人类直觉是一种常被 AI 研究者忽视的能力,但其精妙程度连我们自身也没有彻底理解。弗吉尼亚理工大学和微软的一个研究团队在近日的一篇论文中提出了思维算法(AoT),其组合了直觉能力与算法方法的条理性,从而能在保证 LLM 性能的同时极大节省成本。
大型语言模型近来发展速度很快,其在解决一般问题、生成代码和跟随指令方面表现出了显著的非凡能力。
尽管早期的模型依赖于直接回答策略,但当前的研究则转向了线性推理路径,其做法是将问题分解成子任务来发现解决方案,或通过修改上下文来利用外部机制来改变 token 的生成。
与人类认知类似,早期的 LLM 策略似乎模仿的是即时的 System 1(快速反应),其特征是通过脉冲决策实现。相较之下,思维链(CoT)和 least-to-most prompting(L2M)等更新的一些方法则反映了 System 2(慢速思考)的内省式本质。值得注意的是,通过整合中间推理步骤,可让 LLM 的算术推理能力获得提升。
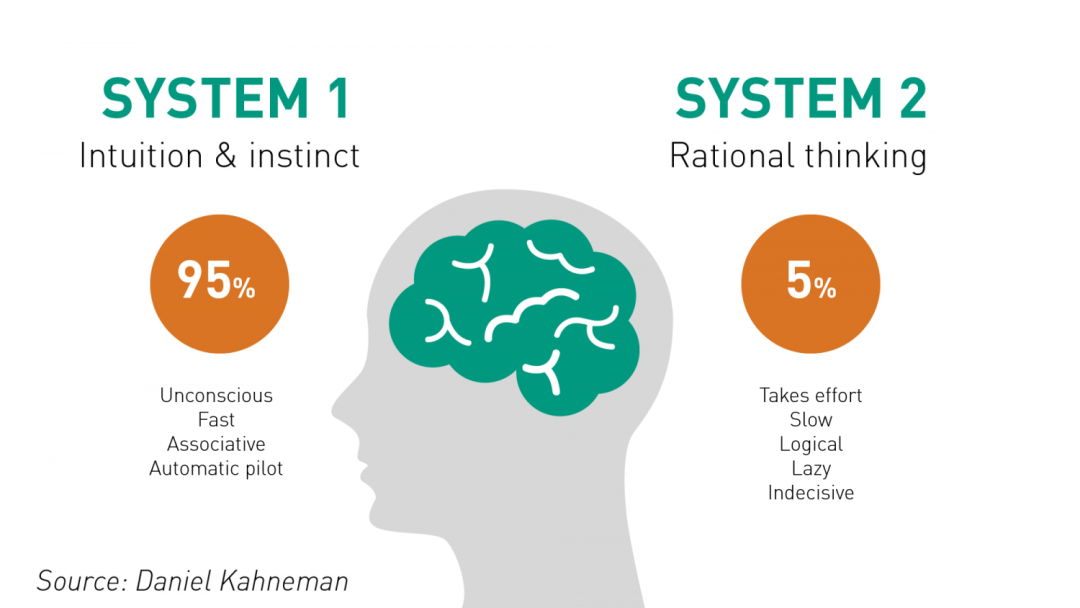
但是,如果任务需要更深度的规划和更广度的思维探索,那么这些的方法的局限性就显现出来了。尽管整合了自我一致性的 CoT(CoT-SC)可使用多个 LLM 输出来达成共识性结果,但由于缺少细致的评估,可能会导致模型走向错误方向。2023 年出现的思维树(ToT)是一种值得注意的解决方案。其中使用一个 LLM 来生成想法,再使用另一个 LLM 来评估这些想法的优点,之后续以「暂停 - 评估 - 继续」的循环。这种基于树搜索的迭代过程明显是有效的,尤其是对于具有较长延续性的任务。研究者认为,这种进展是使用外部工具来增强 LLM,类似于人类使用工具来规避自身工作记忆的限制。
另一方面,这种增强过的 LLM 方法也不是没有缺点。一个明显的缺点是查询数量和计算需求会大幅飙升。对 GPT-4 等在线 LLM API 的每一次查询都会产生可观的金钱开支,同时还会拉长延迟,这一局限对实时应用而言尤为关键。这些查询累积的延迟可能有损方案的整体效率。基础设施方面,持续的交互会给系统带来压力,这可能限制带宽和降低模型可用性。此外,还不能忽视对环境的影响,不断的查询会加大已经能耗很大的数据中心的能耗,使碳足迹进一步增大。
基于这些考量,研究者的优化目标是大幅减少当前多查询推理方法所使用的查询数量,同时维持足够的性能,使模型能应对需要熟练使用世界知识的任务,从而引导人们更负责任和更熟练地使用 AI 资源。
通过思考 LLM 从 System 1 到 System 2 的演变,可以看到一个关键因素浮出了水面:算法。算法是富有条理的,其能提供一条帮助人们探索问题空间、制定策略和构建解决方案的途径。尽管许多主流文献都将算法看作是 LLM 的外部工具,但考虑到 LLM 固有的生成式复现能力,我们能否引导这种迭代式逻辑来将一个算法内化到 LLM 内部?
弗吉尼亚理工大学和微软的一个研究团队将人类推理的复杂精妙和算法方法的富有条理的精确性聚合到了一起,试图通过融合这两方面来增强 LLM 内部的推理能力。
已有的研究强调,人类在解决复杂问题时会本能地借鉴过去的经历,确保自己进行全面思考而不是狭隘地关注某一细节。LLM 生成范围仅受其 token 限制限定,似乎是注定要突破人类工作记忆的阻碍。
受这一观察启发,研究者探究了 LLM 能否实现类似的对想法的分层探索,通过参考之前的中间步骤来筛除不可行的选项 —— 所有这些都在 LLM 的生成周期内完成。而人类长于直觉敏锐,算法善于组织化和系统性的探索。CoT 等当前技术往往回避了这种协同性潜力,而过于关注 LLM 的现场精度。通过利用 LLM 的递归能力,研究者构建了一种人类 - 算法混合方法。其实现方式是通过使用算法示例,这些示例能体现探索的本质 —— 从最初的候选项到经过验证的解决方案。
基于这些观察,研究者提出了思维算法(Algorithm of Thoughts /AoT)。

论文:https://arxiv.org/pdf/2308.10379.pdf

从更广义的范围看,这种新方法有望催生出一种上下文学习新范式。这种新方法没有使用传统的监督学习模式,即 [问题,解答] 或 [问题,用于获得解答的后续步骤],而是采用了一种新模式 [问题,搜索过程,解答]。很自然,当通过指令让 LLM 使用某算法时,我们通常预计 LLM 只会简单模仿该算法的迭代式思维。但是,有趣的是 LLM 有能力注入其自身的「直觉」,甚至能使其搜索效率超过该算法本身。
思维算法
研究者表示,其研究策略的核心是认识到当前上下文学习范式的核心短板。CoT 尽管能提升思维联系的一致性,但偶尔也会出问题,给出错误的中间步骤。
为了说明这一现象,研究者设计了一个实验。用算术任务(如 11 − 2 =)查询 text-davinci-003 时,研究者会在前面添加多个会得到同等输出结果的上下文等式(如 15 − 5 = 10, 8 + 2 = 10)。
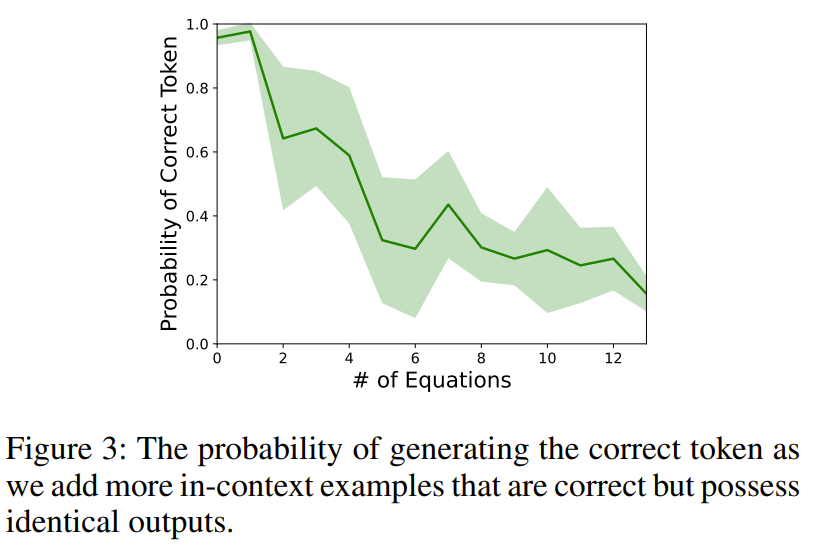
结果发现,准确度陡然下降,这说明只是在上下文中给出正确的推理可能会在无意中损害 LLM 的基础算术能力。
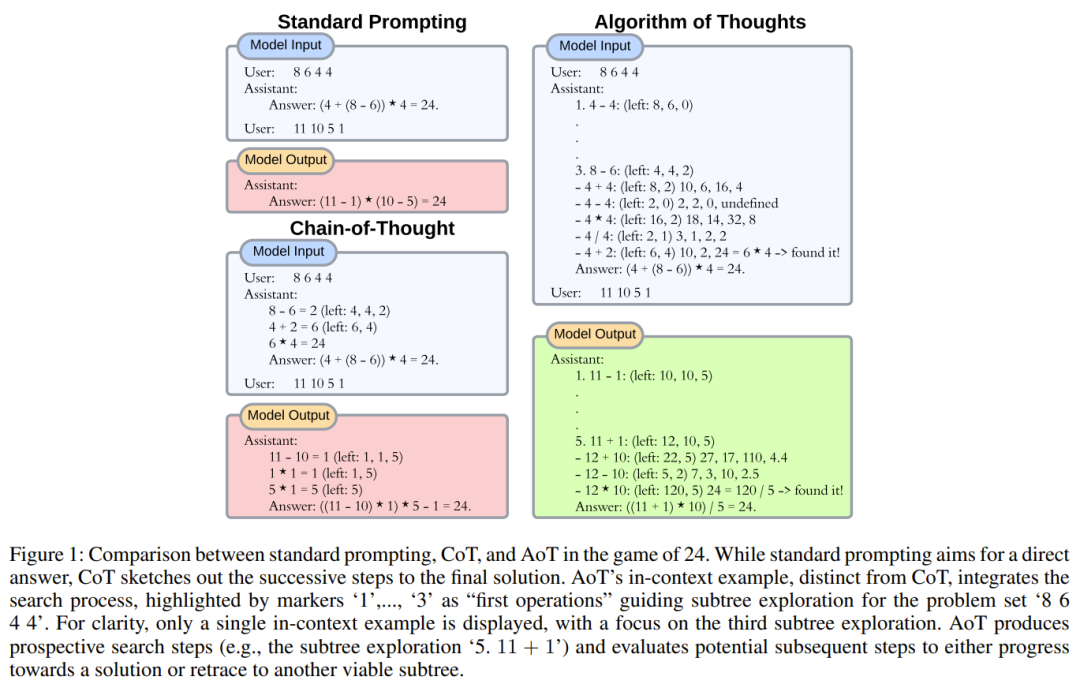
为了减少这种偏差,让示例更加多样化也许是可行的解决方案,但这可能会稍微改变输出的分布。只是添加一些不成功的尝试(就像是随机搜索),可能会无意地鼓励模型重新尝试,而不是真正解决问题。了解了算法行为的真正本质(其中失败的搜索和后续的恢复以及对这些尝试的学习都很重要),研究者整合上下文示例的方式是按照搜索算法的模式,尤其是深度优先搜索(DFS)和广度优先搜索(BFS)。图 1 给出了一个示例。
这篇论文关注的重点是与树搜索问题类似的一大类任务。
这类任务必需对主要问题进行分解,为每一部分构建可行的解决方案,并决定采纳或放弃某些路径,并可以选择重新评估更有潜力的部分。
研究者的做法不是为每个子集都给出单独的查询,而是利用了 LLM 的迭代能力,在一次统一的生成式扫描中解决它们。通过限定自己仅能进行一两次 LLM 交互,该方法可以自然地整合来自之前的上下文候选项的洞见,并解决需要对解答域进行深度探索的复杂问题。对于这些思维的大小应当如何以及应该为 LLM 提供何种类型的上下文示例,从而提升 token 效率,研究者也给出了自己的见解。下面将给出树搜索算法的关键组件以及它们在新框架中的表现形式。
1. 分解成子问题。给定一个问题,就算不看实际解决问题方面,构建一个描述可行推理路径的搜索树已经是一项艰巨的任务。任何分解都不仅要考虑子任务之间的相互关系,还要考虑解决各个问题的难易程度。
以简单的多位数加法为例:尽管对计算机而言,将数值转换成二进制数后效率很高,但人类通常认为十进制数更加直观。此外,即便子问题是一样的,执行方法也可能不同。直觉能找到解答步骤之间的捷径,而如果没有直觉,可能就必需更为详细的步骤。
为了创建出正确的 prompt(即上下文算法示例),这些细微之处非常重要,它们决定了 LLM 为了取得可靠表现所需的最少 token 数量。这不仅能满足 LLM 对上下文的限制,而也对 LLM 的能力很重要,因为我们希望 LLM 能使用相似的 token 量解决与其上下文有共鸣的问题。
2. 为子问题提议解答。现目前的一种主流方法涉及到直接采样 LLM token 输出概率。尽管这种方法对一次性答案有效(有一定的限制),但也无力应对一些场景,比如当需要将样本序列整合进后续 prompt 中或在后续 prompt 中评估时。为了尽可能减少模型查询,研究者采用了一种不间断的解答创建过程。即不带任何生成停顿,为主要子问题直接和连续地生成解答。
这个方法存在诸多好处。第一,所有生成的解答都在同一个共享的上下文中,无需为评估每个解答生成单独的模型查询。第二,尽管一开始看起来挺反直觉,但孤立的 token 或 token 分组概率可能并不总能得到有意义的选择。图 4 给出了一个简单的示意图。

3. 衡量子问题的前景。如上所述,现有技术依靠额外的提示来识别树节点的潜力,帮助做出有关探索方向的决策。而研究者的观察表明,如果能将最有前途的路径封装在上下文示例中,LLM 会固有地倾向于优先考虑那些有前途的候选项。这能降低对复杂 prompt 工程设计的需求并允许整合复杂精细的启发式方法,不管这些方法是直觉式的或知识驱动的。同样,新方法中不含脱节的 prompt,这使得能在同一个生成结果中即时评估候选项的可行性。
4. 回溯到更好的节点。决定接下来要探索的节点(包括回溯到之前的节点)本质上取决于所选的树搜索算法。尽管之前已有研究为搜索过程采用了编码机制等外部方法,但这会限制其更广泛的吸引力并需要额外的定制。这篇论文提出的新设计主要采用 DFS 方法并辅以剪枝。目标是维持有同一父节点的子节点之间的近邻度,以此鼓励 LLM 优先考虑本地特征而不是远程特征。此外,研究者还提出了基于 BFS 的 AoT 方法的性能指标。研究者表示,借助于模型从上下文示例中收集见解的固有能力,可以消除额外的定制机制的必要性。
实验
研究者在 24 点和 5x5 迷你填词游戏上进行了实验,结果表明了 AoT 方法的优越性 —— 其性能表现由于单 prompt 方法(如标准方法、CoT、CoT-SC),同时也能媲美利用外部机制的方法(如 ToT)。
从表 1 可以明显看出,结合了 CoT/CoT-SC 的标准 prompt 设计方法明显落后于通过 LLM 使用的树搜索方法。
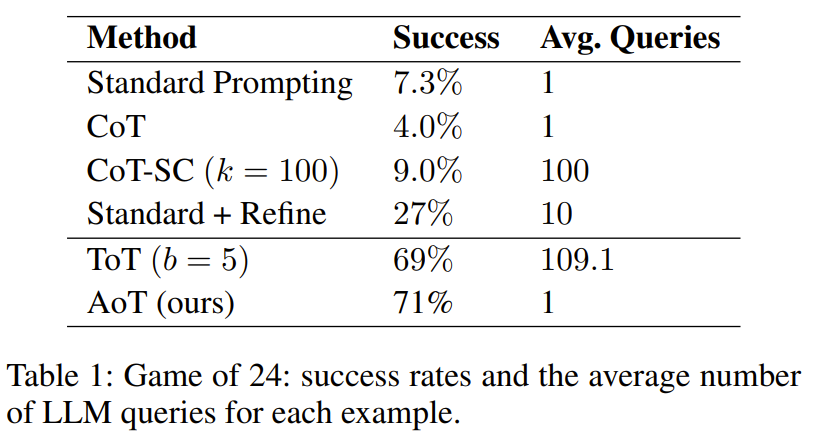
表 3 凸显了 AoT 在迷你填词任务上的有效性,其填词成功率超过之前使用各种 prompt 技术的方法。

但是,它比 ToT 差。一个重要的观察是 ToT 使用的查询量巨大,超过了 AoT 百倍以上。另一个让 AoT 逊于 ToT 的因素是算法示例中固有的回溯能力没有充分得到激活。如果能完全解锁该能力,会导致生成阶段显著延长。相比之下,ToT 的优势在于可以利用外部记忆来进行回溯。
讨论
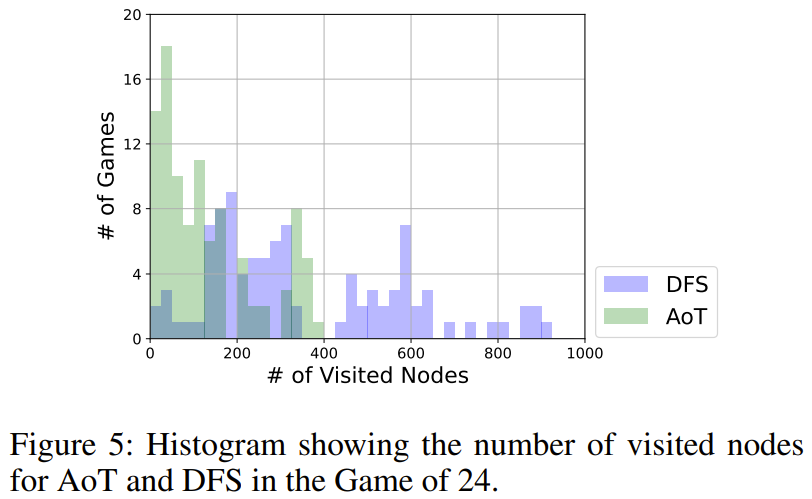
AoT 能否超越它模仿的 DFS?
如图 5 所示,AoT 所使用的节点整体上比 DFS 版本更少。DFS 在选择后续要探究的子树时采用了一种统一的策略,而 AoT 的 LLM 则集成了其固有的启发式方法。这种对基本算法的放大体现了 LLM 递归推理能力的优势。
算法的选择会如何影响 AoT 的效能?
表 5 给出了实验发现,可以看到这三种 AoT 变体都优于单查询的 CoT。
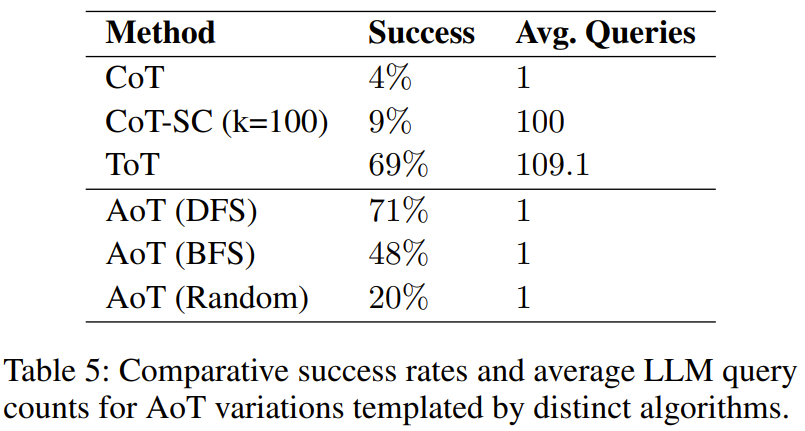
这一结果符合预期,因为无论算法是什么,它都会进行搜索并重新审视潜在的错误 —— 要么是通过随机搜索变体中的随机尝试,要么是通过 DFS 或 BFS 配置中的回溯。值得注意的是,AoT (DFS) 和 AoT (BFS) 这两个结构化搜索的版本的效率都优于 AoT (Random),这突显了算法洞察在解答发现中的优势。但是,AoT (BFS) 落后于 AoT (DFS)。通过更进一步分析 AoT (BFS) 的错误,研究者发现,相比于 AoT (DFS),AoT (BFS) 更难识别最佳操作。
那么,算法示例中的搜索步数怎么调节 AoT 的行为?
图 6 给出了总搜索步数的影响。其中 AoT (Long) 和 AoT (Short) 分别是相对于原始 AoT 的生成结果更长和更短的版本。
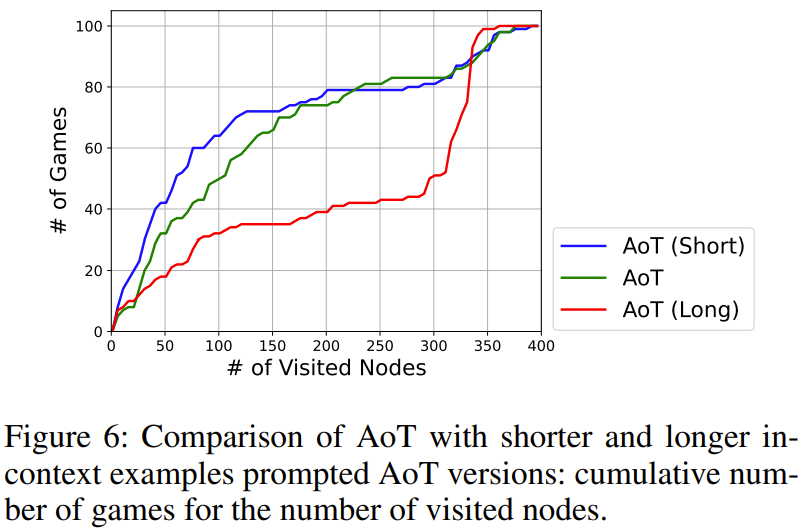
结果表明,搜索步数会为 LLM 的搜索速度引入隐含的偏差。值得注意的是,即使在采取错误的步骤时,强调探索有潜力的方向是很重要的。