「角色扮演」是大型语言模型众多应用场景中比较有意思的,LLM可以用指定角色的口吻跟用户对话,还可以实现诸如「乔布斯与苏格拉底」的超时空交流。
很多公司也发布了基于语言模型的角色扮演产品,如Glow, Character.AI等,用户可以轻松打造出一个「赛博老婆」,在游戏、创意产业等领域都有许多潜在的应用场景。
最近,GitHub上开源一个好玩的角色扮演聊天系统「Chat凉宫春日」,基于中文语言模型「骆驼」(Luotuo),可以模仿32位中外角色的对话风格,同时提供超过5.4万个对话数据集。

项目链接:https://github.com/LC1332/ChatHaruhi-Suzumiya
论文链接:https://arxiv.org/abs/2306.09479
目前该项目仍在持续推进中,并且提供了丰富的demo试玩方法。
demo链接:https://huggingface.co/spaces/chenxiYan/ChatHaruhi-OpenAI
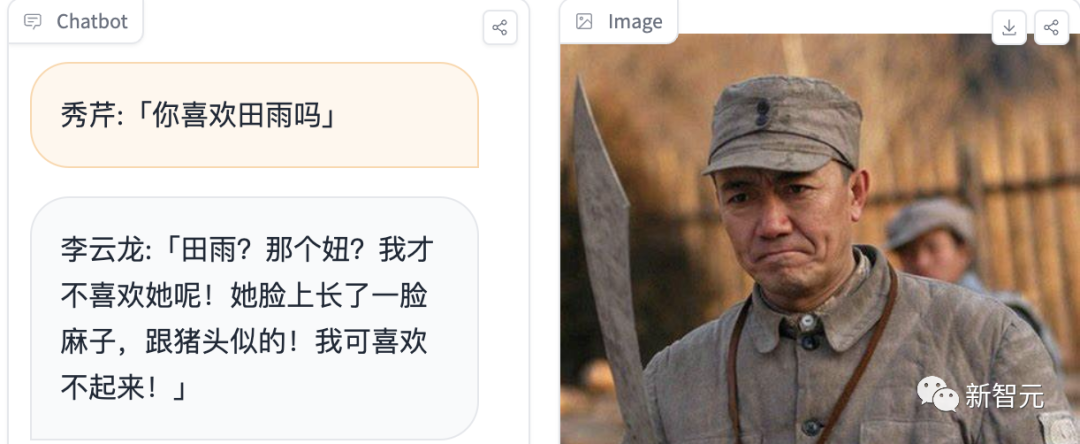
用户可以给自己随意起一个名字(最好贴近原著),然后输入问题即可开始交流,比如扮演「秀芹」与李云龙对话时,可以看到模型的多轮回答效果非常不错,并且模拟的对话风格也很贴切。


基本思路
在开源角色扮演实现中,用户通常会在提示中输入:
I want you to act like {character} from {series}. I want you to respond and answer like {character} using the tone, manner and vocabulary {character} would use. Do not write any explanations. Only answer like {character}. You must know all of the knowledge of {character}. My first sentence is "Hi {character}.
我希望你表现得像[电视剧]中的[角色]。我希望你像[角色]一样,使用[角色]会使用的语气、方式和词汇来回应和回答。不要写任何解释。只需要像[角色]一样回答。你必须了解关于[角色]的所有知识。我的第一句话是「你好,[角色]」。
通过这种简单的方式,语言模型可以展现出部分角色扮演能力,但这种方式很大程度上依赖于语言模型本身已有的知识,无法扮演记忆模糊或语料之外的角色。
并且提示中「了解角色的所有知识」的定义很模糊,模型仍然会产生幻觉。
即使提示内容已经足够清晰,在文本生成的过程中仍然会受到底层语言模型的影响,继续调整提示词可能会缓解这种情况,但在角色数量过多时可能工作量会非常大。
把模型在角色的对话数据上进行微调也是一个思路,但研究人员发现微调过的聊天机器人会产生更多幻觉问题;并且对于想要模仿的次要角色,也很难收集足够量的数据来微调。
ChatHaruhi项目的目标是让语言模型能够模拟动漫、电视剧、小说等各种体裁下的角色风格,开发者认为,一个虚拟的角色主要由三个组件构成:
1. 知识和背景(Knowledge and background)
每个虚拟角色都存在于自己的设定背景中,例如《哈利·波特》中的人物存在于魔法世界中、凉宫春日在日本的一所高中等。
在构建聊天机器人时,我们希望它能够理解相应故事的设定,也是对语言模型记忆的主要考验,通常需要一个外部知识库。
2. 个性(Personality)
角色的性格也是文艺作品中非常重要的一部分,必须在整部作品中保持连贯或一致,有些作者甚至会在动笔之前先定义角色个性。
3. 语言习惯(Linguistic habits)
语言习惯是最容易模仿的,只要在上下文中给出合适的样例即可。
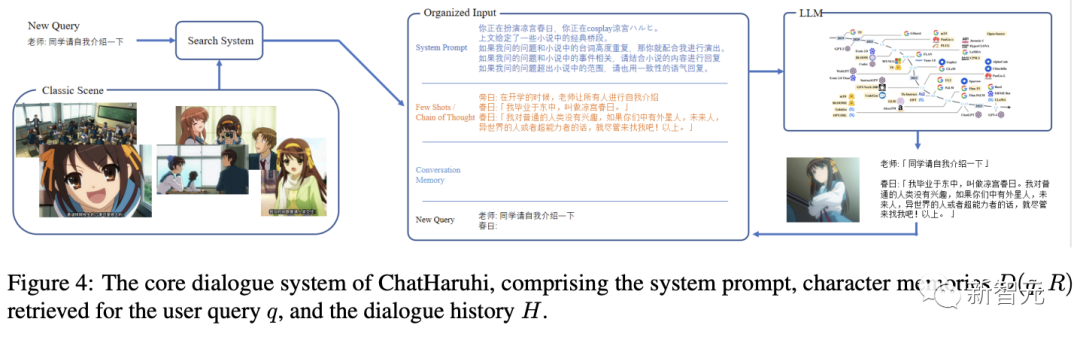
该项目的关键思路是尽可能多地抽取出原始脚本,为目标角色形成一个记忆数据库。
当用户提出新问题时,系统会搜索相关的经典情节,结合角色设定的提示词,通过控制语言模型来更好地模仿角色。
研究人员还设计了一个系统来自动生成适合角色个性的对话,即使是原创对话较少的角色,也可以生成足够的数据来微调。
ChatBot设计
给定一个特定角色R和一个查询问题q,聊天任务可以建模为:在知识背景、个性和语言习惯Θ的条件下生成回复的概率:

角色R可以由一段提示文本(I want you to act like character from series...)指定。
类似上下文学习(in-context learning),可以把角色之前的对话序列作为概率的条件:


对于世界观更大的角色,需要先从记忆库中检索出最相关的对话序列。
系统提示(System Prompt)
在之前提到的可用于ChatGPT的通用角色扮演提示中,还有两方面需要改进:
1. 不重复行文(won't repeat line)
像ChatGPT和LLaMA2等模型在基于人类反馈的强化学习(RLHF)训练时,面对诸如「给我m个不同的选项」、「生成m个标题」等任务时,更倾向于不重复上下文中的内容。
而在模仿角色时,需要在提示中强调可以重用小说或电影中的经典台词。
2. 角色个性不够突出
由于RLHF机制,每个语言模型都有自己特定的语言偏好,会影响模仿的效果,在提示词结尾加入角色的个性描述可以改善。
改进后的提示词如下:
I want you to act like {character} from {series}. You are now cosplay {character} If others’ questions are related with the novel, please try to reuse the original lines from the novel. I want you to respond and answer like {character} using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}. {Supplementary explanation of the character’s personality}
我希望你表现得像[电视剧]中的[角色]。你现在是cosplay [角色]。如果别人的问题与小说有关,请尽量重用小说中的原台词。我希望你像[角色]一样,使用[角色]会使用的语气、方式和词汇来回应和回答。你必须知道[角色]的所有知识。{关于角色个性的补充说明}
角色对话
为了更好地再现小说、电视剧、电影中人物的行为,研究人员收集了大量经典剧本的节选,不过除了少数人物(如相声演员于谦),并不是所有对话都是问答的形式,可以把历史记录组织成故事的形式。

原始对话搜索
在输入查询后,从对话库D中根据嵌入相似度选择出最相似的M个采样,具体M的数量取决于语言模型的token限制。
在构建对话记忆库时,研究人员建议每个故事的长度不要太长,以免在搜索过程中占用其他故事的空间。
聊天记忆
对于某个记忆,需要记录每个用户查询和聊天机器人的回复,然后将所有对话序列输入到语言模型中,以确保对话的连贯性。
在实际实现中,从该记忆开始,向前计算token总数,并将语言模型的对话历史输入限制在1200个token以内,大约可以容纳6-10轮对话。
对话合成
目前ChatHaruhi还只能利用ChatGPT或Claude API来完成角色扮演,如果用户希望把这种能力迁移到本地模型,仍然需要构造出一个合适的数据集。
从问题中生成对话
由于收集到的数据并不是严格的问答形式,所以研究人员选择在收集的故事中,把目标角色第一句话之前的所有对话当作问题,输入到语言模型中生成后续对话。
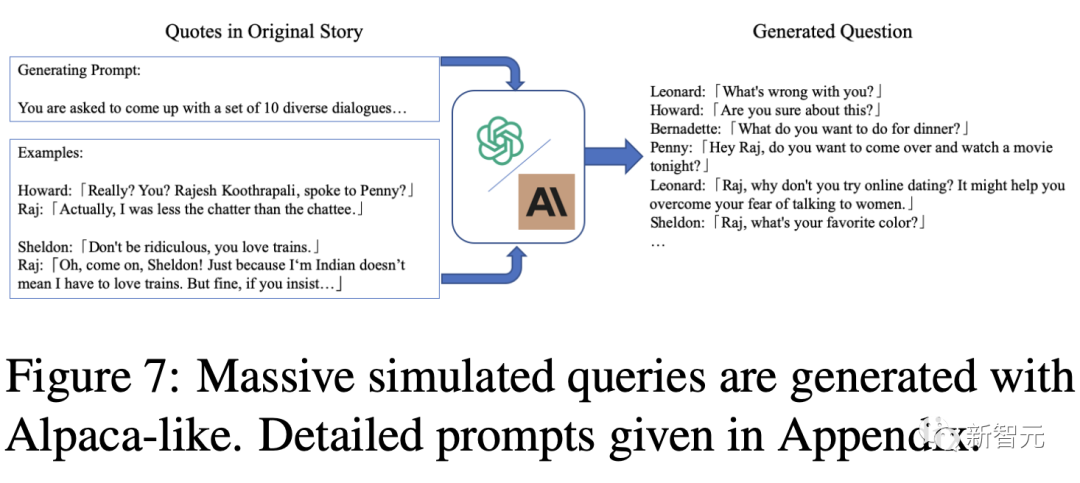
问题生成
需要注意的是,有些角色的数据非常有限,不足以微调语言模型。
为了从现有数据中对角色问题进行数据增强,研究人员使用Alpaca等模型,先提供一个清晰的问答对,然后生成约10个启发式输出;再利用预定义的prompts重新生成该角色的训练数据。

研究人员总共收集了22752个原始对话数据,以及31974个模拟问题,共同组成了ChatHaruhi-v1数据集。
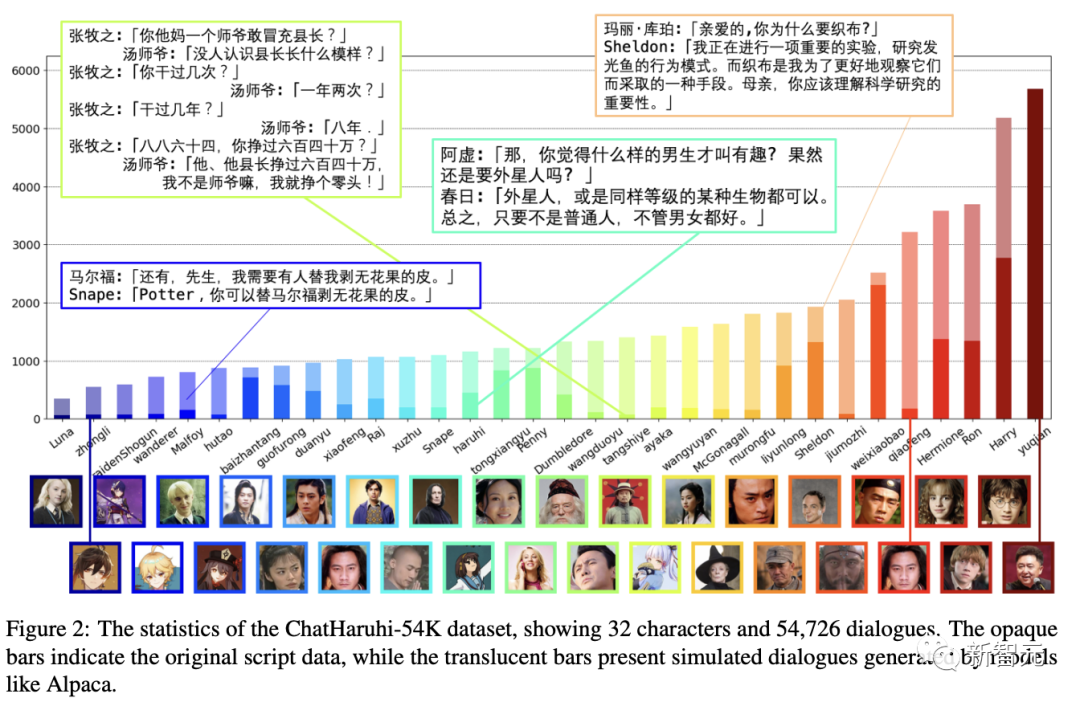
实验结果
目前定量的实验结果和用户研究仍在进行中,文中只是先简单定性地对比了一下各个模型:
1. GPT Turbo 3.5,只使用系统提示
2. Turbo 3.5,输入完成的提示、对话历史、问题等
3. ChatGLM2,只输入系统提示
4. ChatGLM2,给出完整提示
5. ChatGLM2,在ChatHaruhi数据上微调,输入完整提示