













译者 | 朱先忠
审校 | 重楼
摘要:在本博客中,我们将了解一种名为检索增强生成(retrieval augmented generation)的提示工程技术,并将基于Langchain、ChromaDB和GPT 3.5的组合来实现这种技术。
动机
随着GPT-3等基于转换器的大数据模型的出现,自然语言处理(NLP)领域取得了重大突破。这些语言模型能够生成类似人类的文本,并已有各种各样的应用程序,如聊天机器人、内容生成和翻译等。然而,当涉及到专业化和特定于客户的信息的企业应用场景时,传统的语言模型可能满足不了要求。另一方面,使用新的语料库对这些模型进行微调可能既昂贵又耗时。为了应对这一挑战,我们可以使用一种名为“检索增强生成”(RAG:Retrieval Augmented Generation)的技术。
在本博客中,我们将探讨这种检索增强生成(RAG)技术是如何工作的,并通过一个实战示例来证明这一技术的有效性。需要说明的是,此实例将使用GPT-3.5 Turbo作为附加语料库对产品手册进行响应。
想象一下,你的任务是开发一个聊天机器人,该机器人可以响应有关特定产品的查询。该产品有自己独特的用户手册,专门针对企业的产品。传统的语言模型,如GPT-3,通常是根据一般数据进行训练的,可能不了解这种特定的产品。另一方面,使用新的语料库对模型进行微调似乎是一种解决方案;然而,此办法会带来相当大的成本和资源需求。
检索增强生成(RAG)简介
检索增强生成(RAG)提供了一种更高效的方法来解决在特定领域生成上下文适当的响应的问题。RAG没有使用新的语料库对整个语言模型进行微调,而是利用检索的能力按需访问相关信息。通过将检索机制与语言模型相结合,RAG通过结合外部上下文来增强响应。这个外部上下文可以作为向量嵌入来提供。
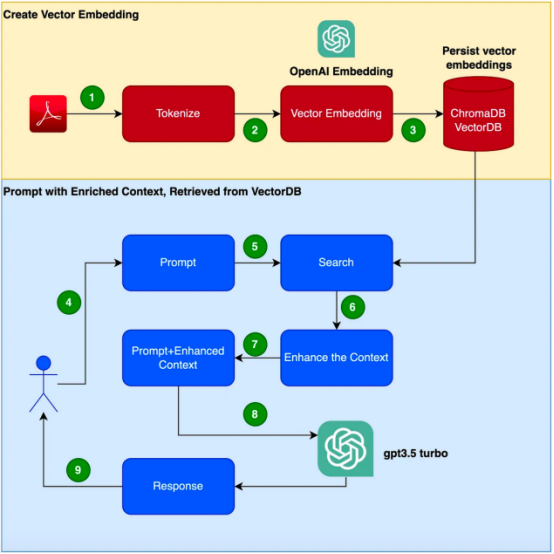
下面给出了创建本文中应用程序时需要遵循的步骤流程。
- 阅读Clarett用户手册(PDF格式)并使用1000个令牌的chunk_size进行令牌化。
- 创建这些标记的向量嵌入。我们将使用OpenAIEmbeddings库来创建向量嵌入。
- 将向量嵌入存储在本地。我们将使用简单的ChromaDB作为我们的VectorDB。我们可以使用Pinecone或任何其他更高可用性的生产级的向量数据库VectorDB。
- 用户发出带有查询/问题的提示。
- 这将从VectorDB中进行搜索和检索,以便从VectorDB中获取更多上下文数据。
- 此上下文数据现在将与提示内容一起使用。
- 上下文增强了提示,这通常被称为上下文丰富。
- 提示信息,连同查询/问题和这个增强的上下文,现在被传递给大型语言模型LLM。
- 至此,LLM基于此上下文进行响应。
需要说明的是,在本示例中,我们将使用Focusrite Clarett用户手册作为附加语料库。Focusrite Clarett是一个简单的USB音频接口,用于录制和播放音频。您可以从链接https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett%208Pre%20USB%20User%20Guide%20V2%20English%20-%20EN.pdf处下载使用手册。
实战演练
设置虚拟环境
让我们设置一个虚拟环境来把我们的实现案例封装起来,以避免系统中可能出现的任何版本/库/依赖性冲突。现在,我们执行以下命令来创建一个新的Python虚拟环境:
创建OpenAI密钥
接下来,我们将需要一个OpenAI密钥来访问GPT。让我们创建一个OpenAI密钥。您可以通过在链接https://platform.openai.com/apps处注册OpenAI来免费创建OpenAIKey。
注册后,登录并选择API选项,如屏幕截图所示(时间原因所致,当您打开该屏幕设计时可能会与我当前拍摄屏幕截图有所变化)。

然后,转到您的帐户设置并选择“查看API密钥(View API Keys)”:
然后,选择“创建新密钥(Create new secret key)”,你会看到一个弹出窗口,如下图所示。你需要提供一个名称,这将会生成一个密钥。
该操作将生成一个唯一的密钥,您应该将其复制到剪贴板并存储在安全的地方。
接下来,让我们编写Python代码来实现上面流程图中显示的所有步骤。
安装依赖库
首先,让我们安装我们需要的各种依赖项。我们将使用以下库:
- Lanchain:一个开发LLM应用程序的框架。
- ChromaDB:这是用于持久化向量嵌入的VectorDB。
- unstructured:用于预处理Word/PDF文档。
- Tiktoken:Tokenizer框架
- pypdf:阅读和处理PDF文档的框架
- openai:访问openai的框架
一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。
接下来,让我们开始编程。
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
在下面的代码中,我们将导入所有将要使用的依赖库和函数。
在下面的代码中,阅读PDF,将文档标记化并拆分为标记。
在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。
执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。
现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。
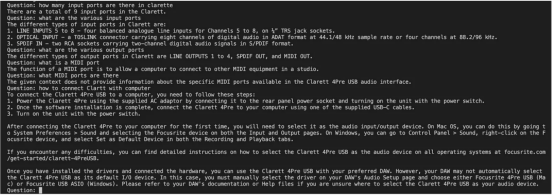
既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。
这是输出的屏幕截图。

小结
正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar































