













本文经自动驾驶之心公众号授权转载,转载请联系出处。
我们提出了一种基于点云柱坐标三视角表示的高效3D语义占有预测方法PointOcc,通过在nuScenes公开数据集上进行大量实验,验证了PointOcc在3D语义占有预测和点云分割任务上可以取得最佳的性能,同时大幅降低计算量。PointOcc仅使用点云数据作为输入,在mIoU和IoU两种指标上大幅超越了OpenOccupancy benchmark中的多模态方法。

论文:https://arxiv.org/abs/2308.16896
代码:https://github.com/wzzheng/PointOcc
1. 提出的背景
当前自动驾驶领域中的语义分割正在经历从稀疏的点云分割到密集的3D语义占有预测的变革。3D语义占有预测任务的目标是对3D空间中的每一个体素都预测一个语义标签,以实现对3D场景更加鲁棒、准确的感知建模。但由于其密集的预测空间,当前基于点云体素表示的方法将承受巨大的计算和存储负担,从而严重限制模型的性能。另一类更加高效的点云表示是基于2D投影表示的方法,例如BEV和range-view表示。尽管相比于体素表示更加高效,但由于其在投影过程中的信息损失,仅使用单平面特征难以建模复杂3D场景中的细粒度结构,从而无法处理具有密集预测空间的3D语义占有预测任务。
为了解决这个问题,我们提出了一种新的基于柱坐标三视角的点云表示来高效、完整地建模3D场景,并进一步提出了一个高效的3D语义占有预测模型PointOcc。我们采用彼此互补的三视角平面来高效建模点云特征,并使用高效的2D backbone处理。我们提出柱坐标划分和空间分组池化来减少投影过程中的信息损失,在保持高效的同时进一步提升模型建模复杂3D场景的能力。实验表明,我们的模型PointOcc在点云分割任务中达到了基于2D投影表示方法中的最佳性能,而无需复杂的后处理操作;并在3D语义占有预测任务上取得了比OpenOccupancy benchmark上多模态方法更好的性能,同时大幅降低模型的计算和存储负担。
2. 我们的方法
本文提出了一种新的基于柱坐标三视角的点云表示方法,通过彼此互补的三个2D平面来共同建模3D空间特征。我们仅采用2D backbone来高效处理三视角平面特征,并通过柱坐标划分和空间分组池化来减少投影过程中的信息损失。最后通过聚合三平面中彼此互补的特征视角下的特征,实现对3D空间高效细致的建模。
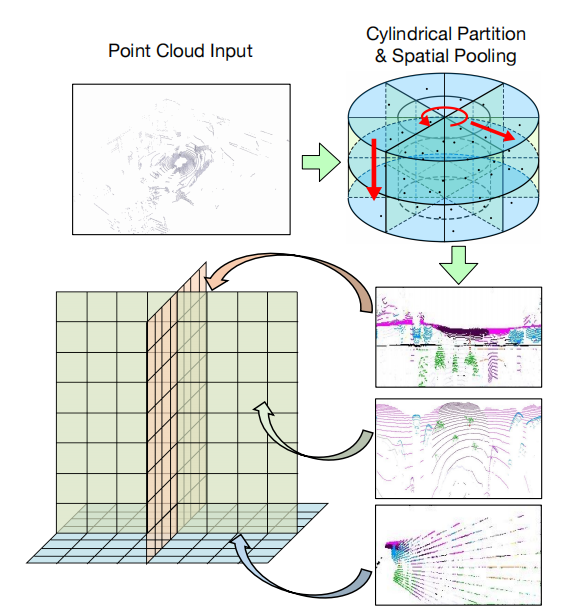
2.1 点云的柱坐标三视角表示
在基于点云的自动驾驶感知中,一个重要问题是学习到有效且高效的3D场景表示。而在当前的主流方法中,3D体素表示会造成巨大的计算和存储负担,2D投影表示会由于信息损失而无法恢复出密集的3D空间特征。为了实现在2D平面高效处理点云特征并保留3D结构信息,我们将Tri-Perspective View (TPV)的思想引入点云,采用三视角下的平面特征来建模3D场景。每个平面负责建模特定视角下的3D场景特征,三个平面彼此正交互补,通过聚合三平面的特征就能恢复出3D空间中任意一点的结构信息。考虑到激光雷达点云在空间中分布的不均匀特性,即近处的点云更加密集而远处更加稀疏,我们进一步提出在柱坐标系下建立点云的三视角表示,以实现对近处区域更加细粒度的建模,并在投影过程中采用空间分组池化来更好地保留3D结构信息。
2.2 PointOcc
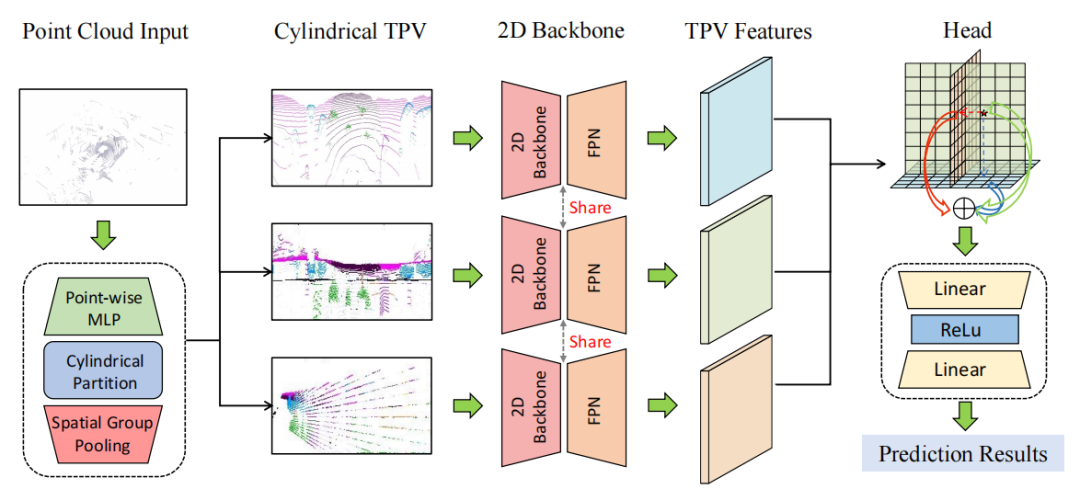
基于点云的柱坐标三视角表示,我们提出了一个高效的3D语义占有预测模型PointOcc,仅利用2D backbone实现模型在性能和效率上的最佳表现。PointOcc主要分为三个模块:点云的三视角转化、三视角特征编码、重构3D空间特征
- 点云的三视角转化:给定输入点云,首先需要通过体素化(voxelization)和空间池化操作(spatial max pooling)其转化为三个视角下的平面特征。考虑到激光雷达点云在空间中的分布密度不一致性,采用直角坐标系下均匀的方格划分会导致体素中点云密度分布极不均匀,近处点云极度密集而远处存在大量空体素,造成计算效率下降。因此我们采用柱坐标系下的体素划分,由于柱坐标系中对近处划分更加密集而远处更加稀疏,从而使点云密度分布更加均匀。对点云进行体素划分后,我们沿柱坐标系下的三个坐标轴分别进行分组池化+特征联结,得到点云在柱坐标下的三视角特征。
- 三视角特征编码:我们采用2D图像backbone来编码每个三视角特征平面,并由FPN聚集每个平面的多尺度特征,最终解码出高分辨率的三视角特征表示。由于仅在2D空间中进行特征的表示和编码,我们的模型在计算和存储上具有高效性。
- 重构3D空间特征:基于点云的三视角特征平面,我们可以高效完整地重构出3D空间的特征表示。对于3D空间中的任意一个查询点,我们首先通过柱坐标转换将其分别投影到三视角平面上并采样相应特征。我们通过相加的方式聚合该点在三视角平面上的特征,并作为最终的3D特征表示。在进行点云分割和3D语义占有预测时,只需要查询相应点的三视角特征,并由轻量级的分类头进行预测。
3. 实验
3.1 3D语义占有预测实验结果
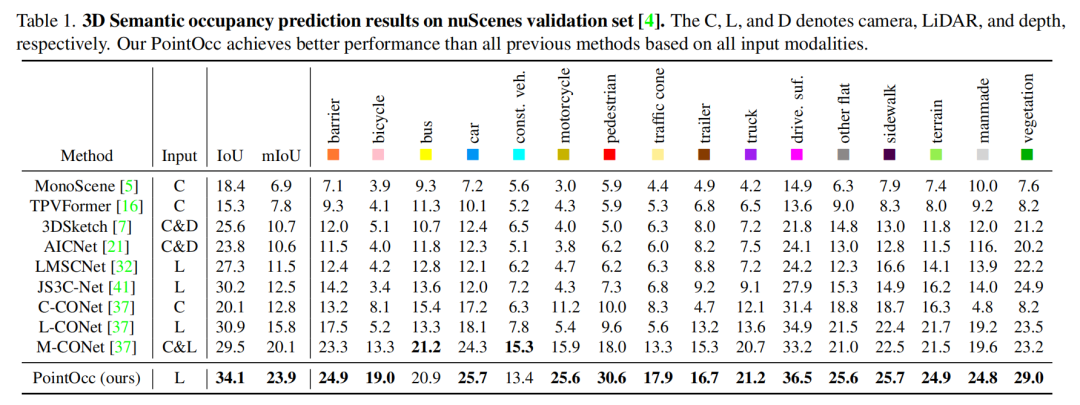
如下表所示,本文方法在nuScenes 3D语义占有预测任务中在mIoU和IoU两项指标上都达到了最佳性能。本文方法仅使用点云输入,就在性能上大幅超越了OpenOccupancy中的多模态方法,显示了PointOcc方法的优越性。
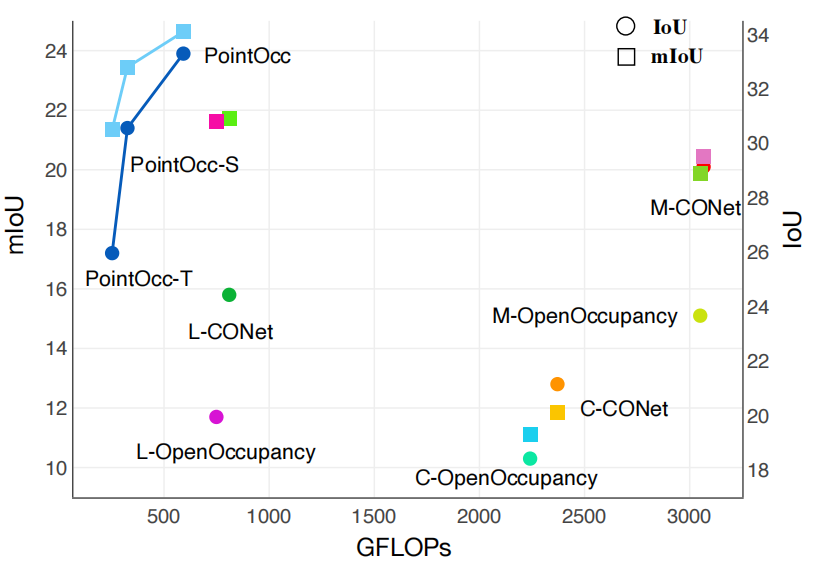
我们进一步比较了PointOcc与其他方法在性能和计算量上的综合表现。如下图所示,PointOcc在保持优越性能的同时大幅降低了模型的计算量,显示了本文方法在处理密集预测任务时具有高效建模复杂3D场景的能力。
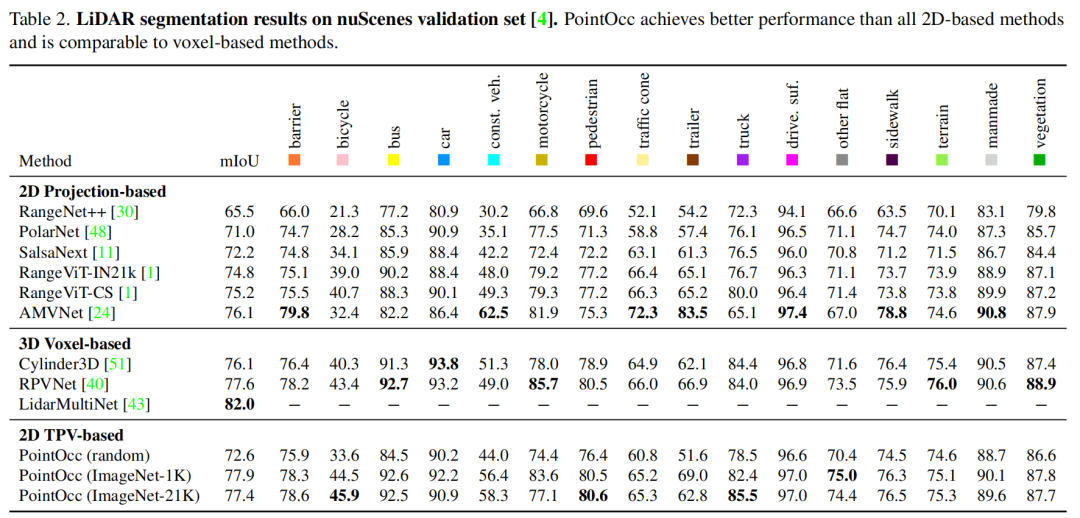
3.2 点云分割实验结果
我们同样在nuScenes点云分割任务上验证本文方法的有效性。如下图所示,本文方法在性能上超越了所有基于2D投影表示的方法而不需要任何后处理操作,并达到了与基于3D体素表示方法相当的性能。此外,我们验证了2D图像backbone在图像数据上预训练后,能够提升其在点云感知任务上的性能。
3.3 消融实验
我们在nuScenes点云分割任务上进行消融实验,首先验证三视角平面彼此互补的特性。如下表所示,相比于单平面特征,同时利用三个平面来共同建模3D场景时能够获得更大的性能提升。

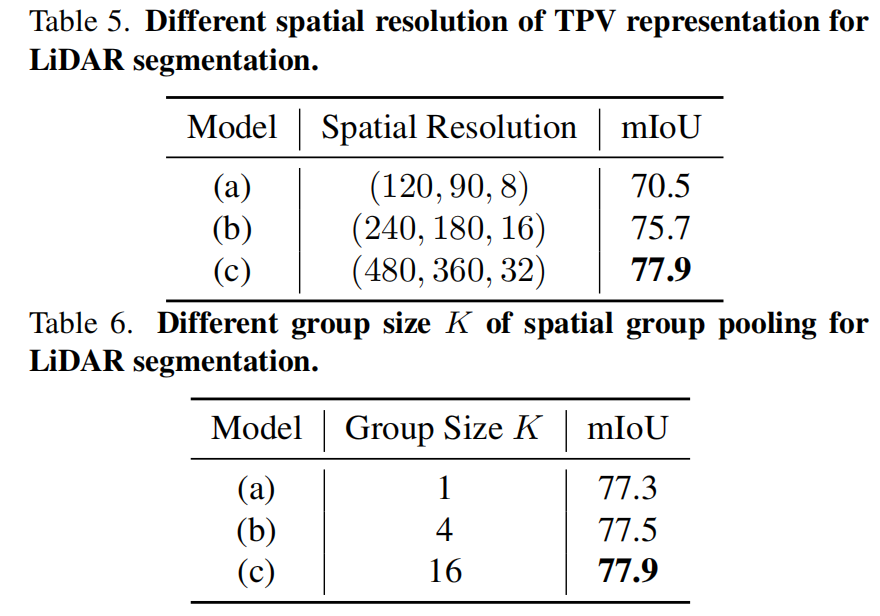
我们还验证了三视角表示的分辨率和空间分组池化的分组数对模型性能的影响。如下表所示,当三视角表示分辨率越高、空间池化分组越多时,模型的性能越高。这也证明了对3D场景进行更细粒度的建模能够有效提升模型的性能。
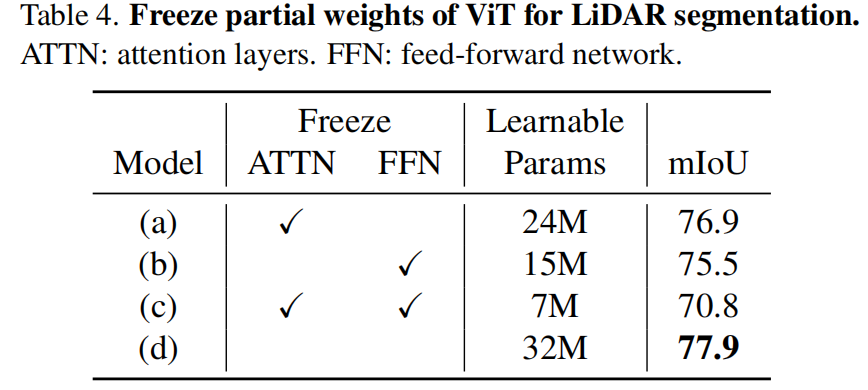
考虑到ViT模型在从图像迁移到点云数据时展现出惊人的性能,我们进一步探索了将在ImageNet上预训练的ViT中部分权重冻结时对模型性能的影响。如下表所示,当仅冻结注意力层或FFN层时模型性能并没有大幅下降,显示了在图像数据上预训练的ViT模型可以很好地泛化到点云感知任务上。
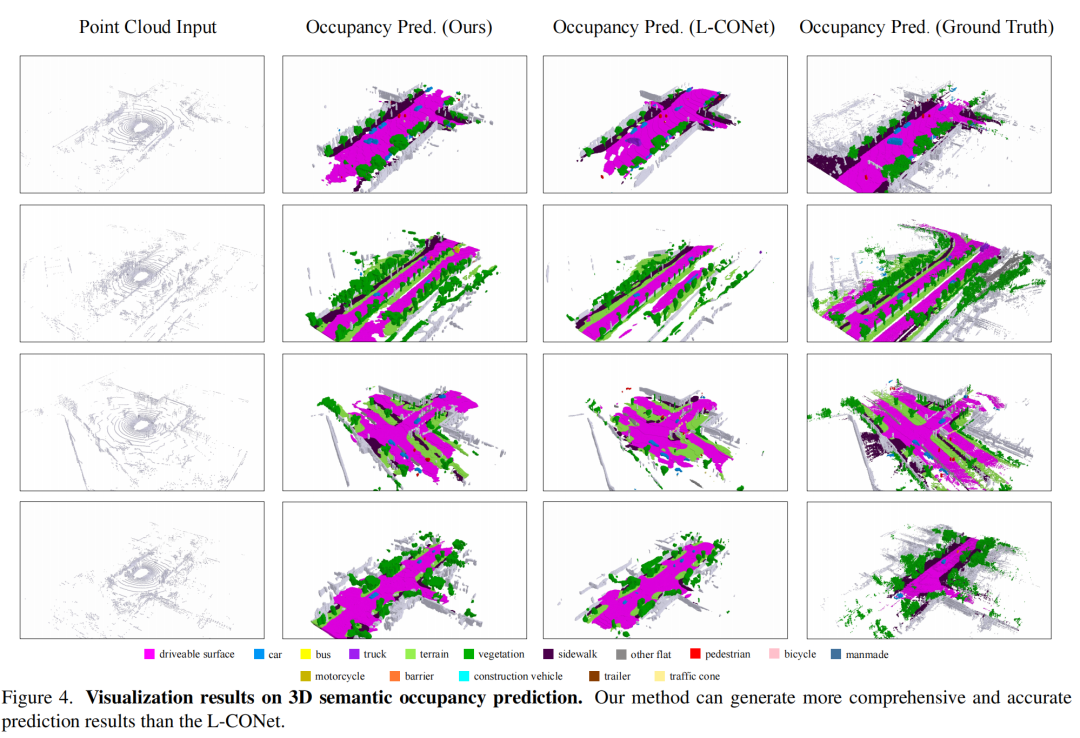
3.4 可视化结果
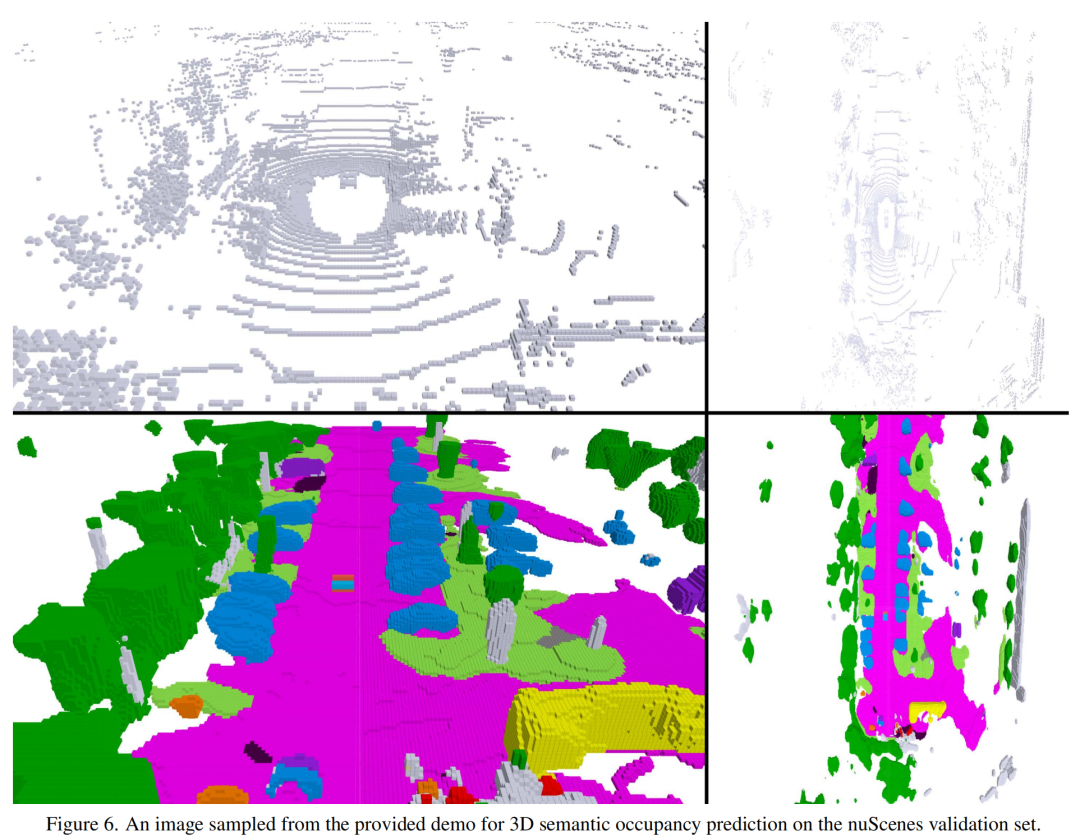

原文链接:https://mp.weixin.qq.com/s/7l-hG-y3o51dBzKbNlVJeA























