












大型语言模型在推理上仍然是弱势项目,需要依赖各种思维工具辅助完善推理过程。
最近,苏黎世联邦理工大学、华沙理工大学的研究人员共同提出了一个全新的LLM思维框架GoT(Graph of Thoughts,GoT),在推理质量和推理速度上都要超越现有的思维链(CoT)和思维树(ToT)等方法。

论文链接:https://arxiv.org/pdf/2308.09687.pdf
GoT的关键思想和主要优势在于将LLM生成的信息建模为图(arbitary graph),其中信息单元(思维,LLM thoughts)作为图的顶点,顶点之间的依赖关系作为图的边。
GoT方法可以将任意的LLM思维组合成协同结果,提取出整个思维网络的本质,或者使用反馈回路来增强思维。
通过实验可以证明GoT在不同任务上提供了优于现有技术的优势,例如,与ToT相比,排序任务的质量提高了62%,同时成本降低了31%
研究人员认为,GoT方法可以让LLM推理更接近人类的思维和大脑推理机制,比如二者都在内部形成了复杂的网络结构。
LLM思维(thought)的进化之路
用户与LLM对话的过程主要包括用户消息(提示,prompts)和模型回复(思维、想法,thoughts),其中回复可以是一段文本(摘要任务)、一个文档(生成任务)或是一个代码块等。
为了充分激活语言模型的能力,通常会采用各种提示方法:

1. Input-Output (IO) 提示
输入序列后,直接用语言模型获取输出,不添加任何中间思考过程。
2. 思维链(Chain-of-Thought, CoT)
在输入和输出之间引入多个中间思维状态,相比IO方法,可以显著提升语言模型在数学难题和通用推理任务上的性能。
3. 多思维链
独立生成多条思维链,然后根据预先指定的评分指标返回最佳输出结果的思维链。
自一致思维链(CoT-SC)方法可以将CoT扩展到多条推理路径,不过没有进行单路径内的「局部探索」,例如回溯(backtracking)。
4. 思维树(Tree of Thoughts, ToT)
ToT将过程或推理建模为一棵思维树来增强CoT-SC方法,单个树节点代表部分解决方案;基于给定的节点,思维生成器(thought generator)可以构造出一定数量的新节点,然后用状态评估器(state evaluator)为每个新节点生成相应评分。
根据用例的不同,可以使用LLM自身对输出结果进行评估,也可以利用人工评分等。
扩展树的过程中,节点的调度取决于使用的搜索算法,如深度优先、广度优先。
其他方法如思维分解(thought decomposition)等或多或少都隐含使用了树的思路。
思维图(Graph of Thought, GoT)框架
总体来说,GoT包含四部分:
1. 语言模型推理过程,即在特定上下文中,所有语言模型的思维,以及思维之间的关系
2. 潜在的思维转换
3. 用于获取思维评分的评估函数
4. 用于选择最相关思维的排序函数

推理过程
研究人员将推理过程建模为一个有向图,顶点代表某个问题(初始问题、中间问题、最终问题)的一个解决方案,有向边代表使用「出节点」作为直接输入构造出的思维(入节点),具体思维的形式取决于用例。
图节点的类别也不一定相同,例如在生成任务中,某些节点代表「写一段文字的规划」,另一些节点用来对「实际文本段」进行建模,推理过程是一个异构图(heterogeneous graph)。
思维转换
基于图结构,GoT可以在推理中实现不同的思维转换,也可以叫做graph-enabled transformations.
比如说,在写作任务中,可以将几篇输入文章合并成一个连贯的摘要;在排序任务中,可以将几个排序后的数字子数组(sub-array)合并成一个最终的排序数组。

每次变换操作都包含两部分:1)反映当前推理状态的图,以及2)一个用到的语言模型。
变换操作会修改当前的图,添加新的节点和输入边。
为了最大化GoT的表现力,用户可以指定要删除的相应顶点和边来显式删除思维;为了节省上下文空间,用户可以删除推理中未来不改进的部分。
1)聚合转换(Aggregation Transformations)
GoT可以将任意多个思维聚合成一个新的思维,并将不同思维的优势结合起来。
在最基础的形式中,只创建一个新的节点,其余思维链中的节点作为出节点连接到新节点中。
更一般地,该操作还可以聚合推理路径,也就是组成更长的推理路径
2)优化转换(Refining Transformations)
可以修改当前思维节点v为一条循环边(v, v),代表与原始思维相同迭代思维。
3)生成转换(Generation Transformations)
可以基于已有的单思维节点生成一个或多个新的思维,和之前的推理模式,如ToT或CoT-SC类似。
对思维进行评分和排序
评估函数所需要的数据包括受评估的思维、整个推理过程的状态以及语言模型,要求全推理过程可以最大化函数的通用性。
在对思维的排序时,其输入包括推理过程、语言模型以及指定返回k个评分最高的思维。
系统架构&可扩展性

GoT架构由一组交互模块组成:
1. 提示器(Prompter):为LLM准备信息
主要负责把图结构编码进提示词中,GoT架构允许用户根据不同用例实现不同的图编码,提供全部图结构访问权限。
2. 解析器(Parser):从LLM的回复中抽取信息
解析器为每个思维构造出一个思维状态(thought state),包含了抽取出的信息,并用于后续状态更新。
3. 评分模块(Scoring):对LLM回复进行验证和评分
验证一个给定的LLM思维是否能够满足潜在的正确性条件,然后对思维进行打分。
具体分数可能需要构造提示,让语言模型给出评价;对某些用例来说,人类反馈评分也可以;如果是排序之类的用例,可能还需要引入局部评分函数。
4. 控制器(Controller):协调整个推理过程,并决定如何继续推理
控制器中包含两个重要组件:图操作(the Graph of Operations, GoO)和图推理状态(GRS)。
其中GoO是一个静态结构,指定了给定任务上的图分解过程,即规定了可用于LLM思维转换的操作,以及思维之间的顺序和依赖关系;每个操作对象都知道自己的前置操作和后继操作。
GRS是一个动态结构,用来维护LLM推理过程进行中的状态,包括所有思维的历史及状态。

示例用例
1. 排序
比如任务是对有重复的0-9数字序列进行排序,直接输入的话,语言模型无法对超过一定长度的序列正确排序。

在GoT框架中,研究人员采用基于合并的排序方法:
首先将输入的数字序列分解为多个子矩阵;然后对子矩阵分别进行排序;再将子矩阵进行排序;最后将所有子矩阵合并,得到最终结果。

在这个用例中,LLM思维就是一串有序的数字序列。
为了对LLM的输出进行评分,假定输入序列a的长度为n,输出序列b的长度为m,可以将误差范围定义为:

X表示错误排序的连续数字对的数量,如果相邻两个数字排序错误,即左边的数字大于右边,则X加一。
Y表示,输出序列中的数字频率,与输入序列频率的吻合程度。
2. 关键词计数任务
GoT框架将输入文本分割成多个段落,计数每个段落中的关键字,并聚合子结果。
段落的数量可以预先定义,也可以留给LLM分割,或者将每个句子视为一个单独的段落。
为了获得对思维的评分,首先需要对每个关键字推导出计数和正确计数之间的绝对差值,然后将所有差值相加,并得到最终分数。
3. 文档合并
该任务的目标是基于几个内容部分重叠的输入文档生成一个新的保密协议(NDA)文档,尽量减少重复,同时最大限度地保留信息,可以广泛应用于法律程序等领域。
为了给解决方案打分,研究人员要求语言模型查询两个值(每个值三次,取平均值),第一个值对应于解决方案冗余(10表示没有冗余,0表示至少一半的信息是冗余的),第二个值代表信息保留(10表示保留了所有信息,0表示没有保留),然后计算调和平均值。
延迟与思维量的权衡
GoT在延迟(思维图中达到给定最终思维的跳数)和思维量(volume,思维图中存在通往某个思维的路径数量)之间的权衡,也比之前的提示方案要好。
假设输出一个思维的时间成本为O(1),每个提示方案的总成本固定为Θ(n):
1. CoT-SC由源自单个起始思维的k个独立链组成;
2. ToT是一个完整的k-ary树;
3. 在GoT中,在完整k-ary树的叶子处与一个大小相同但边反向的镜像k-ary树连接起来;
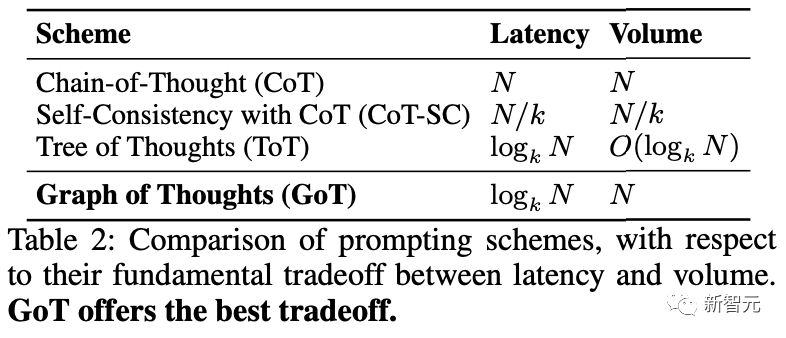
可以看到,虽然CoT-SC提供的思维量为N,但代价是高延迟(N);CoT-SC将延迟降低了k倍(对应于分支因子),但同时也将容量降低了k倍。
ToT提供logk N的延迟,但容量也下降了;
GoT是唯一一个同时具有logk N的低延迟和高容量N的方案,可能是由于GoT利用聚合思想,可以从分解图中的其他中间思维获取到最终思维。
实验结果

总的来说,GoT在排序、找集合交集、关键词计数和文档合并任务上,其结果质量要比基线模型更好,并且推理成本也更低。
GoT vs. ToT
在所有任务中,GoT都比ToT(树的分支更多、深度较浅)和ToT2(树的分支少、深度更深)的性能更好。ToT通常比ToT2的质量更高,但消耗也更大。
相比ToT,GoT方法将中值误差降低了约62%,从而实现了更高的排序质量,并且运行成本降低了31%以上;优势主要是因为GoT能够将复杂的任务分解成更简单的子任务,独立解决这些子任务,然后逐步将这些结果合并成最终结果。
GoT vs. IO / CoT
GoT的质量更高,对于排序(P=64)任务,GoT的中值误差分别比CoT和IO低约65%和约83%,不过GoT和ToT的运行成本远高于IO和CoT
随着问题规模P的增加,GoT相比其他基线来说质量提升更大。
总的来说,这个分析说明了GoT确实非常适合复杂的问题案例,因为推理调度通常会随着问题规模的增长而变得更加复杂。















