人们很容易就能在反直觉视频(幽默的、创意的、充满视觉效果的视频)中获得愉悦感,这吸引力不仅来自于视频对人类的视觉感官刺激,更来自于人类与生俱来的理解和发现快乐的能力,即能够理解并在出乎意料和反直觉的时刻找到乐趣。
然而,尽管今天的计算机视觉模型取得了重大进步,但问题仍然存在:视频模型能够「理解」视频中的幽默或创造力吗?
目前的视频问答(VideoQA)数据集仍集中于常见的、不太令人惊讶的视频和简单的任务(如Multi-choice, Open-end)。
仅仅回答出视频中简单的人事物(What, Who, How many, etc.)显然是不足以为理解视频提供帮助的。常用的视频问答数据集包括YouCook2(其中包含2K烹饪视频)及Howto100m(其中仅包含教学视频)。
部分数据集(如UR-FUNNY等)引入了电视节目中的幽默片段,并设置了预测笑声轨迹等任务,但这些任务往往严重依赖音频和叙事线索,视觉线索无法起到太大的作用。
为了解决这一差距并评估计算机视觉模型理解反直觉视频的能力,来自北京邮电大学、新加坡南洋理工大学及艾伦人工智能研究所的学者们提出了FunQA——一个全面的高质量视频问答数据集,由4.3K个有趣的视频和312K个人工注释的自由文本问答对组成。

论文地址:https://arxiv.org/abs/2306.14899
FunQA数据集包括三个子集:HumorQA、CreativeQA和MagicQA。每个子集涵盖不同的来源和视频内容,但共性在于视频令人惊讶的特性,例如,幽默视频中出人意料的对比,创意视频中耐人寻味的伪装,以及魔术视频中看似不可能的表演。
在FunQA中,研究者还制定了三个严格的任务以衡量模型对反直觉视频的理解。
这些任务使视频推理超越了肤浅的描述,要求模型具有更深入的理解和洞察能力。具体任务包括:
1)反直觉的时间戳定位:此任务要求模型确定视频中意外事件发生的具体时间段;
2)详细的视频描述:模型必须生成连贯、客观的视频内容描述,以展示其基本视频理解能力;
3)反直觉推理:模型必须对视频令人惊讶的原因做出具体解释。这需要对视频中的反直觉事件进行深度推理。
这些任务逐步评估模型对视频中出现的反直觉元素的感知、表达和推理能力。
此外,研究者还提出了更具挑战性的辅助任务,包括为视频起一个合适而生动的标题等。
下图为FunQA三个子集的Demo,展示了FunQA针对不同视频类型设计的问答对。

FUNQA数据集
在构建数据集时,研究者坚持三个原则来解决视频理解能力的挑战,即以视觉为中心,强调反直觉推理能力,及强调时空推理能力。
基于这些原则,FunQA包括来自3种不同艺术流派的4,365个视频和311,950个问答对。这些视频的总长度为23.9小时,视频段的平均长度为19秒。
FunQA数据集包括三个子集:HumorQA、CreativeQA和MagicQA。数据集具体统计数据见图2。

从统计数据图2(h)中可以看到三种不同类型视频的时间戳热图,它显示了答案的高频时间跨度。
从图2(h)中可以发现,对于描述和推理任务,其自由文本答案的平均长度达到了34.24,很大程度超越现有的VideoQA数据集(如Activity-QA中的8.7及NExT-QA中的11.6)。
FunQA标注一致性评估结果如图2(i)所示,对于每个视频类别,超过90%的注释表现出高度的一致性,只有1%的内容表现出低一致性。大约8%的数据显示了共识的变化,显示了FunQA数据集的客观性。
FunQA与其他现有基准的比较
与其他基准相比,FunQA关注有趣和反直觉视频领域。FunQA中的任务专为挑战模型的视觉能力而设计,需要深入描述、解释和时空推理能力。下表详细展示了FunQA与其他基准的对比。
通常,一个基准上的性能趋势可能与另一个基准上的性能趋势相似,例如VQA和MSCOCO之间值得注意的相关性。
然而相比于其他数据集,FunQA数据集不仅提供了新领域的评估,而且以其他数据集可能没有的方式为模型提出挑战,其特点包括:
1)深度时空推理:FunQA侧重于反直觉的内容,要求模型先理解典型场景(常识),再辨别幽默偏差。这种类型的深度推理仍然是一个具有挑战性但尚未开发的领域。
2)丰富的注释:与许多依赖于多选题或开放式简短答案的数据集不同,FunQA拥有平均长度为34个单词的自由文本注释(在此之前,视频问答领域中注释最丰富的数据集是NExT-QA,平均单词长度为11.6)。这种详细的注释方法允许更丰富的模型响应,并测试它们生成更细微的答案的能力。
3)探索幽默感:对幽默原则的细致理解可能对模型真正掌握一些视频的内容至关重要。(之前没有视频问答数据集关注这方面,仅有VisualQA领域出现了相关的新数据集如The New Yorker Caption Contest)。决定如何使用这些幽默信息装备模型,以及哪些其他类型的知识可能是「有价值的」,是令人兴奋的研究方向。
实验结果与结论
研究者在7个视频问答模型(分为基于caption的模型和基于instruction的模型)上进行测试,下表展示了主要实验结果。
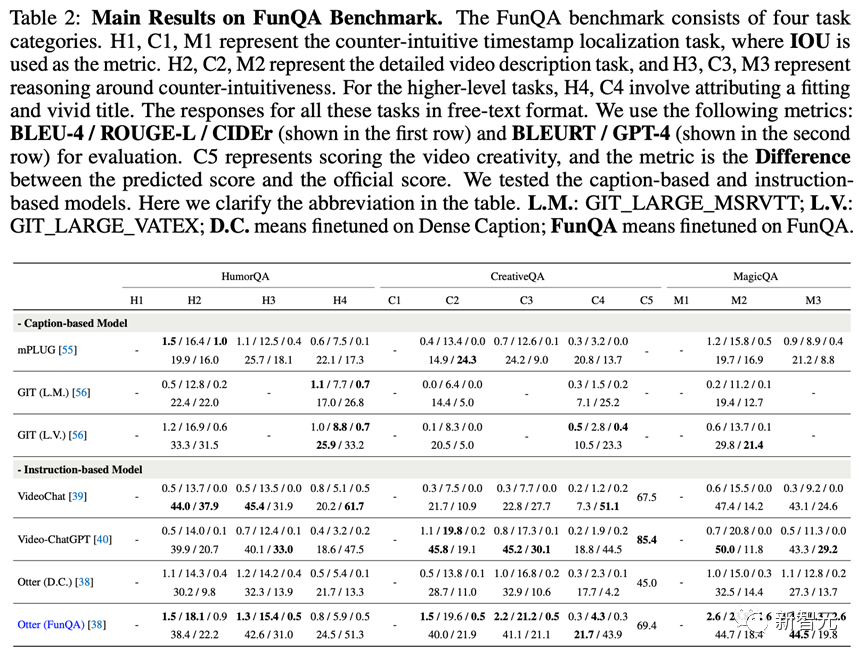
在FunQA基准中,H1、C1、M1分别代表三个子集上反直觉的时间戳定位任务,其中衡量指标为IOU。H2、C2、M2代表详细视频描述任务,H3、C3、M3代表反直觉推理任务。
对于更高层次的任务,H4、C4代表为视频起一个恰当而生动的标题。
所有这些任务的答案都是自由文本格式,由此研究者使用以下指标进行衡量:BLEU-4,ROUGE-L,CIDEr,BLEURT和GPT-4。
C5代表给创意视频的创造性打分,其评估方式是预测分数和官方分数之差。
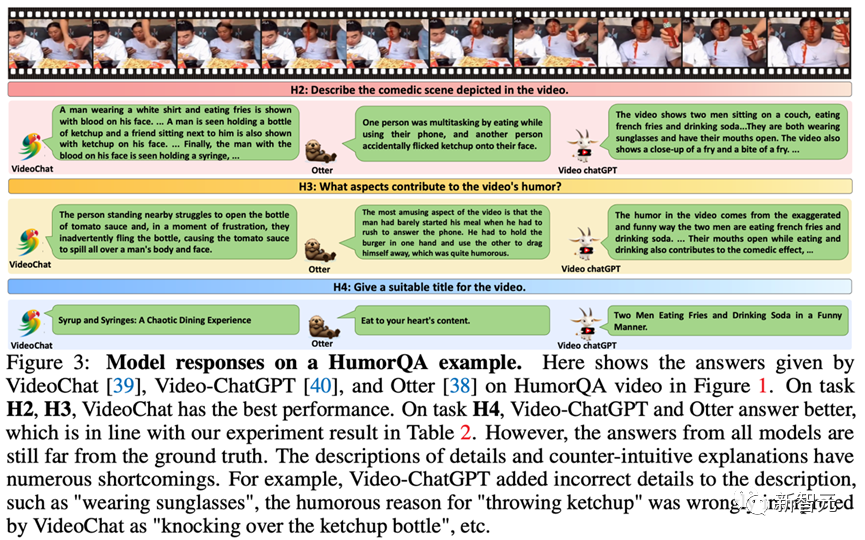
此外,研究者展示了不同模型对于FunQA的响应实例。
图3展示的是VideoChat、Video-ChatGPT和Otter在图中的幽默视频上给出的回复。在任务H2、H3上,VideoChat的表现最好。
在任务H4上,Video-ChatGPT和Otter回答得更好,这与表2中的实验结果一致。
然而,所有模型的答案仍然与正确答案有较大差距,尤其在细节的描述和反直觉的解释上有许多缺点。
总结
总体而言,模型在FunQA数据集上的性能普遍不令人满意。几个关键的发现包括:
1)时间戳定位任务是最具挑战性的。
基于caption的模型通常忽略时序信息,而基于instruction的模型,如Otter,只从特定的帧中获取视觉信息而不引入时序内容。因此,目前没有一个VLM可以解决H1、C1和M1的任务。
2)所有任务都没有明确的赢家。
基于caption的模型在提供详细描述方面表现出色,但在需要推理的任务中表现不佳,导致描述任务(如H2)和推理任务(如H3)之间存在显著的性能差距。
另一方面,基于instruction的模型表现出更强的推理能力,但在描述任务中表现不佳。一种可能的解释是:基于instruction的模型可能在它们的答案中包含过多冗余的信息,导致描述任务性能下降。
3)不同视频类型的性能差异很大。
大多数模型在幽默和魔术视频中可以得到相对准确的答案,但对于创意视频却很难回答问题。这可能是因为幽默和魔术视频通常描述模型以前遇到过的日常生活,而创意视频包含模型从未见过的内容,因此模型难以产生新的想法,导致不相关和错误的答案。
4)自由文本任务的评估指标不足。
传统的衡量标准在自由文本问题上的得分几乎为零,因为它们只关注基础的的文本相似性。研究者发现GPT-4在评估自由文本的深度理解方面显示出一定的能力。然而,仍然存在不稳定的问题,即相同的内容可以得到不同的分数。
5)微调后的Otter在传统指标上表现良好,但在GPT-4评分上落后。
研究者在Dense Caption和FunQA上对Otter进行了微调,Otter(FunQA)相对于Otter(D.C.)表现出了明显的性能优势。虽然与其他基于instruction的模型相比,Otter在ROUGE-L等传统指标上表现更好,但Otter的GPT-4分数表现不佳。
一个可能的原因是,Otter的输入只是从视频中采样的128帧,不足以进行综合推理。Otter在传统指标和GPT-4上的得分之间的差异与前文缺乏评估指标的发现相匹配。
讨论
前文提到,相比现有视频问答数据集,FunQA具有深度时空推理及探索幽默感等特点,由此也对模型提出了新的挑战:
1)准确理解信息和长视频:通过对失败案例的分析,研究者发现许多模型都难以准确地描述视频。虽然他们可能擅长检测视频中的物体,但他们在理解连续事件之间的上下文关系时往往会犹豫不决。这表明该领域有必要进一步探索,FunQA可以作为深入探索视频描述的宝贵数据集。
2)逻辑推理:FunQA数据集中视频的主要性质是包含违反直觉和与常识相矛盾的内容。为了让模型理解这些,它们必须掌握“常识”的概念,推断出在正常情况下通常会发生什么,然后用这种视角幽默地解读视频。这就要求模型具有较强的推理能力。如何在模型中注入常识性仍然是一个重要的研究点。
3)额外知识——幽默感:要想解读视频中的幽默,理解幽默的基本原理是至关重要的。这类知识以及其他常识和附加信息可能会增强模型的性能。因此,决定如何整合有价值的知识和辨别什么是“有价值的”是值得进一步探索的主题。
针对模型面临的挑战,研究者提出了一些可能的解决方案:
1)模型大小:增加参数的数量是提高模型性能的自然方法。然而,这种方法有其自身的工程挑战,需要在模型优化和部署方面进行改进。模型参数数量与其在FunQA基准上性能之间的关系值得进一步探索,FunQA数据集可以作为优秀测试平台。
2)数据质量:研究者认为这项任务的重点应该放在数据收集上。目前大型动态模型的趋势表明,拥有大量低质量数据远不如拥有少量高质量数据有效。因此,研究者希望社区能够发现真正有助于理解反直觉视频的数据类型。这是一个至关重要的研究方向。
3)训练策略:研究训练策略也很重要。例如,确定从哪种类型的数据开始学习,以及理解课程学习的意义等等。
4)模型协作:研究者认为,也许多个模型以一种优雅的方式协作处理示例可能是提高性能的一种方法。然而,这种方法可能需要更多地关注模型实现的整体效率。
目前工作的局限性:
1)当前FunQA数据集主要包括视频级别的数据和注释,但可以引入更深入的注释来探索视频推理的可能性,例如详细的空间和时间注释,即对应于特定时间轴的字幕和对象级别的注释。
2)原始注释由中文完成。在翻译成英文的过程中,研究者首先使用GPT对中文注释进行润色和补充,使文本尽可能完整。然而,由于两种语言之间的文化差异,注释间可能仍然存在分歧。
未来的工作
研究者希望用更深度、更多样的注释来扩展FunQA数据集。
此外,将探索新的指标以更好地评估模型的性能,特别是在缺乏深度指标的开放式问题中。
最后,研究者希望为模型向更深层次的视频推理发展提供方向。
基于FunQA的算法大赛
2023年7月,奖金100万美元的算法大赛FunQA Challenge正式开启报名。