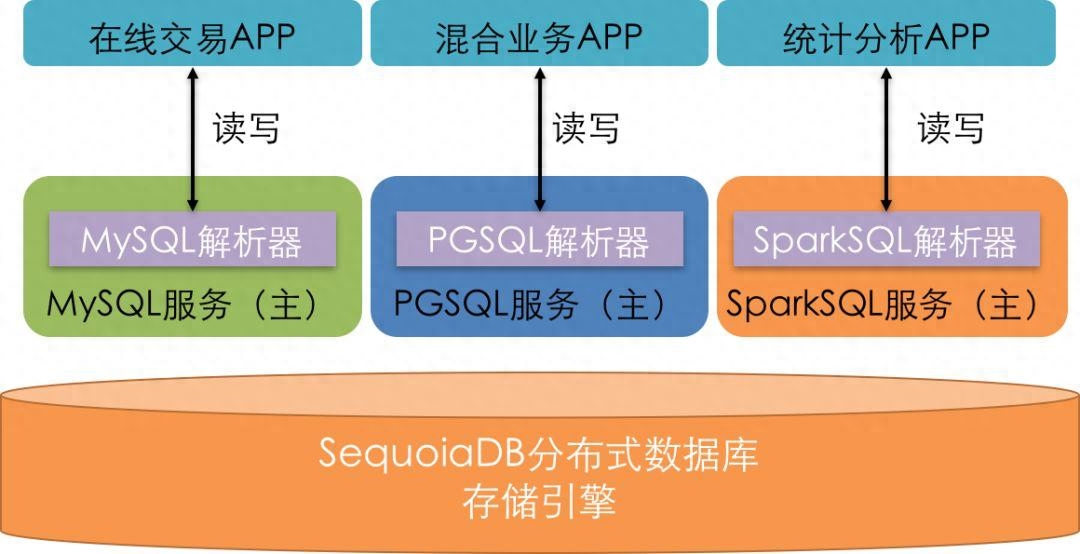
在数字化时代,数据规模不断增长,许多企业面临着存储和管理海量数据的挑战。分布式数据库成为了解决这一问题的重要工具,它可以有效地管理和存储大规模的数据,支持高可用性和扩展性的需求。
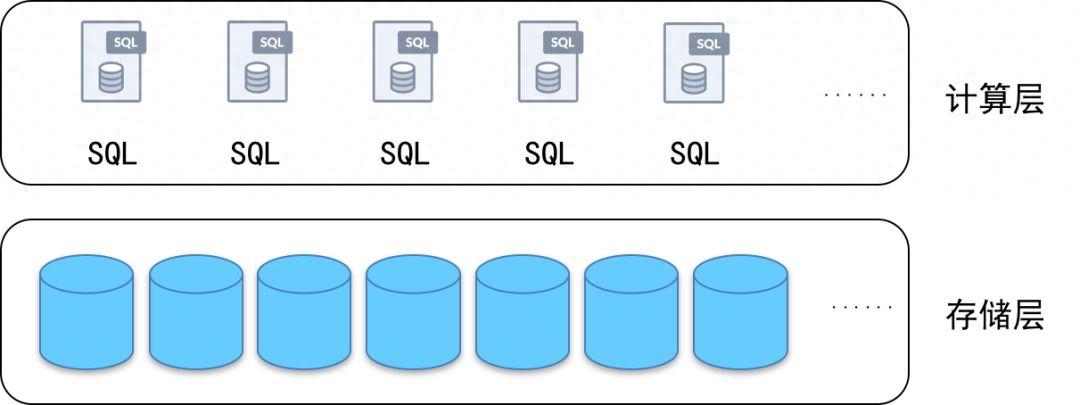
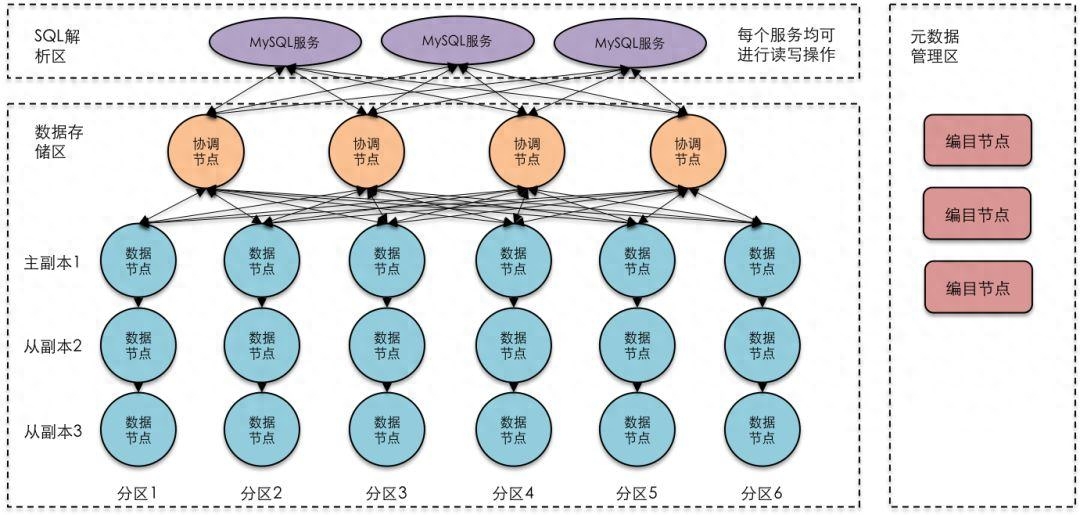
什么是分布式数据库?
分布式数据库是一种数据库系统,将数据存储在多个物理节点上,通过分布式计算和存储技术来实现数据的管理。相比传统的单机数据库,分布式数据库具有更高的可扩展性和容错性,能够处理大规模的数据和高并发的访问请求。
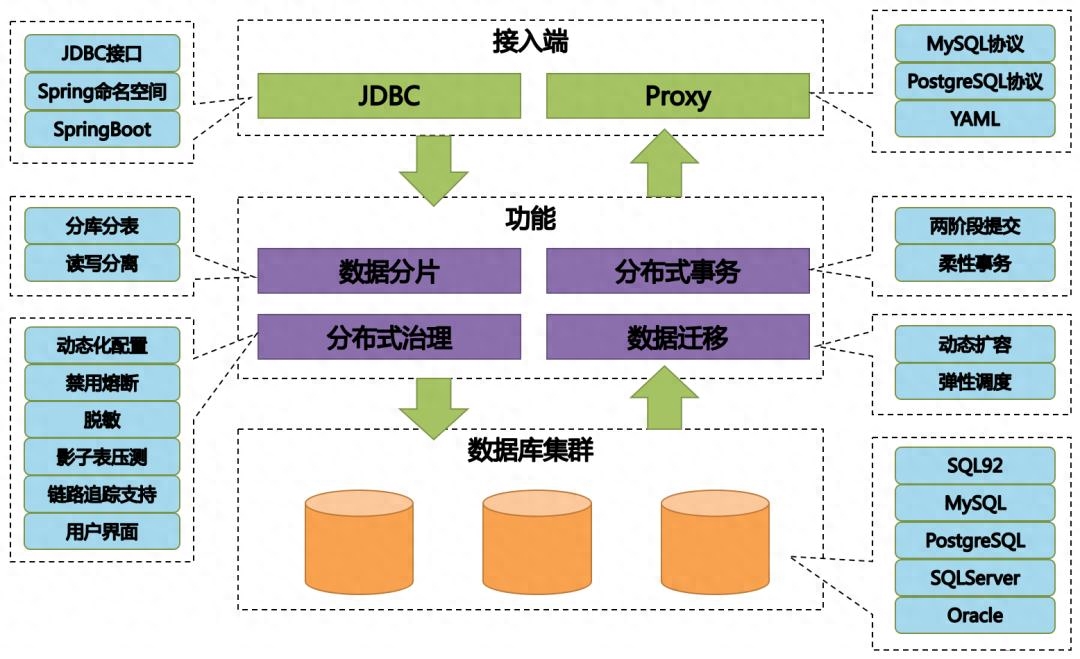
分布式数据库的优势
- 扩展性: 分布式数据库可以轻松地扩展,通过增加节点来应对数据规模的增长,无需对整个系统进行重构。
- 高可用性: 分布式数据库通常具备数据冗余和故障转移的能力,即使部分节点发生故障,数据仍然可用。
- 性能: 分布式数据库可以将数据分布在多个节点上,从而减少单节点的负载,提升查询性能。
- 灵活性: 分布式数据库可以根据不同的业务需求和数据类型选择合适的存储引擎和分布策略。
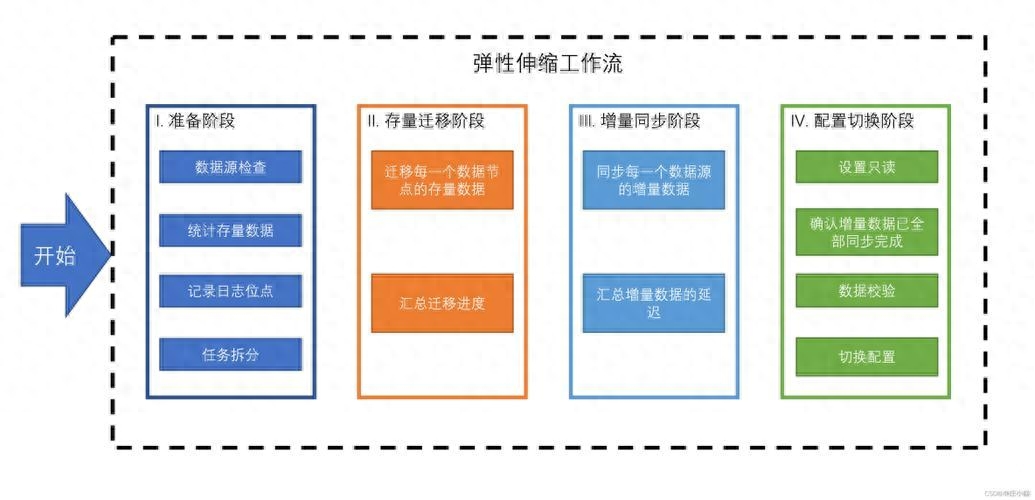
分布式数据库的应用场景
- 大数据分析: 分布式数据库可以支持大规模数据的分析和挖掘,帮助企业从数据中获得洞察和价值。
- 实时应用: 对于需要实时处理和响应的应用,分布式数据库能够提供快速的数据访问和查询。
- 云原生应用: 在云计算环境下,分布式数据库可以轻松适应不断变化的资源需求。
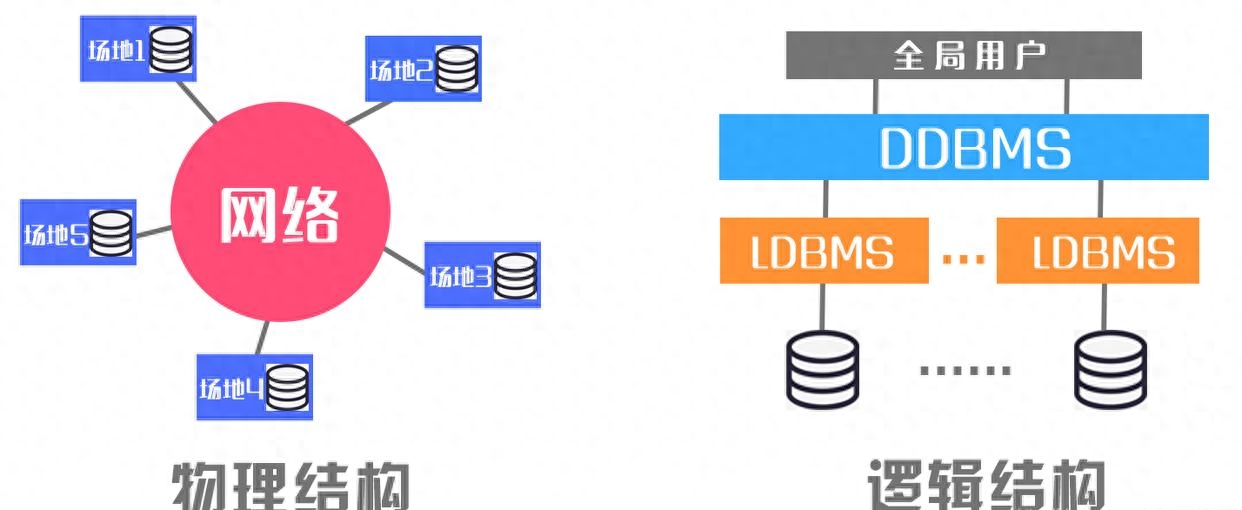
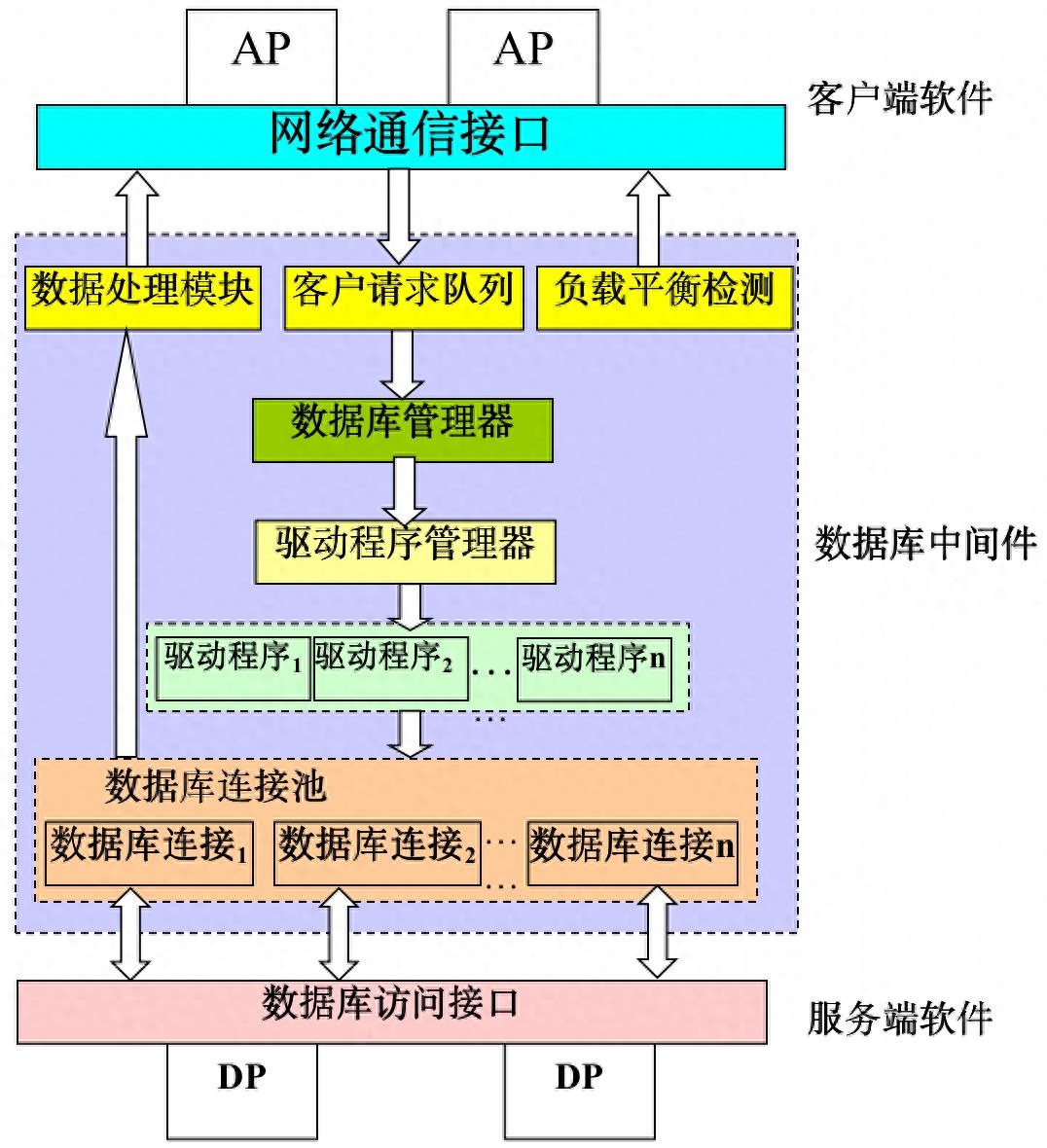
分布式数据库的挑战与注意事项
- 一致性与分区: 分布式数据库需要解决数据一致性和分区的问题,确保数据的正确性和完整性。
- 数据迁移: 分布式数据库的扩展和变更可能需要进行数据迁移,需要谨慎规划和执行。
- 复杂性: 分布式数据库的配置、管理和维护相对复杂,需要专业的技术团队。
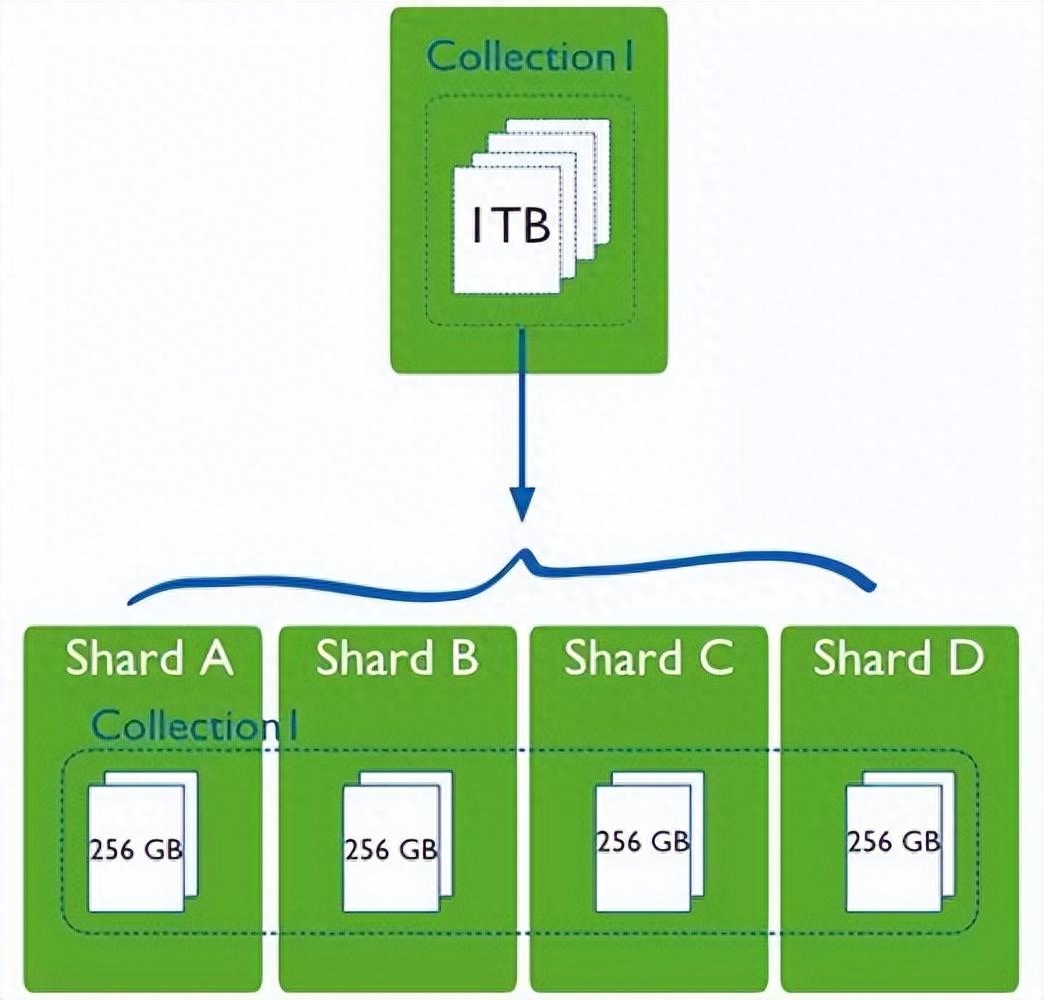
常见的分布式数据库系统
- Apache HBase: 基于Hadoop的分布式数据库,适用于海量结构化数据的存储。
- Cassandra: 高可用性的分布式数据库,适用于高写入和高可扩展性的场景。
- MongoDB: NoSQL数据库,适用于半结构化和非结构化数据的存储和查询。
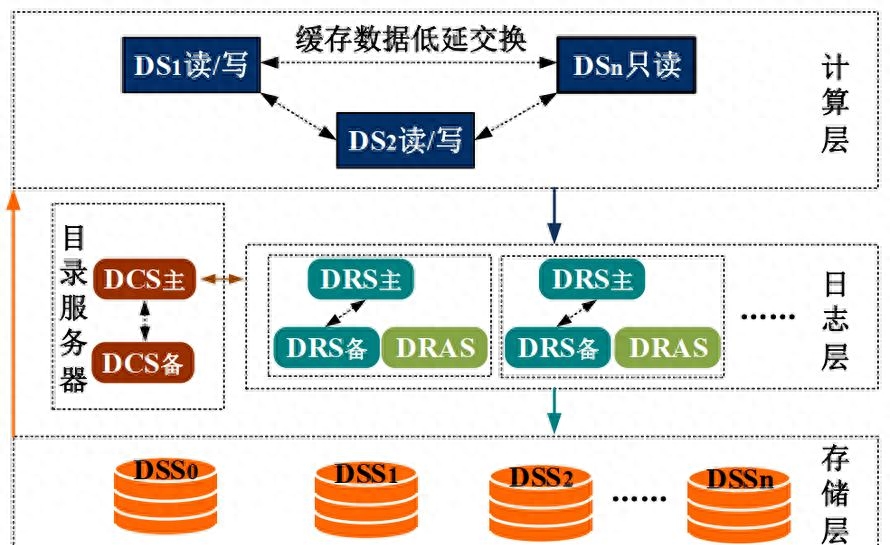
结论
分布式数据库在处理大规模数据和高并发访问方面具有明显的优势。通过有效地管理和存储数据,分布式数据库能够支持企业的大数据分析、实时应用和云原生架构。然而,构建和维护分布式数据库也面临一些挑战,需要在设计和实施过程中注意一致性、数据迁移等问题。综合来看,分布式数据库为企业提供了强大的数据管理和存储工具,为业务的发展和创新提供了有力支持。