












基于Transformer的视觉基础模型在各种下游任务,如分割和检测中都展现出了非常强大的性能,并且DINO等模型经过自监督训练后已经涌现出了语义的分割属性。
不过奇怪的是,类似的涌现能力并没有出现在有监督分类训练后的视觉Transformer模型中。
最近,马毅教授团队探索了基于Transformer架构的模型中涌现分割能力是否仅仅是复杂的自监督学习机制的结果,或者是否可以通过模型架构的适当设计在更通用的条件下实现相同的涌现。

代码链接:https://github.com/Ma-Lab-Berkeley/CRATE
论文链接:https://arxiv.org/abs/2308.16271
通过大量的实验,研究人员证明了当采用白盒Transformer模型CRATE时,其设计明确地模拟并追求数据分布中的低维结构,整体和部分级别的分割属性已经以最小化的监督训练配方出现。
分层的细粒度分析表明,涌现属性有力地证实了白盒网络的设计数学功能。我们的结果提出了一条设计白盒基础模型的途径,该模型同时具有高性能和数学上完全可解释性。
马毅教授也表示,深度学习的研究将会逐渐从经验设计转向理论指导。

白盒CRATE的涌现属性
DINO的分割涌现能力
智能系统中的表征学习旨在将世界的高维、多模态感官数据(图像、语言、语音)转换为更紧凑的形式,同时保留其基本的低维结构,实现高效的识别(比如分类)、分组(比如分割)和追踪。

深度学习模型的训练通常采用数据驱动的方式,输入大规模数据,以自监督的方式进行学习。
在视觉基础模型中,自监督Transformer架构的DINO模型展现出了令人惊讶的涌现能力,即使没有经过有监督分割训练,ViTs也能识别出显式的语义分割信息。
后续有工作研究了如何在DINO模型中利用这种分割信息,并在下游任务中,如分割、检测等实现了最先进的性能,也有工作证明了用DINO训练的ViTs中的倒数第二层特征与视觉输入中的显著性信息强烈相关,如区分前景、背景和物体边界,从而提升图像分割和其他任务的性能。
为了让分割属性涌现,DINO需要在训练期间将自监督学习、知识蒸馏和权重平均巧妙地结合起来。
目前还不清楚DINO中引入的每个组件是否对于分割遮罩的涌现来说必不可缺,尽管DINO也采用ViT架构作为其主干,但在分类任务上训练的普通有监督ViT模型中,并没有观察到分割涌现行为。
CRATE的涌现
基于DINO的成功案例,研究人员想要探究,复杂的自监督学习管道对于获得类似Transformer的视觉模型中的涌现属性是否是必要的。
研究人员认为,在Transformer模型中促进分割属性的一种有前途的方法是,在考虑输入数据结构的情况下设计Transformer模型架构,也代表了表征学习经典方法与现代数据驱动的深度学习框架的结合。

与目前主流的Transformer模型对比,这种设计方法也可以叫做白盒Transformer模型。
基于马毅教授组之前的工作,研究人员对白盒架构的CRATE模型进行了广泛的实验,证明了CRATE的白盒设计是自注意力图中分割属性涌现的原因。
定性评估
研究人员采用基于[CLS] token的注意力图方法对模型进行解释和可视化,结果发现CRATE中的query-key-value矩阵都是相同的。

可以观察到CRATE模型的自注意力图(self-attention map)可以对应到输入图像的语义上,模型的内部网络对每个图像都进行了清晰的语义分割,实现了类似DINO模型的效果。
相比之下,在有监督分类任务上训练的普通ViT却并没有表现出类似的分割属性。

遵循之前关于可视化图像学习的逐块深度特征的工作,研究人员对CRATE和ViT模型的深度token表征进行主成分分析(PCA)研究。

可以发现,CRATE可以在没有分割监督训练的情况下,依然可以捕捉到图像中物体的边界。
并且,主成分(principal compoenents)也说明了token和物体中相似部分的特征对齐,例如红色通道对应马腿。
而有监督ViT模型的PCA可视化结构化程度相当低。
定量评估
研究人员使用现有的分割和对象检测技术对CRATE涌现的分割属性进行评估。
从自注意力图可以看到,CRATE用清晰的边界显式地捕获了对象级的语义,为了定量测量分割的质量,研究人员利用自注意力图生成分割遮罩(segmentation mask),对比其与真实遮罩之间的标准mIoU(平均交并比)。

从实验结果中可以看到,CRATE在视觉和mIOU评分上都显著优于ViT,表明CRATE的内部表征对于分割遮罩任务生成来说要更有效。
对象检测和细粒度分割
为了进一步验证和评估CRATE捕获的丰富语义信息,研究人员采用了一种高效的对象检测和分割方法MaskCut,无需人工标注即可获得自动化评估模型,可以基于CRATE学到的token表征从图像中提取更细粒度的分割。


在COCO val2017上的分割结果中可以看到,有CRATE的内部表征在检测和分割指标上都要好于有监督ViT,有监督ViT特征的MaskCut在某些情况下甚至完全不能产生分割遮罩。
CRATE分割能力的白盒分析
深度在CRATE中的作用
CRATE的每一层设计都遵循相同的概念目的:优化稀疏速率降低,并将token分布转换为紧凑和结构化的形式。
假设CRATE中语义分割能力的涌现类似于「表征Z中属于相似语义类别token的聚类」,预期CRATE的分割性能可以随着深度的增加而提高。
为了测试这一点,研究人员利用MaskCut管道来定量评估跨不同层的内部表征的分割性能;同时应用PCA可视化来理解分割是如何随深度加深而涌现的。

从实验结果中可以观察到,当使用来自更深层的表征时,分割分数提高了,与CRATE的增量优化设计非常一致。
相比之下,即使ViT-B/8的性能在后面的层中略有提高,但其分割分数明显低于CRATE,PCA结果显示,从CRATE深层提取的表征会逐渐更关注前景对象,并且能够捕捉纹理级别的细节。
CRATE的消融实验
CRATE中的注意力块(MSSA)和MLP块(ISTA)都不同于ViT中的注意力块。
为了了解每个组件对CRATE涌现分割属性的影响,研究人员选取了三个CRATE变体:CRATE, CRATE-MHSA, CRATE-MLP,分别表示ViT中的注意块(MHSA)和MLP块。
研究人员在ImageNet-21k数据集上应用相同的预训练设置,然后应用粗分割评估和遮罩分割评估来定量对比不同模型的性能。
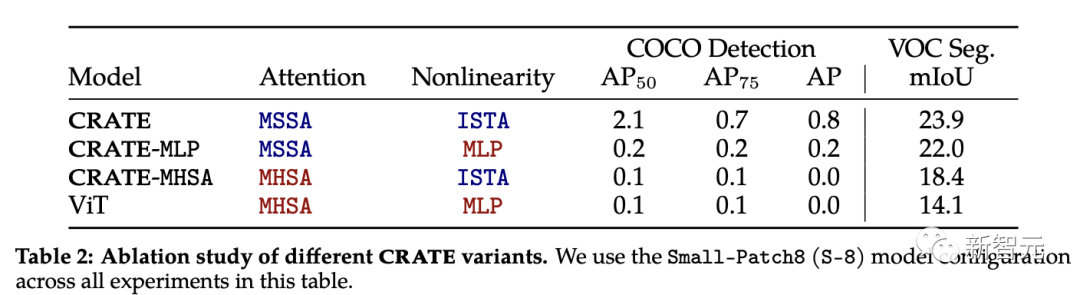
实验结果显示,CRATE在所有任务中都明显优于其他模型架构,可以发现,尽管MHSA和MSSA之间的架构差异很小,但只需要简单地用CRATE中的MSSA替换ViT中的MHSA,可以显著改善ViT的粗分割性能(即VOC Seg),证明了白盒设计的有效性。
识别注意头的语义属性
[CLS] token和图像块token之间的自注意力图可以看到清晰的分段掩码,根据直觉,每个注意力头应该都可以捕捉到数据的部分特征。
研究人员首先将图像输入到CRATE模型,然后由人来检查、选择四个似乎具有语义含义的注意力头;然后在其他输入图像上在这些注意力头上进行自注意力图可视化。
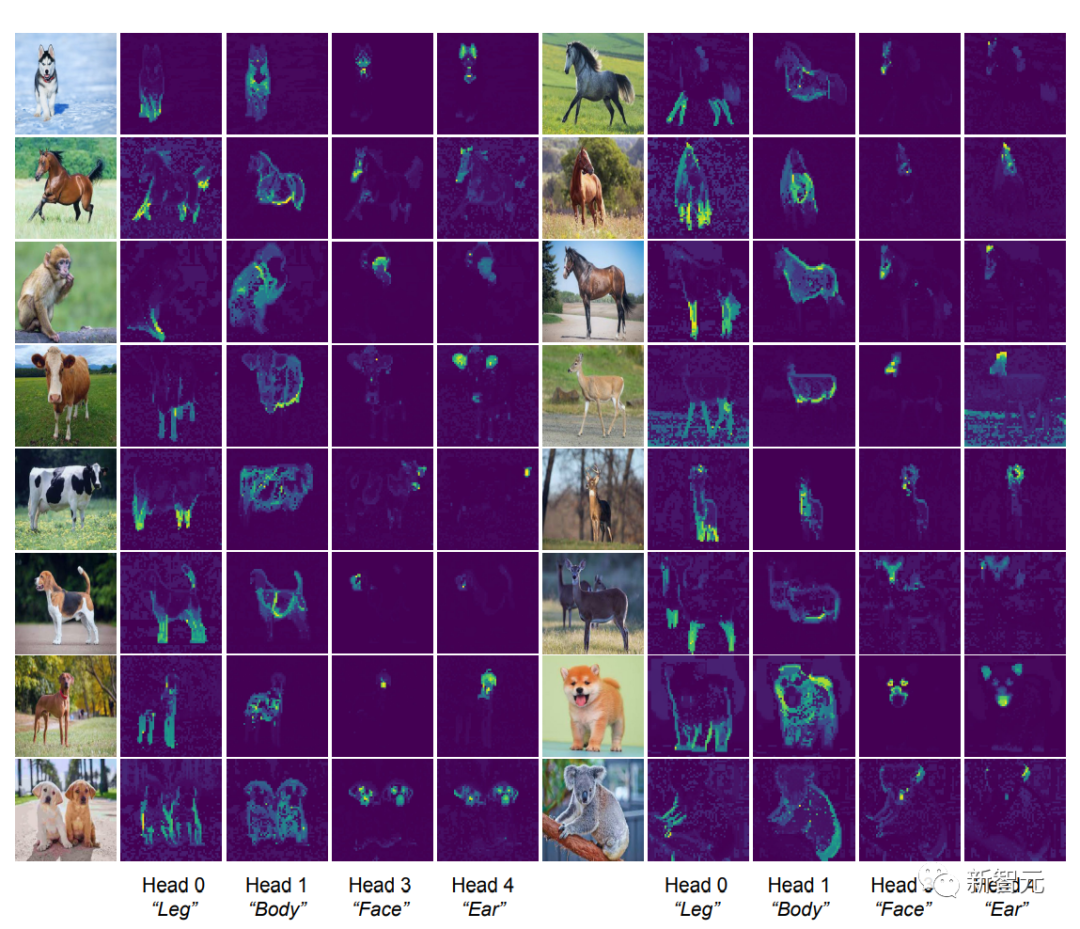
可以发现,每个注意力头都捕捉到了物体的不同部分,甚至不同的语义:例如第一列中显示的注意力头可以捕捉到不同动物的腿,最后一列中显示的注意力头捕捉的是耳朵和头部。
自从可形变部件模型(deformable part model)和胶囊网络发布以来,这种将视觉输入解析为部分-整体层次结构的能力一直是识别架构的目标,白盒设计的CRATE模型也具有这种能力。




















