













本文经自动驾驶之心公众号授权转载,转载请联系出处。
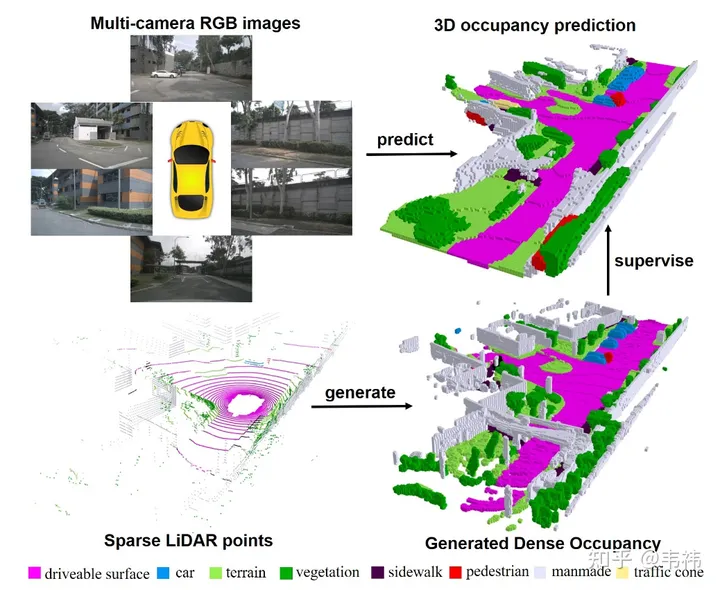
在这个工作中,我们通过多帧点云构建了稠密占据栅格数据集,并设计了基于transformer的2D-3D Unet结构的三维占据栅格网络。很荣幸地,我们的文章被ICCV 2023收录,目前项目代码已开源,欢迎大家试用。

arXiv:https://arxiv.org/pdf/2303.09551.pdf
Code:https://github.com/weiyithu/SurroundOcc
主页:https://weiyithu.github.io/SurroundOcc/
最近一直在疯狂找工作,没有闲下来写,正好最近提交了camera-ready,作为一个工作的收尾觉得还是写个知乎总结下。其实文章部分的介绍各个公众号写的已经很好了,也感谢他们的宣传,大家可以直接参考自动驾驶之心的自动驾驶之心:nuScenes SOTA!SurroundOcc:面向自动驾驶的纯视觉3D占据预测网络(清华&天大)。总的来说,contribution分为两块,一部分是如何利用多帧的lidar点云构建稠密occupancy数据集,另一部分是如何设计occupancy预测的网络。其实两部分的内容都比较直接易懂,大家有哪块不理解的也可以随时问我。那么这篇文章我想讲点论文之外的事情,一个是如何改进当前方案使其更加易于部署,另一个是未来的发展方向。
部署
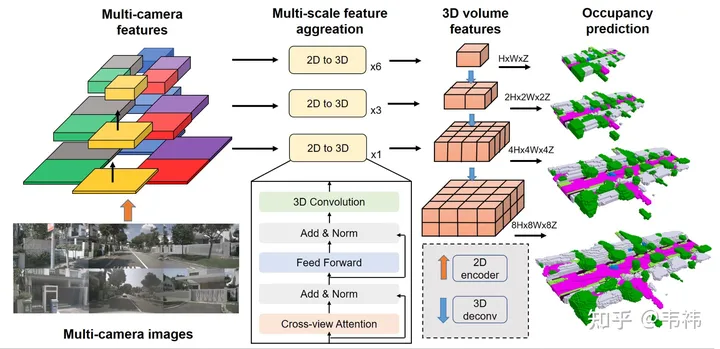
一个网络是否易于部署,主要看其中有没有比较难在板端实现的算子,SurroundOcc这个方法里比较难搞的两个算子是transformer层以及3D卷积。
transformer的主要作用是将2D feature转换到3D空间,那么其实这部分也可以用LSS,Homography甚至mlp来实现,所以可以根据已实现的方案去修改这部分的网络。但据我所知,transformer的方案在几个方案里对calibration不敏感并且性能也比较好,建议有能力实现transformer部署的还是利用原有方案。
对于3D卷积来说,可以将其替换成2D卷积,这里需要将原来 (C, H, W, Z) 的3D feature reshape成(C* Z, H, W)的 2D feature,然后就可以用2D卷积进行特征提取了,在最后occupancy预测那步再把它reshape回(C, H, W, Z),并进行监督。另一方面,skip connection由于分辨率比较大所以比较吃显存,部署的时候可以去掉只留最小分辨率那一层。我们实验发现3D卷积中的这两个操作在nuscenes上都会有些许掉点,但业界数据集规模要远大于nuscenes,有时候有些结论也会改变,掉点应该会少甚至不掉。
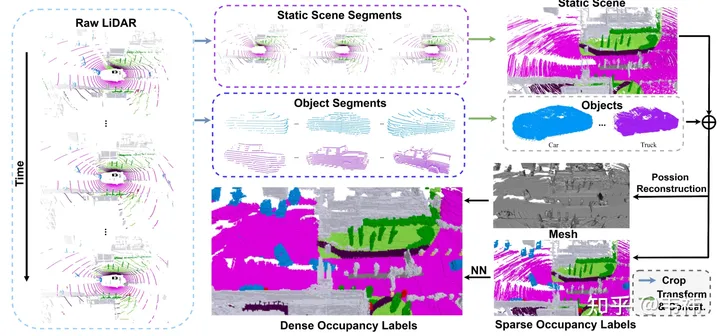
数据集构建方面,最耗时的一步是泊松重建那步。由于我们用的是nuscenes数据集,是用32线lidar采集的,即使利用了多帧拼接技术,我们发现拼接后的点云还是有很多的洞,所以我们利用泊松重建补洞。但其实现在业界用的许多lidar的点云都比较稠密,例如M1,RS128等,那么泊松重建这一步可以省略,将加速数据集构建这一步。
另一方面,SurroundOcc里是利用nuscenes中标注好的三维目标检测框将静态场景和动态物体分离的。但实际应用过程中,可以利用autolabel,也就是三维目标检测&跟踪大模型去得到每个物体在整个sequence中的检测框。相较于人工标注的label,利用大模型跑出来的结果肯定会存在一些误差,最直接的体现就是多帧的物体拼接后会有重影的现象。但其实occupancy对于物体形状的要求没有那么高,只要检测框位置比较准就能满足需求。
未来方向
当前方法还是比较依赖lidar提供occupancy的监督信号的,但很多车上,尤其是一些低阶辅助驾驶的车上没有lidar,这些车通过shadow模式可以传回来大量的RGB数据,那么一个未来方向是能不能只利用RGB进行自监督学习。一个自然的解决思路就是利用NeRF进行监督,具体来说,前面backbone部分不变,得到一个occupancy的预测,然后利用体素渲染得到每个相机视角下的RGB,和训练集中的真值RGB做loss形成监督信号。但很可惜的是这一套straightforward的方法我们试了试并不是很work,可能的原因是室外场景range太大,nerf可能hold不住,但也可能我们没有调好,大家也可以再试试。
另一个方向是时序&occupancy flow。其实occupancy flow对于下游任务的用处远比单帧occupancy大。ICCV的时候没来得及整occupancy flow的数据集,而且发paper的话还要对比很多flow的baseline,所以当时就没搞这块。时序网络可以参考BEVFormer和BEVDet4D的方案,比较简单有效。难的地方还是flow数据集这一部分,一般的物体可以用sequence的三维目标检测框算出来,但异型物体例如小动物塑料袋等,可能需要借助场景流的方法进行标注。

原文链接:https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug





















