














本文总结前期某个系统中使用到的缓存使用经验---仅此而已,效果还不错。
缓存技术在系统架构设计中扮演着至关重要的角色,它不仅可以显著提高系统的性能,还可以改善用户体验。在本文章中,我们将探讨不同类型的缓存、缓存失效以及缓存淘汰等关键概念,帮助在后期的架构设计中更好地理解如何利用缓存来优化你的系统。
一、缓存类型
缓存的类型有很多种,我们来简单聊聊其中的几种:
- 应用服务器缓存: 在这种情况下,缓存会被放在应用服务器的请求节点上,就像是服务器自己的小本子一样。每当有请求到达这个节点,它都会先看看自己本地有没有相关的数据,如果有,就直接返回这个数据,不用再费力去找了。如果本地没有,那就得去硬盘上找一下,并把找到的数据也存起来,以备将来使用。
- 分布式缓存: 在一个大型系统中,有可能有很多请求节点的实例在一起工作,负载均衡器负责将请求分散到这些节点上。问题是,每个节点都有自己的缓存,如果一个请求到达了一个节点,而这个请求的响应已经被其他节点处理过了,那么这个节点就会找不到缓存,需要重新查找。这会导致同一个请求被处理多次,浪费资源。解决这个问题的方法就是使用分布式缓存,让所有的节点共享一个缓存,这样就不会重复计算了。
- 全局缓存: 全局缓存其实就是分布式缓存的一种,它是一个大家都能访问的共享缓存,不管请求到达哪个节点,都可以从这个全局缓存中获取数据。这样就能避免重复计算,提高系统的性能。
- CDN(内容分发网络): CDN是一种将数据分布到全球各地的缓存系统。当用户请求某个内容时,CDN会将数据提供给离用户最近的服务器,这样可以加速访问速度,减轻源服务器的负载。CDN通常用于加速静态资源如图片、视频等的传输,让用户能够更快速地获取这些内容。
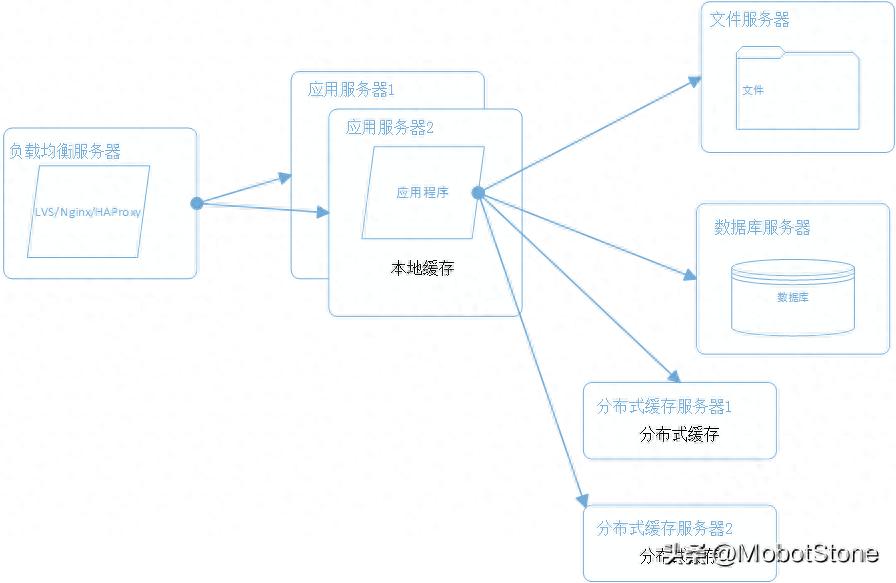
1、应用服务器缓存
在应用程序服务器中,我们经常使用缓存来提高性能。简单来说,缓存就是将一些数据存储在服务器的内存或磁盘上,以便在需要时快速获取,而不必每次都从头开始计算或查询数据库。
具体来说,应用程序服务器缓存是将缓存放在请求节点(服务器)本身上的一种方式。每当有请求到达这个服务器时,它会首先检查自己的本地缓存,如果能找到对应的响应数据,就会直接返回给客户端,避免了重复计算或者数据库查询的开销。如果本地缓存中没有需要的数据,服务器则会去查询磁盘或其他数据源,并将查询结果缓存起来,以备将来使用。
然而,当我们处于一个分布式环境中,有多个实例的同一请求节点时,会出现一个问题。通常,负载均衡器会将请求分发到这些不同的节点上,每个节点都有自己的本地缓存存储。这就可能导致一个问题:当一个请求到达某个节点,而该请求的响应已经被其他节点处理并缓存时,当前节点会出现缓存未命中的情况。这时,当前节点不得不再次查询磁盘并将响应数据存储在自己的本地缓存中。如果后续的请求又被分发到不同的节点,就会导致同一个请求被多次计算,浪费了资源和时间。
为了解决这个问题,我们可以采取维护一个分布式或全局缓存的方法。这意味着所有的请求节点共享同一个缓存,不管请求到达哪个节点,都可以从这个全局缓存中获取数据,避免了重复计算和减轻了系统负担。这种方式可以提高性能,并使系统更加高效。
2、分布式缓存
在分布式缓存中,缓存被分散存储在多个节点上,这是为了提高性能和可伸缩性。
为了有效地管理这些分布式缓存节点,我们使用一种叫做一致性哈希的技术。一致性哈希的好处是,它让哈希函数与多个缓存节点或对象独立无关,这意味着我们可以轻松地添加新的缓存节点到缓存池中,而不必担心影响已有的数据。
当有请求到来时,请求节点会使用一致性哈希算法来确定在哪个缓存节点上查找需要的缓存数据。这种方法使得我们可以灵活地扩展缓存集群,以容纳更多的缓存节点,从而提高系统的性能和可用性。简而言之,一致性哈希是分布式缓存中的一项关键技术,让我们能够更好地管理和利用缓存资源。
3、全局缓存:
在全局缓存中,我们只需维护一个全局的缓存,而不是每个请求节点都有自己的缓存。这样做的好处是能够更有效地利用缓存资源。
当缓存未命中时,有两种方式来获取数据:
- Global Cache 查询磁盘并缓存数据: 首先,我们可以从全局缓存查询数据,如果数据在全局缓存中不存在,那么我们就需要去磁盘或其他数据源中查询,并将查询到的数据缓存在全局缓存中,以备将来使用。这种方式是一种主动的数据获取方式。
- 全局缓存调用请求节点,然后缓存来自该节点的响应: 另一种方式是通过全局缓存调用具体的请求节点,然后将从该节点获取到的响应数据进行缓存。这种方式是一种被动的数据获取方式,只有在需要时才会触发。这也意味着我们可以将缓存的数据与请求节点的响应关联起来,以提高效率和性能。
总之,在全局缓存中,我们可以选择不同的方式来处理缓存未命中的情况,具体取决于系统的需求和设计。这样的全局缓存策略有助于提高数据访问效率,减少资源浪费。
4、CDN(内容分布式网络):
CDN(内容分发网络)是一个很有用的东西,特别适合在你的网站上有很多静态媒体文件的情况下使用。
CDN的工作原理很简单,当它发现缓存中没有用户请求的内容时,它会主动去向后端服务器请求这些数据,然后将数据缓存起来,以后再有用户请求相同的内容时,就可以快速地提供服务,不必再次向后端服务器请求。
如果系统还不够大,不需要使用大型CDN服务,你也可以考虑将静态文件托管在类似Nginx这样的简单HTTP服务器上。然后,将DNS托管在CDN服务中,而不是本地服务器上。这种方式可以帮助你在未来轻松地进行过渡,逐步扩大系统规模。简单说,CDN是一个实用的解决方案,可以帮助提升网站性能和用户体验。
二、缓存失效
缓存失效是确保缓存与数据源(通常是数据库)保持一致的重要策略。当数据源最近发生写操作时,我们需要确保缓存中的数据也跟得上变化。
有几种缓存失效的方式:
- 同时写入缓存和数据库: 在这个方案中,数据会同时写入缓存和数据库。这样做的好处是,即使系统崩溃、电源故障或其他系统中断,数据都不会丢失,因为它已经被保存在了缓存和数据库中。但是,当有大量写入操作时,同时在缓存和数据库中更新数据可能会导致延迟问题。
- 绕过缓存写入: 这个方案中,数据直接写入永久存储,而不经过缓存。这有助于避免写入操作淹没缓存的问题,但最近的写入可能会导致缓存未命中,需要请求节点去查询永久存储并缓存响应。
- 回写式缓存: 在这个方案中,写入操作首先完成到缓存中,然后立即向客户端确认完成。随后,经过一定的时间间隔,数据再更新到永久存储中。这种方式适用于写入密集型应用程序,它能提供高吞吐量和低延迟。但缺点是如果系统发生故障或其他不良事件,可能会导致数据丢失。
选择哪种缓存失效策略通常取决于你的应用需求和对数据一致性和可靠性的要求。不同的应用场景可能需要不同的策略来平衡性能和数据保护。
三、缓存淘汰(Cache Eviction)
当缓存达到容量上限时,需要清理缓存以腾出空间,以便存放新的数据。
有多种缓存清理策略:
- FIFO(先进先出): 这个策略会优先清理最早进入缓存的数据,而不考虑它们被访问的频率。
- LIFO(后进后出): 与FIFO相反,这个策略会优先清理最晚进入缓存的数据,也不考虑它们的访问频率。
- LRU(最近最少使用): LRU策略选择清理最长时间未被访问的缓存数据,确保缓存中保留最近被频繁访问的数据。
- MRU(最近使用): 与LRU相反,MRU策略会清理最近被使用的缓存数据,而不考虑它们的访问频率。
- LFU(最不常用): LFU策略维护了缓存数据被访问的频率,然后选择清理其中使用最少的数据。
- 随机替换: 这种策略随机选择一个缓存项,并在需要时将其清除以腾出空间。
选择哪种清理策略通常取决于你的应用需求和性能要求。不同的策略适用于不同的场景,帮助你在缓存满时有效地管理和清理数据。















