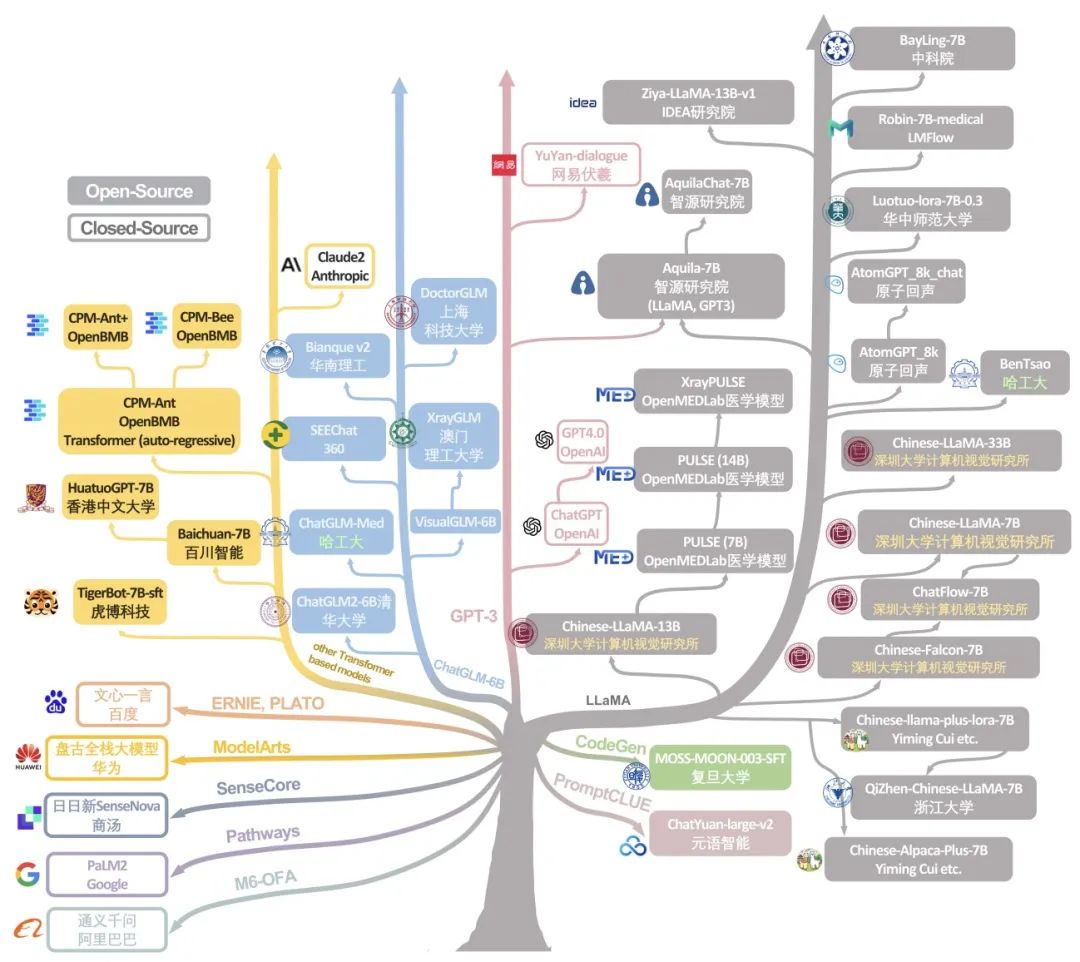
近年来,大型语言模型(LLM)在自然语言领域(NLP)掀起了革新的狂潮,在大规模、高质量数据训练的驱动下,LLM 在多种领域都展现出卓越的性能。LLMs 的崛起不仅让我们重新审视了自然语言的处理方式,更是为多个领域注入了革新的 “新鲜血液”。值得注意的是,近期像 ChatGPT、BLOOM、Llama 这样的 LLM 正在大量涌现与飞速进化,令人叹为观止。更令人兴奋的是,国内多个优秀模型,如 Ziya-LLaMA、ChatGLM、baichuan 等,也在 LLM 的世界舞台上崭露头角。这一潮流不仅见证了 LLM 不断涌现和更新迭代,还展示了它们在医疗健康领域的巨大潜力。
在这一浪潮中,放射学 NLP 领域备受瞩目,LLM 在这个领域的发展和应用更是已经成为不可忽视的趋势。然而,尽管 LLMs 发展趋势迅猛,系统性地评估它们在放射科 NLP 能力上的研究还远远不足,尤其是对来自像中国这样的多语言国家的新兴模型的研究:这些模型在英文和中文(等其它语言)的多语言处理能力方面有独特的优势,但却鲜有深入的科学性能评估研究。在医学和放射学领域,我们正面临着一个亟需填补的知识空白。
因此,我们认为有必要对这些全球性 LLMs 进行严格且系统性的探索和分析。这不仅有助于更全面、更深入地了解它们的能力和局限性,还能将它们有机地融入全球 LLMs 的生态系统中之中,从而推进全球医疗领域、放射学领域 LLM 社区的发展。本研究旨在通过广泛测试全球 31 个主流 LLMs 在两个公开放射科数据集 (MIMIC-CXR 和 OpenI) 上的性能,验证它们在生成放射学诊断信息(impression)的能力。

论文地址:https://arxiv.org/pdf/2307.13693.pdf
在这项研究中,我们采用了一系列具体指标来评估模型,模型的评估标准均基于它们从放射学发现生成诊断信息的能力,通过具体指标来验证模型所生成诊断信息的质量。所用指标包括零样本(zero-shot)、一样本(one-shot)和五样本(five-shot)条件下的 Recall@1、Recall@2 和 Recall@L。通过将这 31 个国际主流 LLMs 在这些指标上进行 “竞争”,我们旨在揭示它们在放射学领域的相对优势和劣势,为 LLMs 在放射学领域的应用提供更加深入的理解。
值得一提的是,这项研究的成果不仅有助于推动放射学自然语言处理工具和LLM的优化和开发,而且这些 LLM 模型也将成为放射科医师和广泛医学界的宝贵工具,推动放射学 NLP 领域的发展。在这个充满挑战和机遇的时刻,我们对 LLMs 在放射学领域的应用充满信心,并期待它们在未来的发展中发挥更加重要的作用。
方法介绍
测试方法
对于整体实验,我们会使用一些精心设计的 prompt 和推理参数来测试这 31 个大模型。对于三类样本数推理测试,即 zero-shot、one-shot 以及 five-shot inference,我们结合专业医疗意见,对每种都设计了专有、统一的 Prompt 来进行测试。结合过程中的测试的效果,我们在大量实验中总结、固定了推理参数,即 temperature=0.9、top-k=40 以及 top-p=0.9。
模型选择
鉴于资源和比较一致性的考虑,我们集中评估了拥有约 70 亿参数的大型语言模型(LLMs)。这个参数规模被选中是因为它在计算效率和性能之间取得了平衡,使得在高效地全面评估成为可能,并能够代表不同类型的 LLMs 性能。对于开源模型,我们从官方 GitHub 存储库获取了代码和模型参数,确保了正确的实施和评估。而对于商业模型,我们利用它们的应用程序编程接口(APIs),以一致可靠的方式与模型进行交互,确保了评估的准确性和一致性。
测试 Prompt
为了确保在不同的 LLM 之间进行公平而公正的比较,不论是 zero-shot、one-shot,还是 five-shot 的情形,我们都严格遵循相同的提示设置,保持了一致性。在 zero-shot 评估中,模型将面对全新的任务,没有任何之前的示例可供参考。而在 one-shot 的情景下,我们向模型提供了一个先前的示例作为参考。同时,在 five-shot 的情况下,模型将得到五个示例供其学习。所有的示例都是结合医疗建议严格挑选、设计。这些评估场景旨在模拟真实世界的使用条件,其中模型只获得有限数量的示例,并需要从中推导出通用规则。
数据集
我们的研究充分利用了 MIMIC-CXR 和 OpenI 两个放射学领域广泛使用的公开数据集,评估了大型语言模型(LLMs)在生成放射学文本报告方面的性能。我们的研究重点集中在放射学报告的 “Finding” 和 “Impression” 部分,这些部分提供了对影像结果和放射科医师的详细解释性文本信息。
实验结果
在 OpenI 数据集上,Anthropic 的 Claude2 实现了最佳的 zero-shot 表现,而 BayLing-7B 在 five-shot 中领先。在 MIMIC-CXR 上,Claude2 再次在 zero-shot 中排名第一,PaLM2 在 one-shot 中排名第一,BayLing-7B 在 five-shot 中领先。
我们观察到在不同模型之间存在显著的性能差异。这些全面的测试结果为每个 LLM 在放射科应用中提供了质量指标数据,为领域研究者提供了关于其丰富的优势和劣势的深刻见解。
众多的实验结果表明,国内许多新兴 LLM 与全球对手相比也有充分的竞争力,能够在全球性的舞台上作为后起之秀与全世界的对手一决高下。但是,像 AtomGPT_8k 这样的一些模型在所有设置下的表现都很差。总体而言,模型大小并不意味着表现一定优越与否,更重要的是对于模型应用领域的适应性,我们的结果正是强调了根据特定放射科任务而不是模型大小本身来仔细选择 LLM 的重要性,我们的工作正是为现在 LLM 研究中模型大小与效果优劣的相关问题抛出了预见性的 “橄榄枝”,为日后更为高效的 LLM 研究提供了经验知识。


结论
这项开创性的研究对来自全球各大团队的 LLM 在解释放射科报告这一领域进行了详尽的评估。关于模型之间能力和性能的差距所获得的见解将作为引导未来扩展 LLM 以增强在放射科领域、乃至更多医疗健康领域实践的坚固基石。通过审慎的应用和开发,LLM 在促进全球医疗保健交付方面显示出巨大的前景。
但是,总体而言结果中 LLM 局限的能力(仍然不够高的指标得分)预示着还需要开展持续的研究,开发更具有专业性、领域性、精确性的多语言和多模态 LLM, 以充分发挥它们在不同医学专业中的潜力,这将为全世界的医疗行业提供启发与便利,并且也是通用人工智能(AGI)在医疗行业中又一强大可能性。
总之,本全面基准测试研究对于 LLM 作为全球放射科医生的宝贵工具的采用做出了重要贡献,推进了全球 LLM 社区,尤其是在放射学、医疗领域的发展,为 AGI 在医疗领域的进一步实践、发展提供了重要启示。