。经过业务实际测试,峰值写入7W/s完全没有压力。

图2 业务实测写入
当然要达到高效的写入性能,需要客户端、数据源和服务端配合调试才能达到最优状态。
从客户端角度:
- 尽量在一条写入sql中拼接更多数据。
- 写入方式:参数绑定>sql写入(不自动建表)>sql写入(自动建表)>无模式写入。
从数据源角度:
- 通过队列(kafka)方式来提升数据并发写入。
- 尽量将同一张子表的数据提前汇聚到一起,提高写入时数据的相邻性。
从服务器配置角度:
需要根据系统磁盘的数量、I/O 能力及处理器性能在创建数据库时设置适当的vgroups数量以充分发挥系统性能。如果vgroups过少,则系统性能无法发挥;如果vgroups过多,会造成无谓的资源竞争。常规推荐vgroups数量为CPU核数的2倍,但仍然要结合具体的系统资源配置进行调优。
3.2 系统及存储性能
TDengine已经在我们线上业务平稳运行一段时间,通过系统监控CPU使用率平常不到15%,内存使用率稳定在10%。另外由于其高效的压缩算法,可以节省大量存储空间,相比于之前MySQL集群存储只有1/7。下图为集群中一台DNode机器的监控数据:
 图片
图片
3.3 查询性能
TDengine对常见ORM框架和数据库连接池的支持较好,采用SQL作为查询语言,开发简单方便,对于之前使用关系型数据库的开发者可以无缝切换。经过业务测试,在单个子表查询都能达到ms级别。

图3 业务查询测试
Part 04
遇到的一些问题
在使用TDengine的业务实践中,也遇到一些问题(可能有些问题在最新的版本更新迭代):
- 空子表无法自动清理,由于我们数据存储有周期性,但目前的TTL策略只是针对数据而不是子表本身,针对空的子表淘汰还需要脚本介入。
- 缺少简洁易操作的可视化界面。
- 数据更新会影响count()函数性能(商业版有碎片整理功能,没试过)
- LAST_ROW函数返回的数据集字段带有last_row(row),需要单独解析
Part 05
结语
和家亲推送业务对时序数据库的使用目前也只是小试牛刀,相信随着业务的发展,会使用到更多时序数据库的功能特点。当然同样的业务数据可能还存在更优的存储方案, 无论是MySQL还是TDengine,都是优秀的数据库产品,最终还是业务场景为王,只有适配业务数据才是好产品。