一、背景和架构演进思考
近十年大数据发生了很大变化,从一开始的Hadoop满足数据简单可查可用,到现在对数据分析的极速OLAP需求,大家对数据探索的性能要求越来越高。同时数据量在近几年也是不断增长,降本增效成为用户普遍的需求。
虽然这些年SSD不管是性能还是成本都获得了长足的进步,但是在可见的未来5年,HDD还是会以其成本的优势,成为企业中央存储层的首选硬件,以应对未来还会继续快速增长的数据。
如下图是一次OLAP分析读取ORC数据的情况,灰色竖条表示OLAP分析需要读取的三列数据在整个文件中的可能的位置分布 ,也就是只会读ORC的Stripe文件中某一小部分数据。
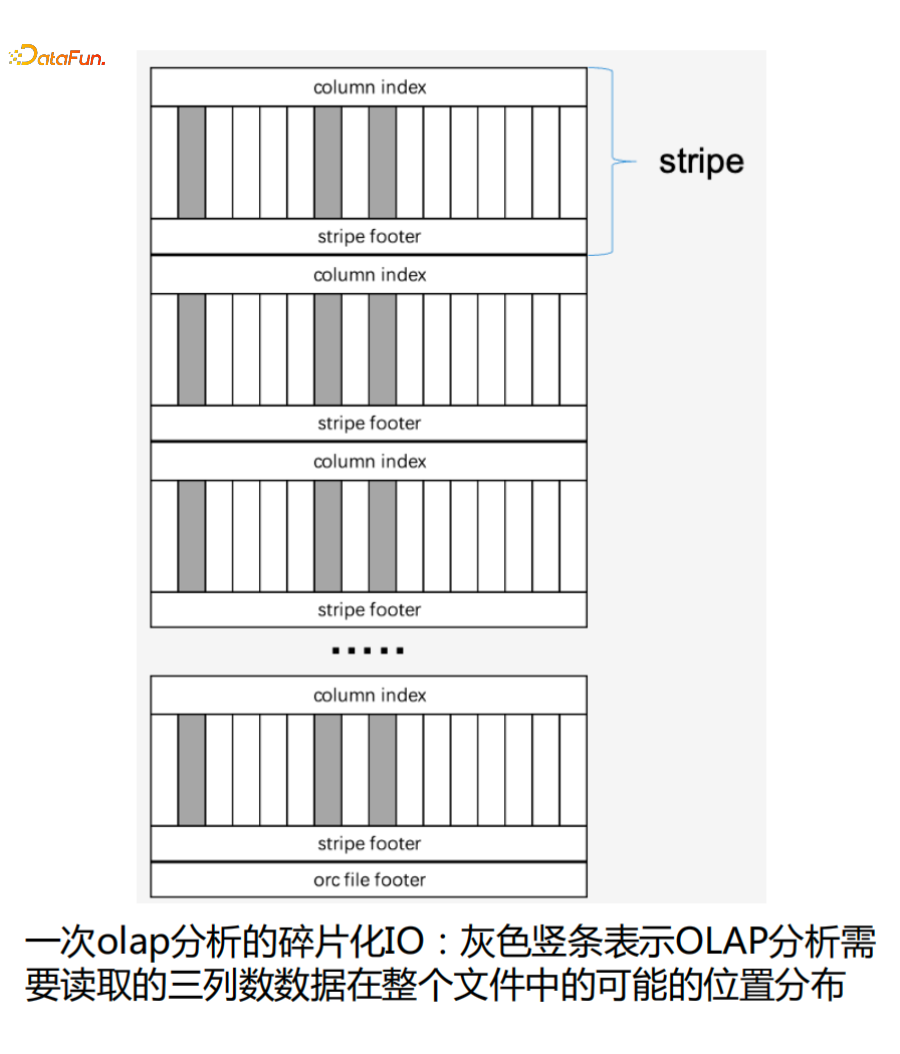
可以看到整个读取过程是一个碎片化的IO过程,所以就存在使用低成本HDD解决存储低成本需求和OLAP分析性能越来越快的矛盾。基于此也引发了我们的一些思考。

在整个OLAP过程中有很多常见架构的选择,比如有一些公司会选择直连中央存储架构,这种架构存在两方面的问题:
- HDD磁盘读取寻道会存在并发瓶颈,另外就是碎片化IO寻道耗时较长。
- 金融科技白天会运行很多算法类的和画像类任务不断运行,使用中央存储IO负载较高,OLAP分析只要有一个Task没有返回结果就会引发长尾效应,导致整个分析任务都会卡住。
另一种经常选择的架构是独立OLAP存储计算架构,也就是把数据抽取到一份独立的存储,然后在上面做OLAP分析,但是这种方案也在不断的受到挑战:
- 第一点就是数据的边界问题:在这样的一种方案下数据的边界是没有办法灵活去调整的,比如一开始用户要求这一份数据只存三个月,但是某一天因为有一些特殊的场景需要对比去年或早期数据,那么需要更长的时间范围,这时候是没有办法快速灵活的调整数据的可访问范围。
- 第二点是数据一致性问题,我们在金融行业经常被挑战,毕竟增加了一次的数据的复制,必然会存在数据一致性的问题;如果发生数据的回溯,对历史的数据的重新生成,会进一步增加数据不一致的概率。
- 第三点就是数据安全的问题,这也是金融行业最常谈的,把数据抽取一份到独立存储,那每个库表的权限怎么管理是需要考虑的。
重新思考以上问题,其实背后需求是冷热存储的需求,受限越来越快OLAP分析我们需要的是一份能够被OLAP独享的一份数据副本,而且它最好是SSD存储,满足更高的性能要求;其次不引入额外的数据管理成本,只管理数据生命周期而不用关注权限和安全。因此在这样背景下我们进行了一些探索,也就是今天要分享的主题,即presto+腾讯DOP(Alluxio)来解决我们刚才所提出了几个问题。
二、Presto+腾讯DOP(Alluxio)架构
Alluxio一般用来做缓存加速,大部分情况下是一种以co-located方式跟节点做混合部署,提高I/O本地性,用覆盖20%数据需满足80%的查询需求,去保证高频请求的加速,另外根据节点多副本情况动态调整,满足更高的数据查询负载。
在腾讯金融科技,我们倾向是把Alluxio当做HDFS的SSD副本来使用,与底层IO进行隔离,因此是不要求co-located部署,以远程访问为主,那么这种情况就需要更大存储来独立扩缩容,尽可能多的缓存用户需要的那部分数据,并且在Alluxio中配置单副本就基本能满足了我们现在的查询并发压力。
在我们整个架构选型中涉及几个技术决策点:
- 我们选择presto主要考虑到是他的调度的模型,他能够根据每个节点的状态去分配不同的split,相比于静态模型会有更强的容错性,可以减少一些长尾的效应;还有他的本地优先级对列,能够比较好的去平衡大查询和小查询之间的矛盾,会根据每个查询执行时长区分的不同的等级,在越短时间内能够更快的完成。另外一点我们选择Presto是因为我们有一些存量的技术基础,包括我们数据平台部做了一些技术积淀。
- 我们引入SuperSQL主要是考虑两点:第一点主要是SuperSQL基于Calcite统一语法,能够无缝的把Presto的SQL查询转到Spark上,这样可以在一些大查询场景下缓解Presto计算资源压力;第二点是在Presto落地过程中发现在Left Join场景下对右表的带有null值的列做count distinct 很容易出现数据倾斜,因此使用Calcite对distinct今进行展开解决count distinct的问题;
- 引入腾讯DOP(Alluxio)主要因为:第一点我们是想利用Alluxio的LRU缓存策略来实现数据的生命周期管理;第二点独立部署Alluxio可以利用ssd加速我们OLAP的查询请求;第三点是利用Alluxio数据CACHE预加载策略,通过olap引擎侧主动发起预加载查询, 让alluxio被动触发预加载。

在这种架构选择下我们同样会会面临几个挑战:
挑战一就是选择Alluxio CACHE模式如何保障ALLUXIO中数据稳定性?
Presto Client端在发起数据读取时会查询Alluxio Worker中是否缓存所需要的数据块,如果发现数据并没有在Alluxio,就会去底层的HDFS把数据读回来,需要多少数据就读多少数据,数据读回来之后先返回给Presto侧满足后续的计算,同时也会发送异步的Cache quest的请求缓存命令到Alluxio Worker,如果Worker节点内存空间不够,则会根据配置清理策略淘汰一部分数据,比如LRU就会把最早的那部分数据把它淘汰出去,然后把新的数据块缓存进来。在这个过程中如果用户突然发起一个意外的超大范围查询或历史数据访问触发大量的block驱逐,导致我们经常用到的那部分数据都不会被缓存。

为了解决这个问题,首先我们在Presto中了对Alluxio模块进行扩展实现旁路直连功能,对Presto查询请求进行判断,对于大范围查询直接绕过读取Alluxio的流程,直接读取HDFS。这个模块我们做了库表白名单和库表范围配置功能,构建横向和纵向的稳定性护城河。

在白名单里我们限定哪些库表能够访问Alluxio,避免预期之外的查询访问触发Alluxio大面积的数据驱逐;另外通过时间范围纵向约束,限制什么时间范围内数据才会走Alluxio查询。
但仅通过上述方法还是不够,因为真正业务上很难确定什么表应该要缓存什么样的时间,而且用户的查询需求跟现在实际的缓存是否能够匹配也不能确定。因此我们后面又做了进一步的优化,继续结合用户的历史的查询去计算出最优的存储范围。
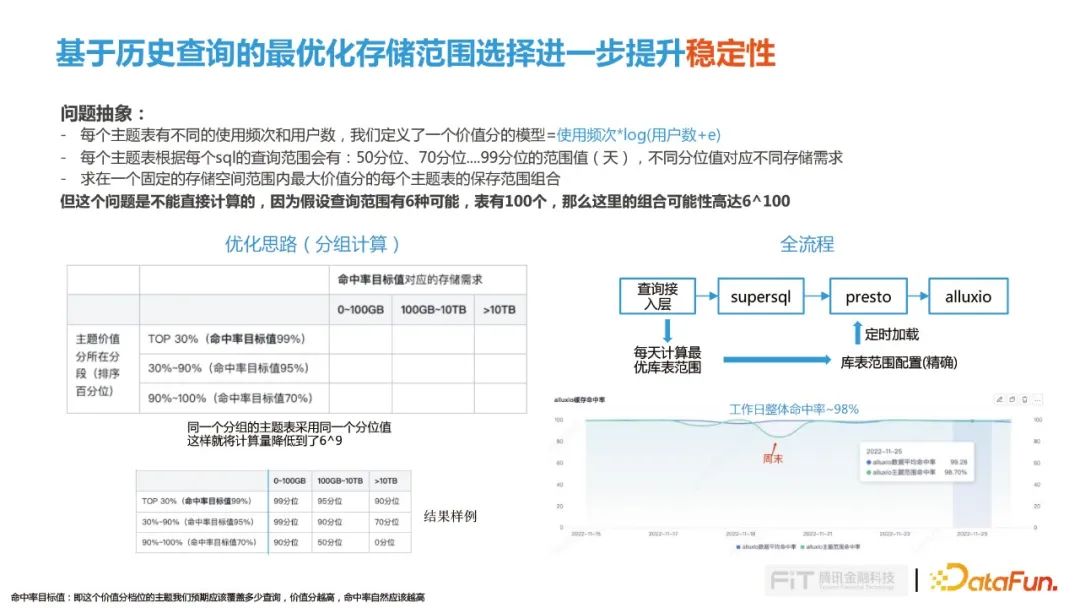
这个问题可以抽象为一下模型:
- 每个主题表有不同的使用频次和用户数,我们定义了一个价值分的模型=使用频次*log(用户数+e) 。
- 每个主题表根据每个sql的查询范围会有:50分位、70分位....99分位的范围值(天),不同分位值对应不同存储需求。
- 求在一个固定的存储空间范围内最大价值分的每个主题表的保存范围组合。
但这个问题是不能直接计算的,因为假设查询范围有6种可能,表有100个,那么这里的组合可能性高达6^100,因此我们从数据主题价值分和存储命中率两个维度进行分组,同一个分组的主题表采用同一个分位值这样就将计算量降低到了6^9,这样就能够计算充分利用Alluxio的存储,又能达到最佳用户价值。
我们查询接入层会每天计算过去14天最优库表范围,然后加载到Presto的库表白名单中控制数据的访问,通过这种方式我们整体缓存命中率能够达到98%。
挑战二是如何提升腾讯DOP(Alluxio)的存储的扩展性?
我们把Alluxio当做存储层存在独立扩展的问题,在整个方案落地的过程中会有一些异构的存储,比如一些机器的SSD存储比较大,一些机型SSD存储比较小,如何让存储能够被充分利用是我们需要考虑的问题。
在Allluxio已有的策略中:
- RoundRobinPolicy和DeterministicHashPolicy都属于平均策略,将请求平均分配给所有Worker, 由于小容量的worker能够处理请求低于大容量,因此其上的数据淘汰率更高。
- MostAvailableFirstPolicy策略,可能会导致大容量worker容易成为数据加载热点,而且因为所有 worker存储最终都会达到100%,所以满了之后这个策略也就是失去意义了。

针对这个问题,腾讯内部设计了基于容量的存储分配策略CapacityBaseRandomPolicy的策略,也贡献给了Alluxio社区。CapacityBaseRandomPolicy策略在随机策略的基础上,基于不同worker的容量给予不同节点不同的分发概率。这样容量更大的worker就会接收更多的请求,配合不同worker上的参数调整,实现了均衡的数据负载。

这个策略在内部上线初期也达到了在预期的效果,不同worker根据其自身容量来接收多少请求存储多大数据量,这样就保证每个worker上淘汰率是相同的,数据得到了比较好的保留。后面我们又演化了优化版的CapacityBaseDeterministicHashPolicy的策略,主要考虑到在初期加载的时候,Presto对同一份数据同时发送多个请求,因为randon的策略分到不同的worker,导致的就在多个worker上在某一时刻会并发多个加载同一份数据,对这种情况做了优化。
这个功能上线后,内部又做了实际的测试,基于历史的查询做了回放,回放了两个场景还是我们最开始关注的两个点:IO隔离和SSD加速。

我们利用五个并发在闲时和忙时两个时段进行测试。
闲时阶段我们选了周末的某下午,在整个HDFS集群比较闲的时候进行,在这个测试场景下,如果有Alluxio 90分位的耗时是16,没有Alluxio则90分位耗时则达到27,整体性能提升68%,这个加速来源是Alluxio使用的SSD硬盘。
忙时阶段测试我们选择了一个工作日的早晨,这个测试下有Alluxio 90分位耗时为18,相对闲时阶段并没有太大差异,但是如果没有Alluxio 90分位耗时达到了71,主要的原因是在这个时间段在我们的HDFS集群中央存储会有很多的计算IO负载,导致它的IO波动会非常大,根据长尾理论查询的耗时就会拉的非常长,这块加速的原因就是因为SSD加速加上IO隔离的效果。
因为我们的计算都是远程读,计算和存储是完全分离的状态,整个计算节点是完全对等的,所以后面我们又进一步做了探索,基于内部峰峦K8S进行潮汐调度,白天将YARN的空闲计算资源动态的扩容到Presto集群来加速作业执行,晚上再把资源返还给YARN集群跑离线任务。这样就把我们整个集群的资源充分利用起来,提升OLAP引擎的性能。

三、落地过程中的优化实践
这一小节主要分享我们再落地过程中遇到的两个问题及优化实践:
presto在orc上的优化实践
Presto有两种类型的stage:source stage(数据读取,涉及底层Alluxio及HDFS的IO操作)和fixed stage(其他的Agg、Join等操作),source stage的有效并发取stripe数量和split 数量最小值, fix stage的并发则是由task.concurrency参数指定。本文围绕source stage对ORC的并发优化展开。
ORC一个文件包含多个stripe,每个Stripe包含多个Column,可以理解为先按行进行分组,然后组内按照列进行存储。如右下图示意ORC文件中有3个stripe文件,默认情况initial_split_size是32M,max_split_size是64M,实际上split_size并不等同于并发量,主要原因是Presto计算并发时,如果一个split跨了两个column读取是无意义的,否则无法独立计算,所以并发计算逻辑是判断split是否包含stipe的开始位置,包含stipe的开始位置才是有效的split。
在ORC写入逻辑中有个参数是orc.stripe.size,用于控制写入过程中内存的buffer,buffer,满了就会触发flush,压缩生成一个stripe。这种方式可能会导致两个极端:
- 行数过多,表的字段比较少情况Presto并发会比较低;
- 行数过少,表的字段却很多或内容较大,导致IO次数过高,效率低或触发合并读取。

Presto中的合并读是对IO读取的优化,合并机制是由hive.orc.tiny-stripe-threshold参数控制,如果stripe的大小小于参数值(默认8M)则完全读取整个stripe的所有列,如果文件都小于这个值就更是如此。在测试过程中遇到一种情况是一个简单的count(*)的查询,由于触发了合并读读取了几百G的文件(PS: 在有些TPCDS的测试中生成的文件都是小于8M的,这种情况也会失去列式存储减少IO的效果,导致性能大幅降低)。
如右下图实际的case中,每一个stripe都有5000行,读一个column需要加载几百G的IO,完全失去了列式存储的优势。这里我们线上的优化点是结合SSD的特性把参数调整为1MB,避免过度合并IO,减少Alluxio的IO吞吐和网络开销,另外一点我们再思考能否对ORC文件合并进行更合理的控制。

由于stripe size内存buffer跟行数的对应关系是很难计算的,跟表的字段及字段包含的大小有关,所以同样的64M的stripe size,如果只有5列那么可以容纳500w行,如果有500列的宽表那么可能只有1w行,这样也很难与数仓同学沟通,那么stripe size的参数设置为多大就非常难以决策了。也正基于此我们再ORC中增加了一个参数:orc.stripe.row.count (对应社区Issue:ORC-1172),实现思想就是在stripe.size的基础上增加行数的约束,这样就可以把stripe.size参数设置大一些,然后设置相对合理的row.count参数,这样就可以满足OLAP的查询需求了。

腾讯DOP(Alluxio) master的优化
在一些对Alluxio IO场景要求比较高的场景,比如漏斗查询,会发现IO的耗时会比较高,定位发现在Alluxio的master中RPC排队比较严重,然后使用Kona-profiler观察发现大量未被释放的Rocksdb的Finalizer引用,占用了26GB的内存,影响了GC的回收。
基于这个问题我们去分析了Alluxio master的元数据,它的元数据包括两块:
- inode: 目录和文件信息。
- block: 数据块元信息和location信息。
因为数据块的元信息的量是会随着时间的增长是会持续增长,但location的信息是相对稳定的,而且它是变化比较快的一部分,因此我们考虑把数据块元信息还保留在Rocksdb,另外block的location信息放在内存里面。通过这项优化QPS从原来2.5万提升到了6.5万,master的RPC情况也得到了大幅缓解(PR 15238)。

四、总结与展望
这是一次非常成功的跨 BG,跨团队协作,快速有效的解决腾讯 Alluxio(DOP) 落地过程中的问题,顺利使得腾讯 Alluxio(DOP) 在 金融业务场景落地。
在整个Alluxio的优化过程中,不断对IO、CPU和网络进行循环优化,先做了一轮io的优化,然后发现cpu成为瓶颈,也是我们当下面临的最大的问题,很多的查询都会跑满CPU,怎么优化CPU也是我们下一个要考虑的问题,我们看到今年9月Meta发布的Velox的论文,用C++重写了Presto的worker,在内部测试集中取得很好效果,这也是后面我们要去探索的地方。最后IO和CPU优化差不多的时候,就会发现网络可能会存在性能问题,那么只能进行架构调整,然后开始第二轮的优化。
后续我们将针对Presto结合HUDI查询进行更多的探索。
在开放性上,我们会接入更多的业务场景,来提升我们的业务价值。