













由于LLM架构固有的内存限制,使得生成又慢又贵。
对此,很多大佬都在寻找一种挽救的方法。Karpathy曾多次提出,大模型「投机采样」对于推理时间优化是一个出色的方案。

但是,尽管投机解码能够加速生成速度,但因其太过复杂,并没有被许多开发者采用。
今天,来自普林斯顿、UIUC等机构的华人团队提出了全新的简单框架:Medusa(美杜莎)。

没有额外的草稿模型,研究人员只是引入了几个额外的解码头,微调出「美杜莎头」,能够在单个A100-8G GPU,一天时间内完成训练。
结果发现,Medusa直接让模型推理加速约2倍。

Vicuna-7b与Medusa
为什么LLM生成效率低?
从系统角度来看,LLM生成遵循一种「以内存为限制」的计算模式,主要的延迟瓶颈来自内存读取/写入,而非算术计算。
这一问题的根源在于,自回归解码过程中固有的顺序性。

即每次前向传递都需要将整个模型的参数,从高带宽内存(HBM)传输到加速器的计算单元。
尽管每个样本只产生一个token,但这个操作未能充分利用现代加速器的算术计算能力,由此导致模型效率低下。

在LLM崛起之前,应对这种低效率的常见方法是,简单地「增加批大小」,从而实现更多token的并行生成。
但大模型的不断涌现,让情况变得更加复杂。
在这种情况下,增加批大小不仅会带来更高的延迟,还会大大增加Transformer模型的键-值缓存的内存需求。
此外,这种低效率也体现在「成本结构」上。
截止到2023年9月,与仅处理提示相比,GPT-4的生成成本约高出2倍,Claude 2的生成成本大约高出3倍。
研究人员主要关注的重点是,改善LLM生成的延迟,同时Medusa也可以适用于需要平衡延迟和吞吐量的LLM服务。
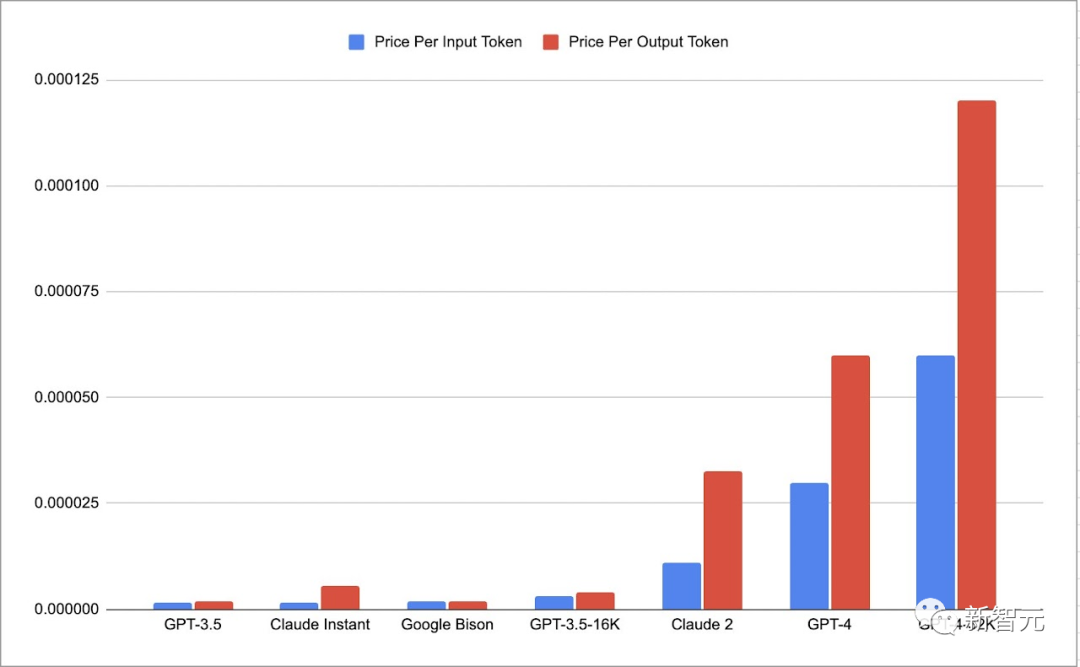
每个token的价格
「投机解码」是终极解决方案?
基于上述的挑战,加速文本生成的一种吸引人策略是:更高效地利用计算资源。
具体来说,通过并行处理更多的token。
这种方法,采用了一个简化的「草稿」模型,每一步都能快速生成一批token的候选项。
然后,这些候选token将通过原始的、全尺寸的语言模型进行验证,以确定最合理的文本延续。
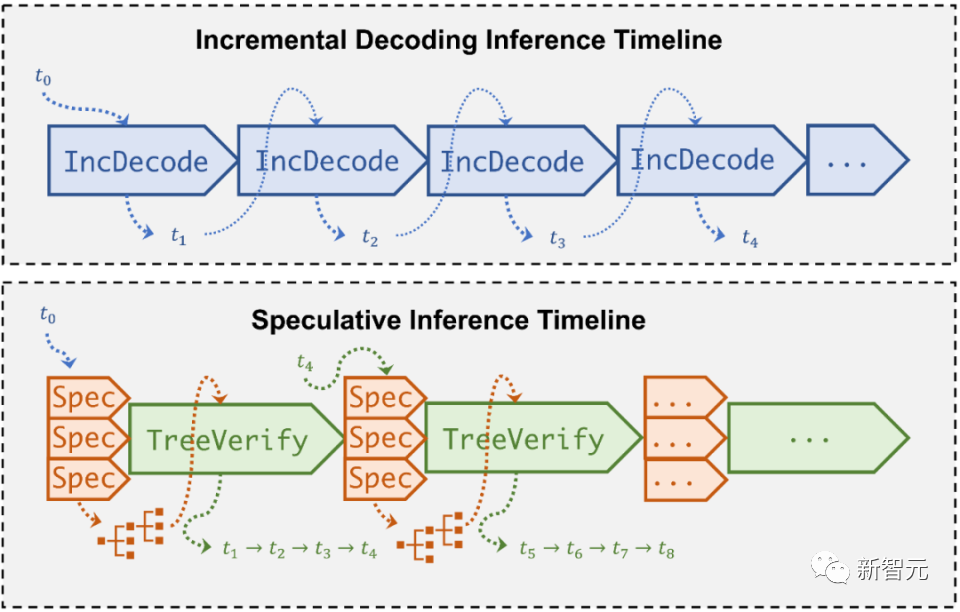
这一基本逻辑基于一个有趣的假设:「草稿」模型虽然小,但应该足够娴熟,能够生成原始模型可以接受的序列。
如果这个假设成立,「草稿」模型可以迅速生成token序列,同时原始模型可以高效地并行验证多个token,从而最大化计算吞吐量。
最近的研究表明,通过精心调整的草稿模型,投机解码可以将延迟降低高达2.5倍,令人印象深刻。
然而,这种方法并非没有挑战:
1. 寻找理想的「草稿模型」(Draft Model):找到一个「小而强大」的草稿模型,与原始模型很好地协调,说起来容易,做起来难。
2. 系统复杂性:在一个系统中托管两个不同的模型会引入多层的复杂性,不论是计算还是操作,尤其是在分布式环境中。
3. 采样效率低:使用投机解码进行采样时,需要使用一种重要性采样方案。这会带来额外的生成开销,尤其是在较高的采样温度下。
这些复杂性和权衡限制了投机解码的广泛采用。因此,虽然投机解码前景广阔,但并未被广泛采用。
Medusa:将简单与高效融合
为了满足对更加用户友好,且功能强大的解决方案的需求,普林斯顿研究团队推出了创新框架Medusa(美杜莎)。
它不仅加速了模型的生成,甚至让LLM能够让更多人去访问和使用。
据介绍,最新方法重新回顾了「Blockwise Parallel Decoding for Deep Autoregressive Models」论文中,一个被低估的宝藏:
回溯Transformer模型的发明,与其引入一个全新的「草稿」模型来预测后续token,为什么不简单地扩展原始模型本身呢?

论文地址:https://arxiv.org/abs/1811.03115
这就是「Medusa head」(美杜莎头)发挥作用的地方。
这些额外的解码头与原始模型无缝集成在一起,在每个生成的关键点产生token块。
与草稿模型不同的是,Medusa head可以与原始模型一起训练,而原始模型在训练期间保持冻结状态。
这种方法允许研究人员在单个GPU上微调大模型,充分利用强大的基础模型学习到的表征。
此外,由于新的头仅由一个与原始语言模型头类似的层构成,因此Medusa不会增加服务系统设计的复杂性,并且适用于分布式环境。
单靠Medusa head,并不能达到将处理速度提高一倍的目标。
但这里有一个小技巧:将其与基于树状注意力机制配对使用时,就可以并行验证由Medusa head生成的多个候选项。
这样一来,Medusa head的预测能力速度提升2倍-3倍。
另外,研究人员摒弃了传统的重要性采样方案,专门为Medusa head生成创建了一种高效且高质量的替代方案。
这种新方法完全绕过了采样开销,甚至进一步提升了Medusa的加速步骤。
简而言之,研究人员用一个简单的系统解决了投机解码的挑战:
1. 没有独立的模型:不是引入一个新的草稿模型,而是在同一个模型上训练多个解码头。
2. 轻松集成到现有系统中:训练参数效率高,即使是GPU性能较差的情况下也可以进行。而且由于没有额外的模型,无需调整分布式计算设置。
3. 将采样视为一种放松:放宽与原始模型分布相匹配的要求,使得「非贪心生成」甚至比「贪心解码」更快。
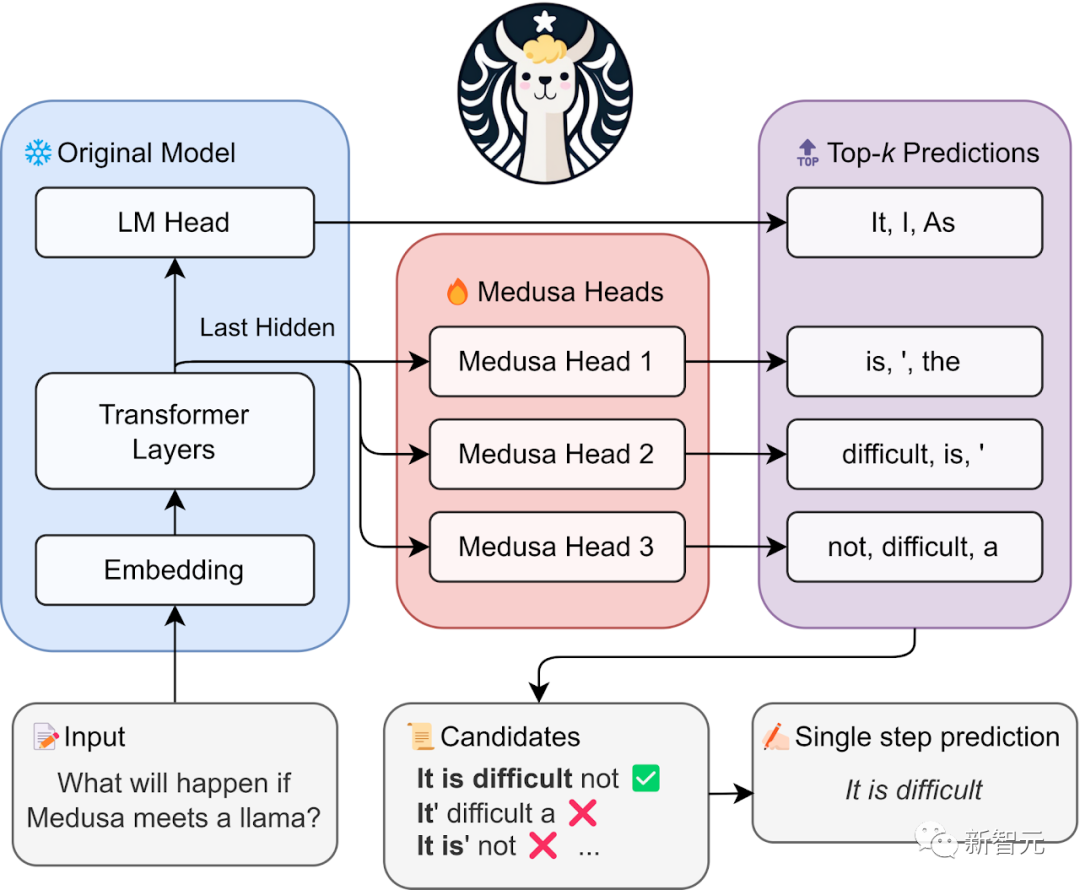
Medusa概述
具体来说,Medusa在LLM的最后隐藏状态之上引入了多个头,使其能够并行预测多个后续token。
在使用Medusa head扩充模型时,原始模型在训练期间被冻结,只有Medusa head经过微调。这种方法使得在单个GPU上对大型模型进行微调成为可能。
在推理过程中,每个头为其指定的位置生成多个顶级预测。这些预测被组合成候选项,并使用基于树状注意力机制并行处理。
最后一步是,使用典型接受方案选择合理的延续,被接受的最长候选项prefix将用于下一阶段的解码。
这样,Medusa通过同时接受更多token,从而减少所需的解码步骤,提高了解码过程的效率。
接下来,让我们深入了解Medusa的三个组成部分:Medusa head(美杜莎头)、tree attention(树状注意力机制)和典型接受方案。
Medusa head(美杜莎头)
那么,Medusa head究竟是什么呢?
它们类似于原始架构中的语言模型头(因果Transformer模型的最后一层),但有一个变化:它们预测多个即将出现的token,而不仅仅是下一个token。
受到块状并行解码方法的启发,研究人员将每个Medusa head作为单层前馈网络来实现,并增加了一个残差连接。
训练这些头非常简单。你可以使用训练原始模型的相同语料库,或者使用模型本身生成新的语料库。

在这个训练阶段,原始模型保持不变;只有Medusa head经过微调。
这种有针对性的训练会带来一个参数效率极高的过程,并能迅速达到收敛。
尤其是,与在推测解码方法中训练独立的草稿模型的计算复杂性相比,优势更加突出。
在研究人员测试的Vicuna模型上,Medusa head在预测next-next token方面准确率达到60%,位列第一。同时,它仍然有改进的空间。
tree attention(树状注意力机制)
测试中,团队发现一些引人注目的指标:尽管对于预测next-next token的第1名准确率大约在60%左右,但第5名的准确率却超过了80%。
这个显著的提高表明,如果可以有效利用Medusa head产生多个排名靠前的预测,就可以增加每个解码步骤生成的token数量。
为了实现这个目标,研究人员首先通过从每个Medusa head的顶级预测中,获取笛卡尔积来创建一组候选项。
然后,根据图神经网络的思路,将依赖关系图编码到注意力机制中,以便可以并行处理多个候选项。
比如,使用第一个Medusa head的前2个预测,以及第二个Medusa head的前3个预测,如下所示。
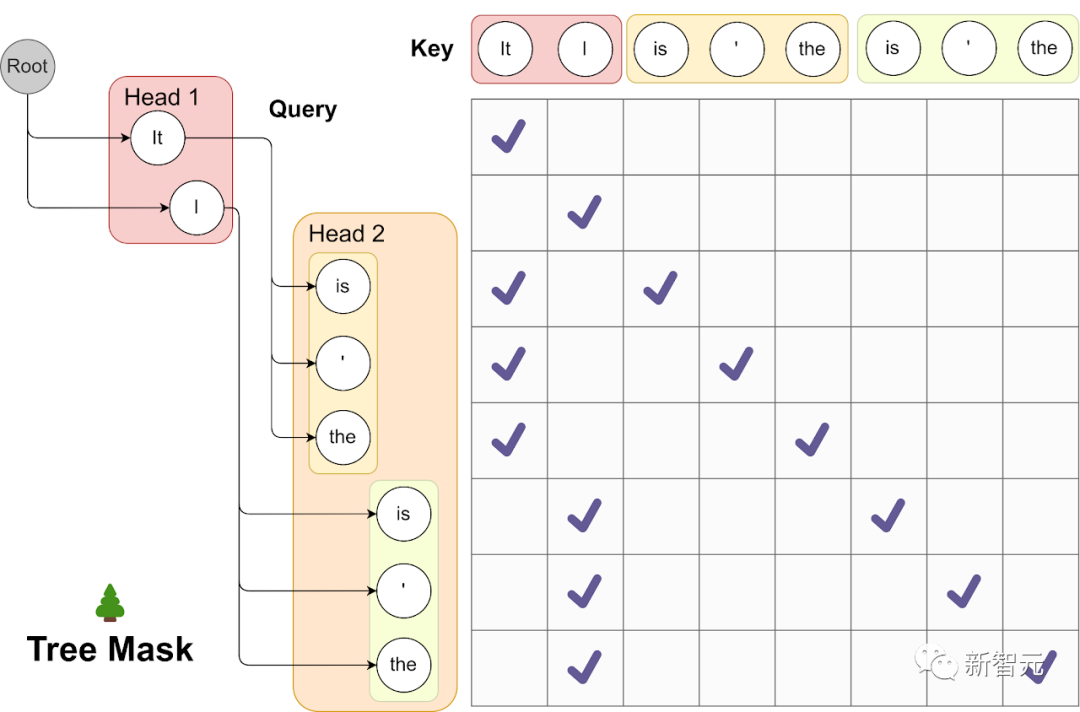
树状注意力
上图中的可视化效果,展示了使用树状注意力同时处理多个候选项的过程。
在这种情况下,第一个头的任何预测都可以与第二个头的任何预测配对,形成一个多级树结构。
这个树的每一层,都对应着一个Medusa head的预测。由此,能够产生2*3=6个候选项。
这些候选项中的每一个对应于树结构内的一个不同的分支。
为了确保每个token只访问其前置token,研究人员设计了一种注意力掩码,专门允许注意流从当前token返回到其前置token。
通过这样做,并相应地位位置编码设置位置索引,可以在不需要增加批大小的情况下,同时处理各种候选项。
研究人员还指出,一些研究也采用了非常相似的树状注意力思想。
与它们相比,最新的方法更倾向于一种更简单的树状注意力形式,在推理期间,树状模式是规则的且固定的,使得树状注意力掩码进行预处理,进一步提高了效率。
典型接受
在早期关于投机解码的研究中,「重要性采样」被用来产生与原始模型预测密切相关的各种输出结果。
然而,后来的研究表明,随着采样温度升高,这种方法的效率往往会降低。
简单来说,如果你的草稿模型和你原来的模型一样好,理想情况下,你应该接受它的所有输出,从而使这个过程变得超级高效。
然而,重要性采样可能会在中间环节,拒绝这个解决方案。
在现实世界中,我们经常调整采样温度,只是为了控制模型的创造力,不一定是为了匹配原始模型的分布。
那么为什么不把重点放在,可接受可信的候选项上呢?
对此,研究人员引入了「典型接受」方案。
从现有的截断采样(truncation sampling)中汲取灵感,普林斯顿研究人员目标是根据原始模型选择足够可能的候选项。
研究人员根据根据原始模型的预测概率设置一个阈值,如果候选项超过这个阈值,就会被接受。
用专业术语来说,研究人员采用硬阈值,以及熵相关阈值中的最小值,来决定是否像截断采样那样接受候选项。
这确保了在解码过程中,选择有意义的token和合理延续。
研究人员总是使用贪心解码接受第一个token,确保在每个步骤中至少生成一个token。最终输出是通过研究接受测试的最长序列。
这一方法的高明之处在于,适应性强。
如果你将采样温度设置为0,它就会恢复到最有效的形式——贪心解码。当温度升高时,最新研究的方法变得更加高效,可以接受更长的序列。
并且,研究人员还已经通过严格的测试证实了这一说法。
因此,从本质上讲,最新的典型接受方案提供了一种更有效的方式,让LLM进行更创造性地输出。
Llama「吐口水」可以有多快?
研究人员使用了专门针对聊天应用进行微调的Vicuna模型对Medusa进行了测试。
这些模型的大小不同,参数数量分别为7B、13B和33B。
研究的目标是,测量Medusa在实际聊天机器人环境中如何加速这些模型。
在训练Medusa head时,研究人员采用了一种简单的方法,使用了公开可用的ShareGPT数据集。这是最初用于Vicuna模型的训练数据的子集,仅进行了一个epoch的训练。

而且,关键是,根据模型参数的大小,整个训练过程可以在几小时到一天之内完成,仅需要一块A100-80G GPU。
值得注意的是,Medusa可以轻松与量化的基础模型结合使用,以减少内存需求。
研究人员利用这一优势,在训练33B模型时使用了8位量化。为了模拟实际环境,他们使用了MT bench进行评估。
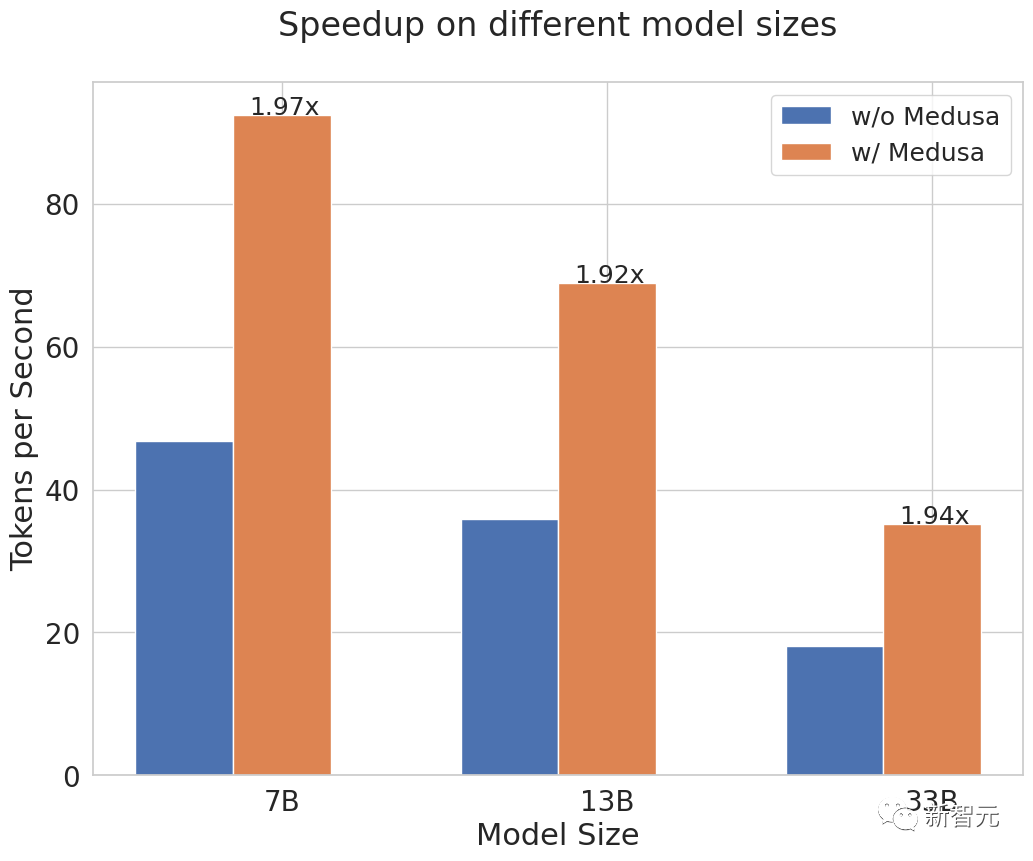
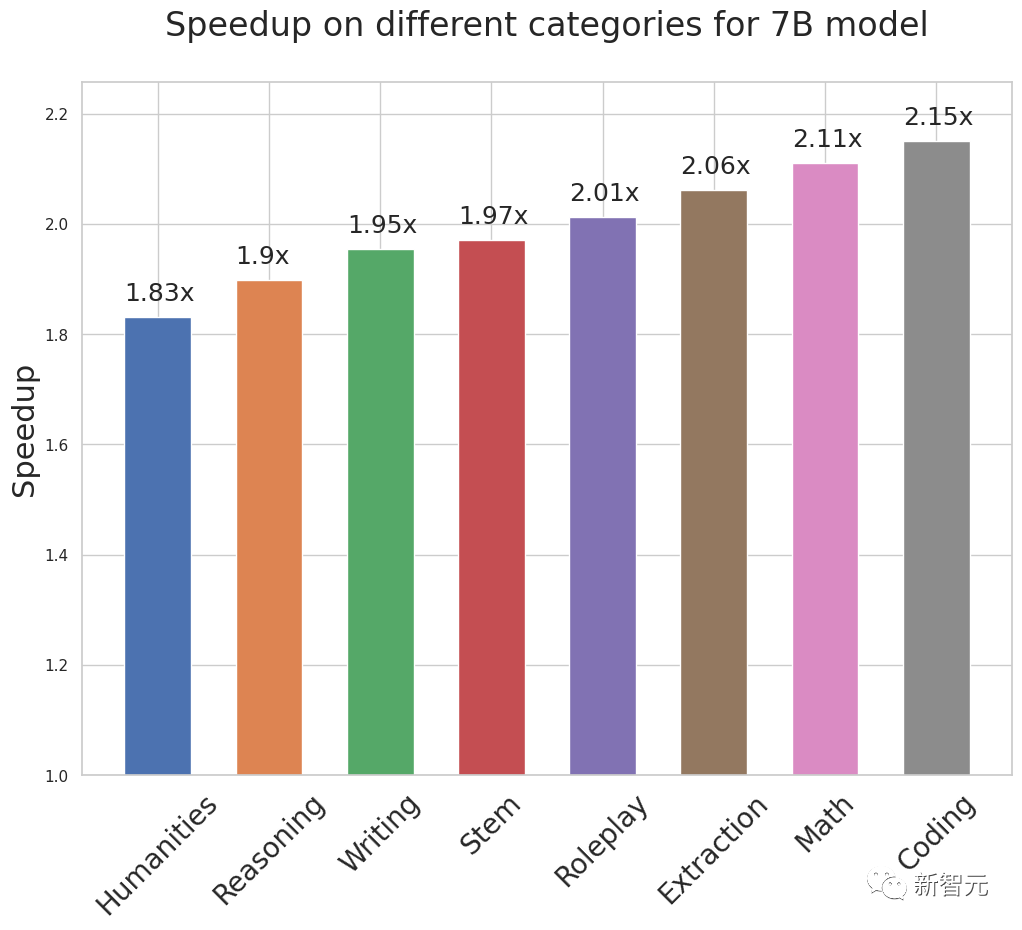
凭借其简单的设计,Medusa在各种用例中,始终能够实现约2倍的绝对时间加速。
值得注意的是,通过Medusa的优化,33B参数的Vicuna模型可以像13B模型一样迅速运行。
消融实验
Medusa head的配置
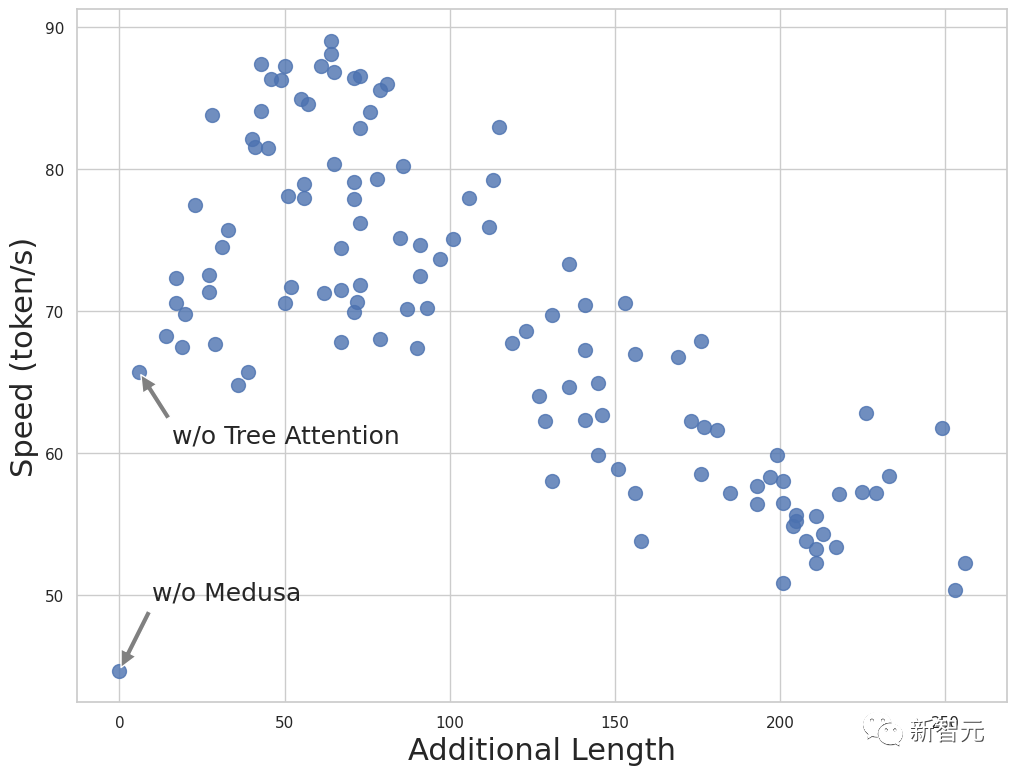
在利用美杜莎头的预测能力时,研究人员灵活地选择了每个头应考虑多少个顶级候选项。
例如可以选择第一个头的前3个预测和第二个头的前2个预测。当对这些顶级候选项进行笛卡尔积运算时,就生成了6个延续选项供模型评估。
这种可配置性,是需要进行权衡的。
一方面,选择更多的顶级预测会增加模型接受生成token的可能性。另一方面,它还会增加每个解码步骤的计算开销。
为了找到最佳平衡,研究人员尝试了各种配置,并确定了最有效的设置,如附图所示。
典型接受的阈值
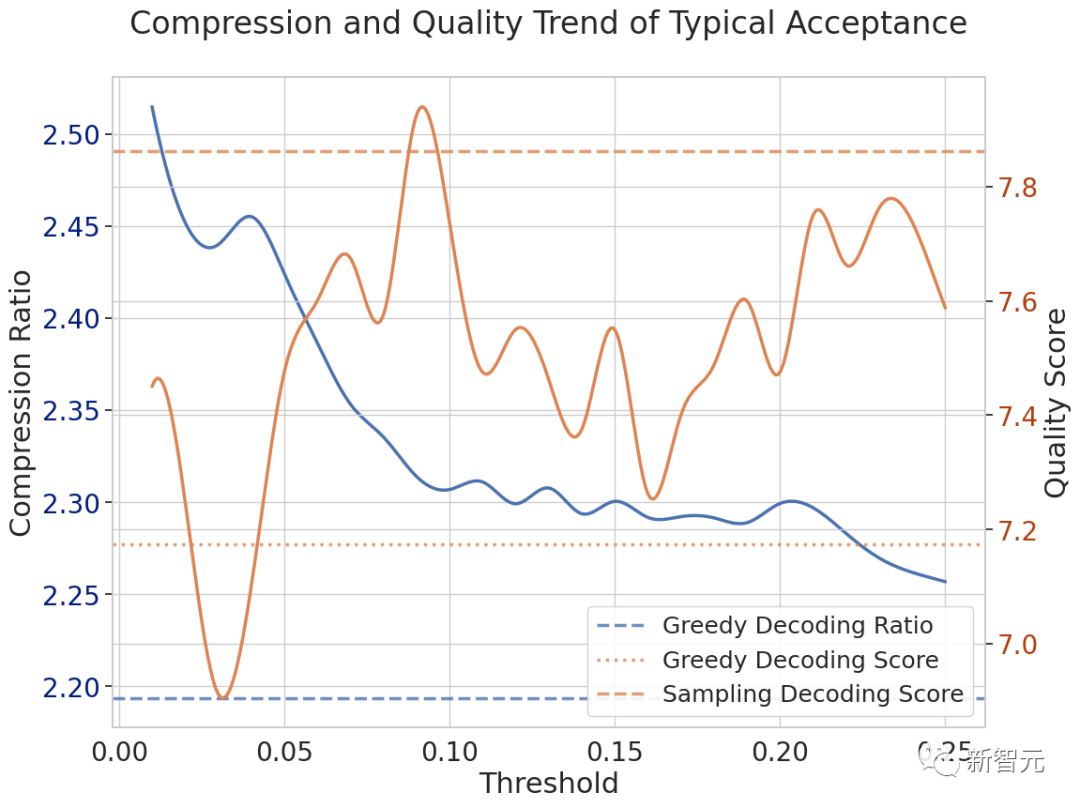
在典型接受方案中,一个关键的超参数,称为「阈值」,帮助研究人员根据模型自身的预测,来确定生成的token是否合理。
阈值越高,接受标准越严格,从而影响通过这种方法获得的整体加速。
研究人员通过在MT bench的2个以创造力为导向的任务上进行实验,来探讨质量和加速之间的这种权衡。
图中显示的结果表明,与贪心解码方法相比,典型接受能够加速10%。这种加速明显优于使用随机采样的投机解码方法,后者与贪心解码相比实际减慢了过程。
作者介绍

Tianle Cai(蔡天乐)
共同一作蔡天乐是普林斯顿大学的博士生,导师为Kai Li、Jason D. Lee。
就读博士期间,他在Xuezhi Wang和Denny Zhou指导下在Google DeepMind实习,还在Sébastien Bubeck和Debadeepta Dey的指导下在Microsoft Research完成了实习。
他曾在北大拿到了本科学位,主修应用数学,同时也主修计算机科学双学位,在Liwei Wang教授的指导下,开始了机器学习领域的研究。
蔡天乐的学术兴趣跨越了机器学习的广泛领域,包括优化、表征学习、架构设计(重点是Transfomer、图神经网络等),以及最近的系统架构协同设计。

Yuhong Li
共同一作Yuhong (Jesse) Li是伊利诺伊大学厄巴纳-香槟分校(UIUC)的ECE博士生,导师是Deming Chen教授。
此前,他在北京邮电大学获得了学士学位,兴趣是高效机器学习。

Zhengyang Geng(耿正阳)
Zhengyang Geng是卡内基梅隆大学(CMU)的计算机科学博士生,由J. Zico Kolter指导。
之前,他在北京大学做研究助理,由Zhouchen Lin指导。致力于识别和开发能够自组织复杂系统的结构。

Hongwu Peng
Hongwu Peng是康涅狄格大学计算机科学与工程系的博士生。
此前,他于2018年获得华中科技大学电气工程学士学位,于2020年获得阿肯色大学电气工程硕士学位。

Tri Dao
Tri Dao是生成式AI初创公司Together AI的首席科学家。2024年9月起,将出任普林斯顿大学计算机科学助理教授。
此前,他在斯坦福大学获得了计算机博士学位,导师是Christopher Ré和Stefano Ermon。
Tri Dao的研究兴趣在于机器学习和系统,重点关注:高效Transformer训练和推理;远程记忆的序列模型;紧凑型深度学习模型的结构化稀疏性。

项目鸣谢:Zhuohan Li,Shaojie Bai,Denny Zhou,Yanping Huang,stability.ai,together.ai,ChatGPT。



























