背景
ClickHouse是一个开源的OLAP引擎,不仅被全球开发者广泛使用,在字节各个应用场景中也可以看到它的身影。基于高性能、分布式特点,ClickHouse可以满足大规模数据的分析和查询需求,因此字节研发团队以开源ClickHouse为基础,推出火山引擎云原生数据仓库ByteHouse。
在日常工作中,研发人员经常会遇到业务链路过长,导致流程稳定性和数据一致性难保障的问题,这在分布式、跨服务的场景中更为明显。本篇文章提出针对这一问题的解决思路:在火山引擎ByteHouse中构建轻量级流程引擎,来解决数据一致性问题。
使用轻量级流程引擎可以帮我们使用统一的标准来解决复杂业务链路的编排问题,不仅提高业务代码的可读性和复用性,还能更专注业务核心逻辑的开发,让整体流程更加标准化、规范化。
总结来说,使用流程引擎有以下优势:
- 轻量级,接入方便,内存操作,性能有保障
- 易维护,流程配置与业务分离,支持热更新
- 易扩展,丰富的执行策略及算子支持
大体思路
 图片
图片
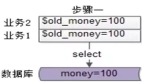
上图为ByteHouse企业版管理平台功能架构图。从该功能架构图可以看出,ByteHouse核心能力都是依赖ClickHouse集群,对于集群节点多、数据计算量大的业务场景,容易出现节点状态不一致的问题,因此保证ClickHouse集群间的状态一致性是我们的核心诉求。
 图片
图片
为了保证数据一致性,ByteHouse提供了以下能力:
- event engine: 事件处理中心
- workflow engine:轻量级流程引擎
- 对账系统
保障数据一致性最简单的方式是通过状态机来监听流程执行过程:
- 首先,将所有的任务请求下发到event engine,由event engine将任务分发对应的handler执行,统一管理所有下发任务的生命周期,并提供异步重试、回滚补偿等功能。流量汇总到event engine以后,会让服务后续的业务扩展更加便捷。
- 其次,对于比较复杂的任务请求,我们可以下发到workflow engine执行,由workflow生成实例,并编排任务队列,管理流程执行实例的生命周期,统一失败回滚,失败重试。
- 最后,对于服务不可用等特殊场景产生的脏数据,由对账服务兜底。
 图片
图片
架构设计
在流程监控的架构设计中,主要包含以下:
- 流程管理层:主要负责流程配置的解析初始化,并完成编排策略的工作
- 策略behavior层:编排执行节点,并下发执行任务到执行器
- 执行器:管理执行节点执行
- 执行节点:负责业务具体实现
 图片
图片
实现方案
执行节点
 图片
图片
流程引擎的核心为“责任链”,按照责任链上的节点顺序依次执行所有任务,所以我们需要的三个基本单元分别为:
- request:入参
- processlist:流程执行节点list
- response:出参
在研发工作中,我们时常会遇到以下问题:
- 如果同时出现了一个问题,node1、node2、node3之间的数据交互如何实现?
- 如果node1入参、出参与node2,node3不一样该如何处理?
- 参数类型不同的node又该如何统一调度?
最简单的处理办法,是让node使用相同的上下文信息,将整个执行node模版化。我们让所有的执行节点node实现相同的接口Delegation,统一使用相同的上下文executionContext作为执行方法的入参。
对于流程中的request和response,我们可以放入executionContext中,让每个执行节点都可以通过上下文操作response。
// Delegation -
type Delegation interface {
Execute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
TryExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
ConfirmExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
CancelExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
Code() string
Type() value.DelegationType
}执行策略
如果确定好了最小的执行节点,我们需要考虑到,业务场景并不会永远顺序执行node,再返回结果,流程执行过程中跳转、循环、并发执行都是比较常见的操作。考虑不同业务场景复用性,我们在执行节点之上加了一层执行策略,用策略behaivor来重新编排触发执行节点的任务。
- 下图将流程分成了behavior1和behavior2,分别对应不同的策略。
- 简单的策略举例:按顺序执行、并发执行、循环执行、条件跳转执行等。
- 我们可以根据自身业务实际需要定制,后续会有实例介绍。
 图片
图片
// ActivityBehavior -
type ActivityBehavior interface {
Enter(ctx context.Context, executionContext ExecutionContextInterface, pvmActivity PvmActivity) apperror.AppError
Execute(ctx context.Context, executionContext ExecutionContextInterface, pvmActivity PvmActivity) apperror.AppError
Leave(ctx context.Context, executionContext ExecutionContextInterface, pvmActivity PvmActivity) apperror.AppError
Code() value.ActivityBehaviorCode
}策略behavior提供有Enter,Execute,Leave三个接口,Enter负责生成执行节点任务instance,Execute负责编排并触发执行任务instance操作,Leave负责跳转到下一个behavior。
可以看出来策略behaivor的跳转方式类似于链表,不断执行next方法,所以编码过程中需要注意不要出现死循环,小心stackoverflow。
Executor
执行器Executor的主要作用是串联执行策略和执行节点,策略behavior将执行的命令下发给Executor,由Executor对执行节点的触发操作。这里会根据执行节点的type,映射到三种执行节点的执行方式,包含tcc,执行一次,重试多次。
// DelegationExecutor -
type DelegationExecutor interface {
execute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
postExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
}
func (de *DefaultDelegationExecutor) execute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError {
delegationCode := executionContext.GetExecutionInstance().GetDelegationCode()
if len(delegationCode) == 0 || de.DelegationMap[delegationCode] == nil {
logger.Info(ctx, "DefaultDelegationExecutor delegation code not found,use default delegation", zap.String("delegationCode", delegationCode))
delegationCode = string(value.DefaultDelegation)
executionContext.GetExecutionInstance().SetDelegationCode(delegationCode)
}
return de.dumpExecute(ctx, executionContext, delegationCode)
}
func (de *DefaultDelegationExecutor) dumpExecute(ctx context.Context, executionContext ExecutionContextInterface, delegationCode string) apperror.AppError {
FireEvent(ctx, executionContext, value.ExecutionStart)
var err apperror.AppError
delegation := de.DelegationMap[delegationCode]
switch delegation.Type() {
case value.TccDelegation:
err = tccExecute(ctx, executionContext, delegation)
case value.SingleDelegation:
err = singleExecute(ctx, executionContext, delegation)
case value.RetryDelegation:
err = retryExecute(ctx, executionContext, delegation)
}
if err != nil {
logger.Error(ctx, "delegation.Execute_err", zap.Error(err))
return apperror.Trace(err)
}
FireEvent(ctx, executionContext, value.ExecutionEnd)
return nil
}ExecutionContext
ExecutionContext上下文是用来记录了流程执行的所有细节,包含以下:
- ProcessEngineConfigurationInterface: 流程定义信息
- ExecutionInstanceInterface: 执行节点实例
- ActivityInstanceInterface: 执行策略实例
- ProcessInstanceInterface: 流程实例
- request:入参
- response:返回值
为了保证整个流程执行的稳定性,这里除了response之外,所以其他的实例参数都不建议开放写接口,response可以用来存储流程实例执行过程中会产生的变量信息。
对于整个流程的定义ProcessEngineConfiguration,我们可以选择最简单的方式,即在数据库里,将配置信息映射成json字符串。当然也可以选择读取配置文件,只要能满足读取方便,数据不丢即可。
// ExecutionContextInterface -
type ExecutionContextInterface interface {
GetProcessEngineConfiguration() ProcessEngineConfigurationInterface
SetProcessEngineConfiguration(processEngineConfiguration ProcessEngineConfigurationInterface)
GetExecutionInstance() instance.ExecutionInstanceInterface
SetExecutionInstance(executionInstance instance.ExecutionInstanceInterface)
GetActivityInstance() instance.ActivityInstanceInterface
SetActivityInstance(activityInstance instance.ActivityInstanceInterface)
GetProcessInstance() instance.ProcessInstanceInterface
SetProcessInstance(processInstance instance.ProcessInstanceInterface)
SetNeedPause(needPause bool)
IsNeedPause() bool
SetActivityIndex(activityIndex int)
GetActivityIndex() int
SetActivityBehaviorCode(activityBehaviorCode value.ActivityBehaviorCode)
GetActivityBehaviorCode() value.ActivityBehaviorCode
SetBizUniqueKey(bizUniqueKey string)
GetBizUniqueKey() string
GetRequest() map[string]interface{}
SetRequest(request map[string]interface{})
GetResponse() map[string]string
SetResponse(response map[string]string)
AtomicAddResponse(key string, value string)
}Listener
监听器的主要作用是用来监听流程执行中的重要参数信息。从上述executor接口可以看到fireEvent,它的作用是发送消息event,让listener监听到对应的event类型,完成一些定制化的行为。
类似于面向切面编程,我们可以在执行节点的前后增加定制化的逻辑,如打日志、监听节点执行时间,持久化流程中产生的response信息、增加链路追踪等。
API
 图片
图片
最后,我们将上述的内容拼接串联起来,主要提供三个接口:
- Start: 启动流程
- Signal: 暂停或是异常退出后,继续执行流程
- Abort: 强制中断流程
process start(){
//1.get and create ProcessEngineConfigurationInterface 解析流程定义
//2.create processInstance 创建流程实例
//3.create ExecutionContext 创建执行上下文
//4. lockstrategy trylock
//5. invoke process start
processinstance.start()
//6. persist processInstance and return
//7. lockstrategy unlock
}
processinstance start(){
// get behavior
// behavior enter
behavior.Enter(ctx, executionContext)
//behavior execute
behavior.Execute(ctx, executionContext)
//behavior leave
behavior.Leave(ctx, executionContext)
}相比于start,signal需要读取执行的细节信息,找到之前失败的执行节点位置,并加载到上下文中,再继续执行。
对于失败节点信息的持久化有两种方式:第一,可以选择在流程执行结束持久化;第二,可以通过listener在每个执行节点结束持久化。具体根据实际业务场景对于性能、数据一致性的要求做出抉择。
并发场景考虑
- behavior策略中肯定会出现定制、并发、处理多个执行节点到场景的问题,如果同时修改必定会造成数据错乱。简单的方法推荐使用带锁的容器存储,可以被修改的信息(response),此处使用的是github.com/bytedance/gopkg包里面封装的skipmap。
- lockstrategy可以自己定义最适配业务场景的,最简单的方案是redis锁,同时也考虑到系统异常退出后的恢复问题。可以参考redis官网解决特殊情况下的锁异常解决方案:https://redis.io/commands/setnx/
后续的工作
轻量级流程引擎的基本功能到此已经实现,后续的扩展优化可以围绕以下方向进行:
- 界面化展示,可以将链路执行情况展示出来
- 策略behavior维度扩展,适配各种业务场景
- 增加子流程的维度,可以复用原先的执行逻辑
Demo示例
以下为简单的processconfiguration的配置信息,此处使用DefaultBehavior,即同步顺序执行策略。
{
"ProcessContentList":[
{
"Behavior":"DefaultBehavior",
"DelegationList":[
{
"Code":"sample1"
},
{
"Code":"sample2"
},
{
"Code":"sample3"
}
]
},
{
"Behavior":"DefaultBehavior",
"DelegationList":[
{
"Code":"sample4"
},
{
"Code":"sample5"
}
]
}
]
} 图片
图片
在listener里面加入日志,这样可以追溯出整个流程的执行流程,以便更好的监控整个流程的运行状态。
实际使用
以ClickHouse集群缩容为例:
 图片
图片
{
"ProcessContentList":[
// 查询所有需要重分布的table
{
"Behavior":"DefaultBehavior",// 顺序执行
"DelegationList":[
{
"Code":"hor_reshard_table_loop"
}
]
},
// 遍历所有table进行数据的重分布
{
"LoopKey":"reshard_table_loop_key",
"Behavior":"NonBlockLoopBehavior",// 非阻塞循环处理
"DelegationList":[
{
"Code":"hor_reshard_table"
}
]
},
// 进行删除节点操作
{
"Behavior":"DefaultBehavior",
"DelegationList":[
{
"Code":"hor_start_remove_node"
},
{
"Code":"hor_prepare_node_vcloud",
"PostCode":"hor_rollback_remove_node_vcloud"// 统一失败回滚处理
},
{
"Code":"hor_update_config_vcloud",
"PostCode":"hor_rollback_remove_node_vcloud"
},
{
"Code":"hor_set_cluster_running",
"PostCode":"hor_rollback_remove_node_vcloud"
},
{
"Code":"hor_release_node"
},
{
"Code":"hor_callback_bill"
}
]
}
]
}总结
一个流程引擎适配所有的业务场景几乎是不可能,除非接受复杂的方案设计,而第三方流程引擎对于日常的业务开发显得太笨重。轻量级流程引擎则会简化接入方式,减少了过多http请求带来的性能损耗,更加灵活多变,追述问题也变得简单。
在ByteHouse中加入流程引擎的能力,能以较小的代价给业务更多重试的可能性,而不需要反复回滚,特别对于耗时很长的任务,能带来更好用户使用体验。除此之外,流程引擎还能将业务流程模版化,增加接口服务的复用性,使得业务代码的可读性、扩展性得到提升,方便后期维护。
火山引擎云原生数据仓库ByteHouse是火山引擎旗下的一款云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析,同时还具备便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。