












9月15日,北京人工智能产业峰会暨中关村科学城科创大赛颁奖典礼现场,智源研究院发布面向中英文语义向量模型训练的大规模文本对数据集MTP(massive text pairs)。
这是全球最大的中、英文文本对训练数据集,数据规模达3亿对,具有规模巨大、主题丰富、数据质量高三大特征,进而可以推动解决中文模型训练数据集缺乏问题。

通用语义向量模型是决定大模型性能的关键组件,可以链接外模型与外部知识;由「关联文本」为基本元素的优质训练数据,是构建通用语义向量模型的核心要素。
本次开源的MTP数据集,正是智源BGE中英文语义向量模型训练所用中英文数据。
3亿中英向量模型训练数据开放
数据在大模型训练中至关重要,构建高质量开源数据集,特别是用于训练基础模型的开源数据集对大模型发展意义重大,然而中文社区却鲜少数据开源贡献者。

本次发布的全球最大语义向量模型训练数据MTP,具备如下特征:
- 规模巨大:
3亿文本对,中文1亿,英文2亿。
- 主题丰富:
源自海量优质文本数据,涉及搜索、社区问答、百科常识、科技文献等多种主题。
- 数据质量高:
数据经过必要的采样、抽取、过滤获得;由该数据训练得到的语义向量模型BGE (BAAI General Embedding)性能大幅领先同类别模型。

MTP数据集链接:https://data.baai.ac.cn/details/BAAI-MTP
BGE 模型链接:https://huggingface.co/BAAI
BGE 代码仓库:https://github.com/FlagOpen/FlagEmbedding
鉴于数据的重要性,智源在2021年就推出了全球最大语料库WuDaoCorpora,开放200GB高质量低风险中文语料,由400余个产学研单位合作,已有770多个研发团队申请,为微软、哈佛大学、斯坦福大学、华为、阿里巴巴、腾讯、鹏城实验室等提供数据服务,有效支撑全球大模型相关研究。
今年开放的最大规模、可商用、持续更新的中文开源指令数据集COIG,由来自全球40余个机构的100多名工程师共同参与,创造了跨越国界、紧密合作的全球数据开源动人故事。
下载达数十万,广受欢迎的BGE模型升级更新
BGE 语义向量模型一经发布就备受大模型开发者社区关注,目前Hugging Face累计下载量达到数十万,且已被LangChain, LangChain-Chatchat, llama_index 等知名开源项目集成。
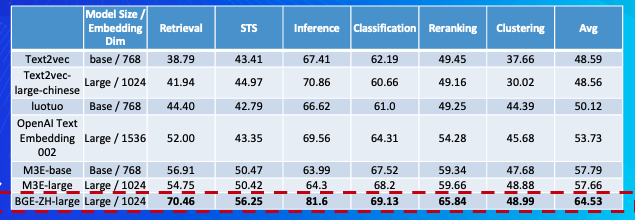
中文语义向量模型评测(C-MTEB)
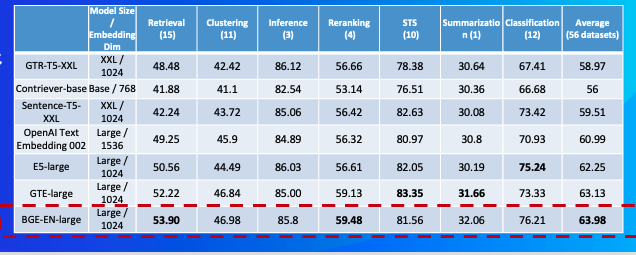
英文语义向量模型评测榜(MTEB)
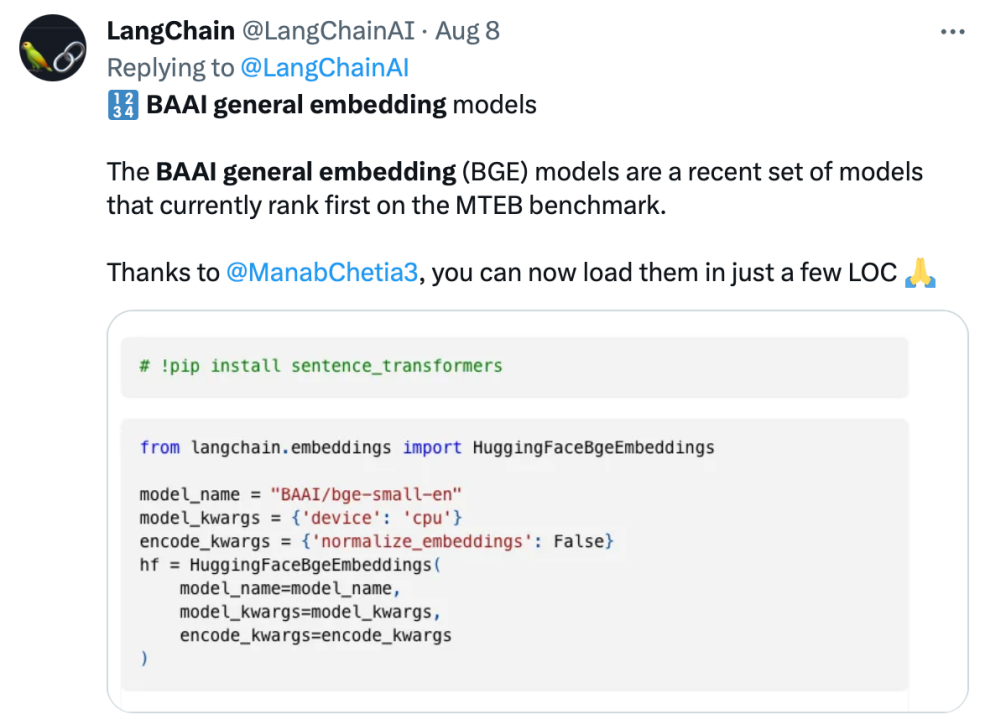
Langchain官方推文:「BGE模型在MTEB基准上排名第一」
LangChain联合创始人兼首席执行官Harrison Chase推荐
基于社区反馈,BGE进一步优化更新,表现更加稳健、出色。具体升级如下:
- 模型更新:
BGE-*-zh-v1.5缓解了相似度分布问题,通过对训练数据进行过滤,删除低质量数据,提高训练时温度系数temperature至0.02,使得相似度数值更加平稳 。
- 新增模型:
开源BGE-reranker 交叉编码器模型,可更加精准找到相关文本,支持中英双语。不同于向量模型需要输出向量,BGE-reranker直接文本对输出相似度,排序准确度更高,可用于对向量召回结果的重新排序,提升最终结果的相关性。
- 新增功能:
BGE1.1增加难负样本挖掘脚本,难负样本可有效提升微调后检索的效果;在微调代码中增加在微调中增加指令的功能;模型保存也将自动转成 sentence transformer 格式,更方便模型加载。
值得一提的是,日前智源联合Hugging Face发布了一篇技术报告,报告提出用C-Pack增强中文通用语义向量模型。

报告地址:https://arxiv.org/abs/2309.07597
构建大模型时代的类Linux生态
伴随2022年末ChatGPT 横空出世,全球大模型研发进入如火如荼的爆发期,而激烈的竞争与高昂的成本,也同时推动着开源崛起成为人工智能发展的关键推动力量。
标志性的事件是今年5月在全球人工智能圈广为流传的一篇Google内部文件,声称「开源AI将击败谷歌和OpenAI」;来自Meta的代表性开源模型 Llama则对当前产业发展起到至关重要的作用。
作为中国大模型开源生态圈的代表机构,智源正在着力打造FlagOpen飞智大模型技术开源体系,引领共建共享大模型时代的「类Linux」开源开放生态。
上线于2022年11月,正式发布于2023年2月,FlagOpen大模型技术开源体系先见性地预见大模型开源建设这一大势所趋。
现在,智源大模型技术开体系 FlagOpen 新增 FlagEmbedding 版块,聚焦于 Embedding 技术和模型,BGE 是其中首个开源模型。
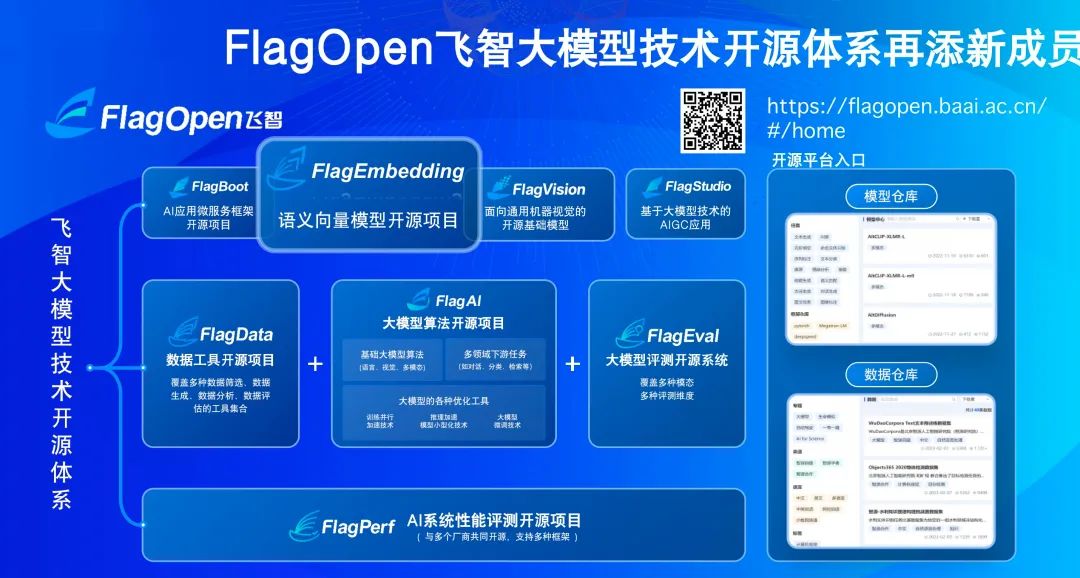
FlagEmbedding:https://github.com/FlagOpen/FlagEmbedding
在BGE项目之外,FlagOpen还有包括大模型算法、模型、数据、工具、评测等重要组成部分。
其中,FlagEval(天秤)大模型评测体系及开放平台,构建3维评测体系、覆盖600余项全面能力评测,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能。
每月发布的FlagEval大模型评测榜单,对主流模型进行多维评测解读,打造公正全面金标准,正在愈来愈成为大模型能力评价的风向标。




















