1. 初始 Repository
在 DDD 中,Repository 是一个非常重要的概念,它是领域层的一个组件,用来管理聚合根的生命周期和持久化。
1.1. 核心为状态管理
DDD 是由领域对象承载业务逻辑,所有的业务操作均在模型对象上完成,同一聚合上不同的业务操作构成了聚合的生命周期。
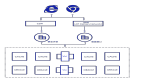
我们以订单为例,如下图所示:

- 首先,用户操作下单,使用提交数据为其创建一个 Order 对象,版本 V1;
- 随后,用户进行改地址操作,调用 Order 对象的 modifyAddress 方法,Order 从原来的 V1 变成 V2;
- 用户完成支付后,调用 Order 对象的 paySuccess 方法,Order 从 V2 变成 V3;
整个流程很好的体现了 Order 聚合根的生命周期。
1.2. 为什么需要 Repository?
假设,有一台非常牛逼的计算机,计算资源无限、内存大小无限、永不掉电、永不宕机,那最简单高效的方式便是将模型对象全部放在内存中。
但,现实不存在这样的机器,我们不得不将内存对象写入磁盘,下次使用时,在将其从磁盘读入到内存。
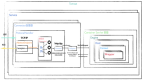
整体结构如下图所示:

和上图相比,具有如下特点:
- 业务操作没变,仍旧依次完成 下单、改地址、支付等操作
- 引入持久化存储(MySQL),可以将 Order 对象存储于关系数据库
- 配合 Order 的生命周期,操作中增加 save、load 和 update 等操作
- 用户下单创建 Order 对象,通过 save 方法将 Order 对象持久化到 DB
- 接收到业务操作,需执行load,从 DB 加载数据到内存 并对 Order 对象的状态进行恢复
- 在业务操作完成后,需执行update,将 Order 对象的最新状态同步的 DB
相对全内存版本确实增加了不小的复杂性,为了更好的对这些复杂性进行管理,引入 Repository 模式。
在领域驱动设计(DDD)中,Repository 是一种设计模式,它是用来存储领域对象的容器。它提供了一种统一的方式来查询和存储领域对象。Repository提供了对底层数据存储的抽象,允许应用程序在没有直接与数据存储技术交互的情况下访问数据,同时该抽象允许在不修改应用程序代码的情况下更改数据存储技术。
【注】在 DDD 中,Repository 并不是一个 DAO,它的职责比 DAO 要多得多,它管理的是整个聚合根,而不是单个实体对象。同时,Repository 还需要提供一些查询接口,用来查询聚合根的状态。
2. 什么是好的 Repository?
Repository 主要用于完成对聚合根生命周期的管理,所以必须提供三组操作:
- 保存。将聚合根同步到底层存储进行持久化处理;
- 查询。根据 ID 或属性从底层存储引擎中读取数据并恢复为内存对象,也就是聚合根对象;
- 更新。聚合对象发生变更后,可以将新的状态同步到存储引擎,以便完成数据更新;
有人会说,这和 DAO 没啥区别吧!!!
DAO 是单表单实体操作,Repository 操作的是整个聚合甚至包括继承关系,这就是最大的区别。也就是Repository 必须能够:
- 维护一个完整的对象组,也就是必须能处理对象的组合关系;
- 维护一个完整的继承体系,也就是必须能够处理对象继承关系;
既支持组合又支持继承,DAO 就没办法更好的承载了。
那就完了吗?并没有!!!
聚合根是一个对象组,包含各种关系,并不是每个业务操作都需要聚合根内的所有实体。
举个例子,在电商订单聚合根内,包括:
- 订单(Order)。记录用户的一次生单,主要保存用户、支付金额、订单状态等;
- 订单项(OrderItem)。购买的单个商品,主要保存商品单价、售价、应付金额等;
- 支付记录(Pay)。用户的支付信息,包括支付渠道、支付金额、支付时间等;
- 收货地址(Address)。用户的收货地址;
在改价流程里,需要修改 Order、OrderItem、Pay 三组实体。
在更新地址流程里,仅需要修改 Address 和 Order 两组实体。
为了满足不同的业务场景,Repository 需要具备两个高级特性:
- 延迟加载。只有在第一次访问关联实体时才对其进行加载,避免过早加载但实际上并没有使用所造成资源浪费问题;
- 按需更新。不管加载了多少组实体,在保存时仅对发生变更的实体进行更新,减少对底层存储引擎的操作次数,从而提升性能;
总体来说,能够具备以下特性的 Repository 才是好的 Repository:
- 支持组合关系
- 支持继承关系
- 支持延迟加载
- 支持按需更新
3. JPA 实例
综合调研各类 ORM 框架,只有 JPA 具备上述特性,而且和 DDD 是绝配。
3.1. 组合关系
组合是一种面向对象编程的重要概念,指一个类的对象可以将其他类的对象作为自己的组成部分。组合在DDD中使用场景最为广泛,这也是聚合的主要工作方式。也就是将一组对象保存到存储引擎,然后在从存储引擎中获取完整的对象组。
从数据视角,组合关系存在两个维度:
- 数量维度。指关联关系两端对象的数量,包括
- 一对一:一个实体对象只能关联到另一个实体对象,例如 公司 和 营业执照,一个公司只会有一个营业执照;
- 一对多:一个实体对象可以关联到多个实体对象,例如 订单 和 订单项,一个订单关联多个订单项;
- 多对一:多个实体对象可以关联到同一个实体对象,例如 订单项 和 订单,一个订单项只属于一个订单;
- 多对多:多个实体对象可以互相关联,例如 社团 和 学生,一个社团包含多个学生,一个学生也可以参加多个社团;
- 方向维度。指对象的引用关系
- 单向关联,只能从一端访问另一端,比如 订单存在订单项的引用,订单项没有到订单的引用;
- 双向关联,可以互相访问,订单存在订单项的引用,订单项也有到订单的引用;
两者组合,情况更加复杂,会产生:
- 单向多对一
- 双向多对一
- 单向一对多
- 双向一对多
- 单向一对一
- 双向一对一
聚合根是一组对象访问的入口,聚合内的所有操作都必须通过聚合根进行,所以,聚合根于其他实体的关系只能是 一对多 和 一对一;同时,所有的业务操作都是从聚合根发起,通过聚合根能关联到内部实体即可,因此也不存在双向。综上所述,DDD 对组合进行了大量简化,实际工作中主要涉及:
- 单向一对一
- 单向一对多
3.1.1. 单向一对一
通过外键的方式实现单向一对一关系,需要在主表中添加一个指向另一个表的外键,通过外键信息获取关联数据。
实体如下:
// 聚合根实现
@Entity
@Table(name = "order_info")
public class Order{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 增加 @OneToOne 注解
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private Pay pay;
// 增加 @OneToOne 注解
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private Address address;
// 忽略其他属性
}
// Pay 实体实现
@Entity
@Table(name = "pay_info")
public class Pay {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 忽略其他属性
}
// Address 实现
@Entity
@Table(name = "address")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 忽略其他属性
}插入记录后,order_Infor 表数据如下

其中:
- address_id 存储的是 Address 实体的主键;
- pay_id 存储的事 Pay 实体的主键;
其中,插入数据的sql如下:
Hibernate: insert into address (detail) values (?)
Hibernate: insert into pay_info (order_id, price) values (?, ?)
Hibernate: insert into order_info (address_id, pay_id, status, total_price, total_selling_price, user_id) values (?, ?, ?, ?, ?, ?)
可见,执行时先插入 address 和 pay 获取主键后,在插入到 order_info 表,从而维护外键的有效性。
3.1.2. 单向一对多
实体定义如下:
// 聚合根实体
@Entity
@Table(name = "order_info")
public class Order{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 添加 @OneToMany 注解
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
// 指定多端的关联列(如果不指定,会使用第三张表来保存关系
@JoinColumn(name = "order_id")
private List<OrderItem> orderItems = new ArrayList<>();
// 忽略其他属性
}
// OrderItem 实现
@Entity
@Table(name = "order_item")
public class OrderItem {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 忽略其他属性
}插入记录后,表数据如下:
order 表数据:

order+item表数据:

其中 order_item 表中的 order_id 指向 order_info 表的主键。
3.2. 继承关系
继承是面向对象编程的核心特性,但这一特性确与数据库的关系模型产生巨大阻抗。
JPA 中提供了三种继承模型,包括:
- 单表继承策略(SINGLE_TABLE)。父类实体和子类实体共用一张数据库表,在表中通过一列辨别字段来区别不同类别的实体;
- Joined 策略(JOINED)。父类和子类分别对应一张表,父类对应的表中只有父类自己的字段,子类对应的表中中有自己的字段和父类的主键字段,两者间通过 Join 方式来处理关联;
- 每个实体一个表策略(TABLE_PER_CLASS)。每个实体对应一个表,会生成多张表,父类对应的表只有自己的字段。子类对应的表中除了有自己特有的字段外,也有父类所有的字段。
为了更好的对比各种策略,我们以一个业务场景为案例进行分析。
在优惠计算过程中,需要根据不同的配置策略对当前用户进行验证,以判断用户是否能够享受优惠,常见的验证策略有:
- 只有特定用户才能享受。
- 只有男士或女士才能享受。
- 只有VIP特定等级才能享受。
- 未来还有很多
为了保障系统有良好的扩展性,引入策略模式,整体设计如下:

那接下来便是将这些实现类存储到数据库,然后在方便的查询出来。
3.2.1. 单表继承
单表继承非常简单,也最为实用,数据库表只有一张,通过一列辨别字段来区别不同类别的实体。
它的使用涉及几个关键注解:
- @Inheritance(strategy = InheritanceType.SINGLE_TABLE),添加在父类实体,用于说明当前使用的是 单表策略;
- @DiscriminatorColumn(name="区分类型存放的列名"),添加在父类实体,用于说明使用哪个列来区分具体类型;
- @DiscriminatorValue(value = "当前类型的标识") 添加到子类实体上,用于说明当前子类的具体类型;
相关实体代码如下:
// 父类
@Entity
// 单表表名
@Table(name = "activity_matcher")
// 当前策略为单表策略
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
// activity_type 列用于存储对应的类型
@DiscriminatorColumn(name = "activity_type")
@Data
public abstract class BaseActivityMatcher implements ActivityMatcher {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private ActivityMatcherStatus status = ActivityMatcherStatus.ENABLE;
}
// SpecifyUserMatcher 实现类
@Entity
// 使用 SpecifyUser 作为标记
@DiscriminatorValue("SpecifyUser")
public class SpecifyUserMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}
// SexMatcher 实现类
@Entity
// 使用 Sex 作为标记
@DiscriminatorValue("Sex")
public class SexMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}
@Entity
// 使用 VipLevel 作为标记
@DiscriminatorValue("VipLevel")
public class VipLevelMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}每种策略保存一条数据后,数据库表activity_matcher数据如下图所示:

其中:
- activity_type 用于区分当前数据对应的策略类型;
- VipLevel类型下,只有 status 和 levels 生效,服务于 VipLevelMatcher,其他全部为 null;
- SpecifyUser 类型下,只有 status 和 user_ids 生效,服务于 SpecifyUserMatcher,其他全部为 null;
- Sex类型下,只有 status 和 sex 生效,服务于 SexMatcher,其他全部为 null;
单表继承策略,最大的优点便是简单,但由于父类实体和子类实体共用一张表,因此表中会有很多空字段,造成浪费。
3.2.2. Joined 策略
Joined策略,父类实体和子类实体分别对应数据库中不同的表,子类实体的表中只存在其扩展的特殊属性,父类的公共属性保存在父类实体映射表中。
它的使用涉及几个关键注解:
- @Inheritance(strategy = InheritanceType.JOINED),添加在父类实体,用于说明当前使用的是 Joined 策略;
- @PrimaryKeyJoinColumn(name="子类主键列名称"),添加在子类实体,用于说明使用哪个列来关联父类;
相关实体代码如下:
// 父类
@Entity
@Table(name = "activity_joined_matcher")
// 当前策略为Joined策略
@Inheritance(strategy = InheritanceType.JOINED)
@Data
public abstract class BaseActivityMatcher implements ActivityMatcher {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private ActivityMatcherStatus status = ActivityMatcherStatus.ENABLE;
}
// SpecifyUserMatcher 实现类
@Entity
@Table(name = "user_joined_matcher")
@PrimaryKeyJoinColumn(name = "matcher_id")
public class SpecifyUserMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}
// SexMatcher 实现类
@Entity(name = "JoinedSexMatcher")
@Table(name = "sex_joined_matcher")
@PrimaryKeyJoinColumn(name = "matcher_id")
public class SexMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}
// VipLevelMatcher 实现类
@Entity(name = "JoinedVipLevelMatcher")
@Table(name = "vip_joined_matcher")
@PrimaryKeyJoinColumn(name = "matcher_id")
public class VipLevelMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}每种策略保存一条数据后,各个表数据如下:
activity_joined_matcher 如下:

user_joined_matcher 如下:

sex_joined_matcher 如下:

vip_joined_matcher 如下:

具有以下特点:
- 主表存储各个子类共享的父类数据;
- 子表通过字段与主表相关联;
- 主表有所有子表的数据,每个子表只有他特有的数据;
从表数据上可以看出,Joined策略可以减少冗余的空字段,但是查询时需要多表连接,效率较低。
3.2.3. 每个实体一个表策略
TABLE_PER_CLASS 策略,父类实体和子类实体每个类分别对应一张数据库中的表,子类表中保存所有属性,包括从父类实体中继承的属性。
它的使用主要涉及以下几个点:
- @Inheritance(strategy = InheritanceType.TABLE_PER_CLASS),添加在父类实体,用于说明当前使用的是 TABLE_PER_CLASS 策略;
- @GeneratedValue(strategy = GenerationType.AUTO) 不要使用IDENTITY,需要保障每个子类的 id 都不重复;
- 抽象父类不需要表与之对应,非抽象父类也需要表用于存储;
相关实体代码如下:
// 父类
@Entity
// 当前策略为 TABLE_PER_CLASS 策略
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@Data
public abstract class BaseActivityMatcher implements ActivityMatcher {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
// 省略属性和方法
}
// SpecifyUserMatcher 实现类
@Entity
@Table(name = "user_per_class_matcher")
public class SpecifyUserMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}
// SexMatcher 实现类
@Entity
@Table(name = "sex_per_class_matcher")
public class SexMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}
// VipLevelMatcher 实现类
@Entity
@Table(name = "vip_per_class_matcher")
public class VipLevelMatcher
extends BaseActivityMatcher
implements ActivityMatcher {
// 省略属性和方法
}每种策略保存一条数据后,各个表数据如下:
user_per_class_matcher 如下:

sex_per_class_matcher 如下:

vip_per_class_matcher 如下:

具有以下特点:
- 每个具体的子类对应一张表,表中存储父类和子类的数据;
- 为每个子类生成id,所生成的 id 不重复;
从表数据上可以看出,子类中有相同的属性,则每个子类都需要创建一遍,会导致表结构冗余,影响查询效率。
3.2.4. 小节
三种策略各具特色,都有最佳应用场景,简单如下:
- 单表策略。
子类的数据量不大,且与父类的属性差别不大;
ß可以使用单表继承策略来减少表的数量;
- Joined 策略。
- 子类的属性较多,且与父类的属性差别较大;
- 需要一个主表,用于对所有的子类进行管理;
- 每个实体一个表策略。
- 子类的属性较多,且与父类的属性差别较大;
- 子类过于离散,无需统一管理;
当子类过多或数据量过大时,Joined 和 table per class 在查询场景存在明显的性能问题,这个需要格外注意。
3.3. 立即加载&延迟加载
JPA提供了两种加载策略:立即加载和延迟加载。
- 一对一关联,默认获取策略是立即加载(EAGER),查询一个对象,会把它关联的对象都查出来初始化到属性中;
- 一对多关联,默认获取策略是懒加载(LAZY),即只有在使用到相关联数据时才会查询数据库;
如果默认策略不符合要求,可以通过手工设置注解上 fetch 配置,对默认策略进行重写。
3.3.1. 立即加载
立即加载会在查询主实体类的同时查询它所有关联实体类,并绑定到实体属性上。
立即加载的好处是能够提高查询效率,因为不需要额外的查询操作。但是,使用立即加载会增加数据库的查询负担,查询出所有关联实体类,会导致查询结果的数据量比较大。
实体配置如下:
@Entity
@Table(name = "order_info")
public class Order{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinColumn(name = "order_id")
private List<OrderItem> orderItems = new ArrayList<>();
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private Pay pay;
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private Address address;
// 忽略其他属性和方法
}测试脚本如下:
Order order = this.orderRepository.findById(this.order.getId()).get();
Assertions.assertNotNull(order);
System.out.println("访问 item");
Assertions.assertEquals(3, order.getOrderItems().size());
System.out.println("访问 address");
Assertions.assertNotNull(order.getAddress().getDetail());
System.out.println("访问 pay");
Assertions.assertNotNull(order.getPay().getPrice());日志输出如下:
Hibernate: select order0_.id as id1_3_0_, order0_.address_id as address_6_3_0_, order0_.pay_id as pay_id7_3_0_, order0_.status as status2_3_0_, order0_.total_price as total_pr3_3_0_, order0_.total_selling_price as total_se4_3_0_, order0_.user_id as user_id5_3_0_, address1_.id as id1_2_1_, address1_.detail as detail2_2_1_, orderitems2_.order_id as order_id6_4_2_, orderitems2_.id as id1_4_2_, orderitems2_.id as id1_4_3_, orderitems2_.price as price2_4_3_, orderitems2_.product_id as product_3_4_3_, orderitems2_.quantity as quantity4_4_3_, orderitems2_.selling_price as selling_5_4_3_, pay3_.id as id1_5_4_, pay3_.price as price2_5_4_ from order_info order0_ left outer join address address1_ on order0_.address_id=address1_.id left outer join order_item orderitems2_ on order0_.id=orderitems2_.order_id left outer join pay_info pay3_ on order0_.pay_id=pay3_.id where order0_.id=?
访问 item
访问 address
访问 pay从日志输出可见:
- JPA 使用多张表的join,通过一个复杂的 sql 一次性获取了所有数据;
- 在访问关联实体时,未触发任何加载操作;
3.3.2. 延迟加载
延迟加载是指在进行数据库查询时,并不会立即查询关联表数据,而是要等到使用时才会去查,这样可以避免不必要的数据库查询,提高查询效率。
延迟加载又分为两种情况:
- 表间的延迟加载:在表关联情况下,进行数据库查询时,并不会立即查询关联表,而是要等到使用时才会去查数据库;
- 表中属性的延迟加载:比如大型字段blob,需要等到使用时才加载,这样可以避免不必要的数据库查询,提高查询效率;
在此,重点介绍表间关联的延迟加载:
实体代码如下所示:
@Entity
@Table(name = "order_info")
public class Order{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name = "order_id")
private List<OrderItem> orderItems = new ArrayList<>();
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Pay pay;
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Address address;
// 忽略其他字段和方法
}查询代码如下:
Order order = this.orderRepository.findById(this.order.getId()).get();
Assertions.assertNotNull(order);
System.out.println("访问 item");
Assertions.assertEquals(3, order.getOrderItems().size());
System.out.println("访问 address");
Assertions.assertNotNull(order.getAddress().getDetail());
System.out.println("访问 pay");
Assertions.assertNotNull(order.getPay().getPrice());控制台输出如下:
Hibernate: select order0_.id as id1_3_0_, order0_.address_id as address_6_3_0_, order0_.pay_id as pay_id7_3_0_, order0_.status as status2_3_0_, order0_.total_price as total_pr3_3_0_, order0_.total_selling_price as total_se4_3_0_, order0_.user_id as user_id5_3_0_ from order_info order0_ where order0_.id=?
访问 item
Hibernate: select orderitems0_.order_id as order_id6_4_0_, orderitems0_.id as id1_4_0_, orderitems0_.id as id1_4_1_, orderitems0_.price as price2_4_1_, orderitems0_.product_id as product_3_4_1_, orderitems0_.quantity as quantity4_4_1_, orderitems0_.selling_price as selling_5_4_1_ from order_item orderitems0_ where orderitems0_.order_id=?
访问 address
Hibernate: select address0_.id as id1_2_0_, address0_.detail as detail2_2_0_ from address address0_ where address0_.id=?
访问 pay
Hibernate: select pay0_.id as id1_5_0_, pay0_.price as price2_5_0_ from pay_info pay0_ where pay0_.id=?从日志输出可知,关联实体只有在属性被访问时才会触发自动加载。
延迟加载在聚合更新时极为重要,面对一个大聚合,每次修改只会涉及少量相关联的实体,由于延迟加载机制的保障,对于那些没有必要访问的实体并不会执行实际的加载操作,从而大幅提升性能。
3.4. 按需更新
简单理解按需更新,就是只有在有必要时才会对数据进行更新。
按需更新可以分为两个场景:
- 只更新变更实体:在保存一组对象时,只对状态发生变化的实体进行更新;
- 只更新变更字段:保存一个实体时,只对状态发生变化的字段进行更新;
3.4.1. 只更新变更实体
在数据保存时,JPA 会自动识别发生变更的实体,仅对变更实体执行 update 语句。
测试代码如下:
Order order = this.orderRepository.findById(this.order.getId()).get();
order.getOrderItems().size(); // 获取未更新
order.getPay().getPrice(); // 获取未更新
order.getAddress().setDetail("新地址"); // 获取并更新
System.out.println("更新数据");
this.orderRepository.save(order);控制台输出如下:
Hibernate: select order0_.id as id1_3_0_, order0_.address_id as address_6_3_0_, order0_.pay_id as pay_id7_3_0_, order0_.status as status2_3_0_, order0_.total_price as total_pr3_3_0_, order0_.total_selling_price as total_se4_3_0_, order0_.user_id as user_id5_3_0_ from order_info order0_ where order0_.id=?
Hibernate: select orderitems0_.order_id as order_id6_4_0_, orderitems0_.id as id1_4_0_, orderitems0_.id as id1_4_1_, orderitems0_.price as price2_4_1_, orderitems0_.product_id as product_3_4_1_, orderitems0_.quantity as quantity4_4_1_, orderitems0_.selling_price as selling_5_4_1_ from order_item orderitems0_ where orderitems0_.order_id=?
Hibernate: select pay0_.id as id1_5_0_, pay0_.price as price2_5_0_ from pay_info pay0_ where pay0_.id=?
Hibernate: select address0_.id as id1_2_0_, address0_.detail as detail2_2_0_ from address address0_ where address0_.id=?
更新数据
Hibernate: update address set detail=? where id=?从日志输出可见:
- 对聚合中 的实体进行了加载操作;
- 但,仅对变更的 address 实体执行了 update 语句;
3.4.2. 只更新变更字段
只更新变更字段,是指只更新实体类中有变化的字段,而不是全部字段。为了实现按需更新,需要在实体类中使用@DynamicUpdate注解,表示只更新有变化的字段。
实体代码见:
@Entity
@Table(name = "order_info")
@DynamicUpdate
public class Order{
// 其他忽略
}测试代码如下:
Order order = this.orderRepository.findById(this.order.getId()).get();
order.setUserId(RandomUtils.nextLong()); // 仅更新 user id
System.out.println("更新数据");
this.orderRepository.save(order);控制台输出如下:
Hibernate: select order0_.id as id1_3_0_, order0_.address_id as address_6_3_0_, order0_.pay_id as pay_id7_3_0_, order0_.status as status2_3_0_, order0_.total_price as total_pr3_3_0_, order0_.total_selling_price as total_se4_3_0_, order0_.user_id as user_id5_3_0_ from order_info order0_ where order0_.id=?
更新数据
Hibernate: update order_info set user_id=? where id=?如果移除 @DynamicUpdate 注解,控制台输出如下:
Hibernate: select order0_.id as id1_3_0_, order0_.address_id as address_6_3_0_, order0_.pay_id as pay_id7_3_0_, order0_.status as status2_3_0_, order0_.total_price as total_pr3_3_0_, order0_.total_selling_price as total_se4_3_0_, order0_.user_id as user_id5_3_0_ from order_info order0_ where order0_.id=?
更新数据
Hibernate: update order_info set address_id=?, pay_id=?, status=?, total_price=?, total_selling_price=?, user_id=? where id=?对比输出可知:使用@DynamicUpdate注解后,当修改实体类中的某个字段时,JPA会自动将该字段标记为“脏数据”,并只更新标记为“脏数据”的字段,这样可以减少数据库的IO操作,提高更新效率。
4. 小节
本章从 DDD 聚合生命周期讲起,当我们面对一组高内聚对象时,如何更好的对这一对象组进行维护。
从高内聚对象组视角需要支持:
- 对象间的组合关系;
- 对象间的继承关系;
从系统性能角度需要支持:
- 延迟加载:只有在使用时才触发实体加载;
- 按需更新:只对状态变更实体或字段进行更新;
JPA 与 DDD 的==聚合写== 是绝配,但在 “读” 场景 往往会引发各种性能问题。这也是很多公司弃用 JPA 而选择 MyBatis 的主要原因,就其本质并不是框架的错,而是将框架用在了错误的场景。
对于 Command 和 Query 分离架构,最佳组合是:
- Command 侧以 DDD 和 JPA 为核心,享受面向对象强大设计力,享受 JPA 所带来的便利性,从而解放双手,提升开发效率;
- Query 侧以 DTO 和 MyBatis 为核心,享受 MyBatis 对 SQL 强大控制力,更好的压榨 MySQL 性能,从而降低成本;