












当集群资源不足时,Cluster Autoscaler会提供新节点并将其加入集群。使用Kubernetes时你可能会注意到,创建节点并将其加入集群的过程可能需要花费数分钟。在这段时间里,应用程序很容易被连接淹没,因为已经无法进一步扩展了。
延伸阅读,了解Akamai cloud-computing
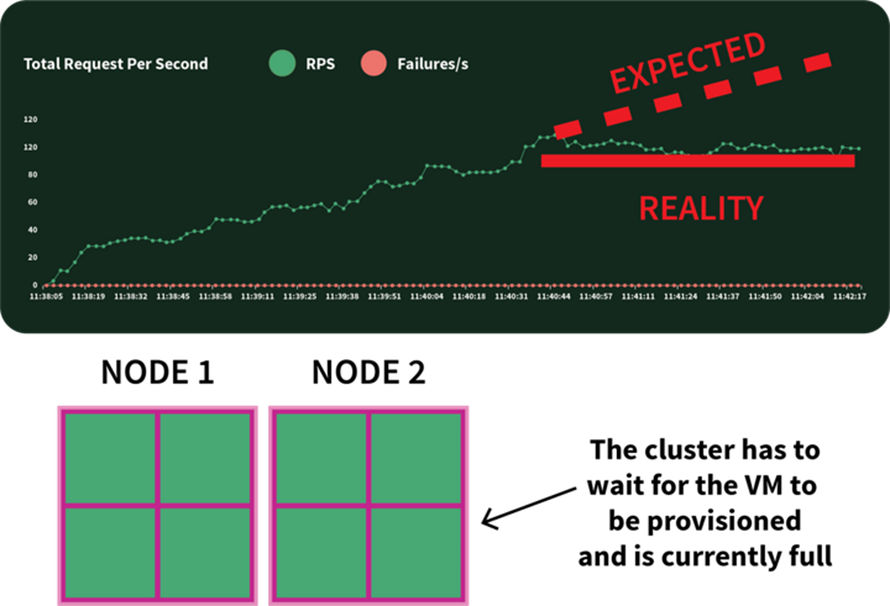
虚拟机的配置可能需要花费数分钟,在这期间可能无法扩展应用
如何消除如此长的等待时间?
主动扩展(Proactive scaling),或者:
- 理解集群Autoscaler的工作原理并最大限度提升其效用;
- 使用Kubernetes scheduler为节点分配另一个Pod;以及
主动配置工作节点,以改善扩展效果。注意:本文涉及的所有代码都已发布至LearnK8s GitHub。
Cluster Autoscaler如何在Kubernetes中生效
Cluster Autoscaler在触发自动扩展时并不检查内存或CPU的可用数,而是会对事件作出反应,检查所有不可调度的Pod。当调度器找不到能容纳某个Pod的节点时,我们就说这个Pod是不可调度的。
我们可以这样创建一个集群来测试看看。
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig请留意下列细节:
- 每个节点有4GB内存和2个vCPU(例如“g6-standard-2”实例)
- 集群中只有一个节点,并且
- Cluster autoscaler被配置为从1个节点扩展至10个节点我们可以用下列命令验证安装已成功完成:
bash
$ kubectl get pods -A --kubecnotallow=kubeconfig用环境变量导出kubeconfig文件通常是一种很方便的做法,为此我们可以运行:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get pods部署应用程序
让我们部署一个需要1GB内存和250m* CPU的应用程序。
注意:m = 内核的千分之一容量,因此250m = CPU的25%容量。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250m用下列命令将资源提交至集群:bash$ kubectl apply -f podinfo.yaml随后很快会发现一些情况。首先,三个Pod几乎会立即开始运行,另有一个Pod处于“未决”状态。
随后很快:
- 几分钟后,Autoscaler创建了一个额外的Pod,并且
- 第四个Pod会被部署到一个新节点中。

最终,第四个Pod被部署到一个新节点中
第四个Pod为何没有部署到第一个节点中?让我们一起看看已分配的资源。
Kubernetes节点中资源的分配
Kubernetes集群中部署的Pod会消耗内存、CPU以及存储资源。而且在同一个节点上,操作系统和Kubelet也需要消耗内存和CPU。
在Kubernetes工作节点上,内存和CPU会被拆分为:
- 运行操作系统和系统守护进程(如SSH、Systemd等)所需的资源。
- 运行Kubernetes代理程序(如Kubelet、容器运行时以及节点故障检测程序等)所需的资源。
- 可用于Pod的资源。
- 为排空阈值(Eviction threshold)保留的资源。
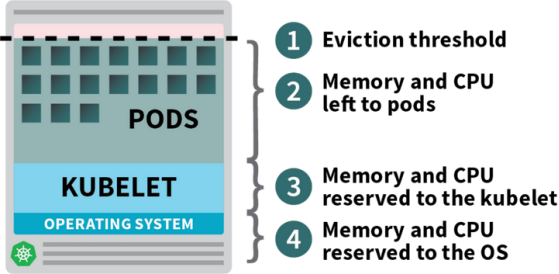
Kubernetes节点中分配和保留的资源
如果集群运行了DaemonSet(如kube-proxy),那么可用内存和CPU数量还将进一步减少。
那么我们不妨降低需求,以确保能将所有Pod都放入同一个节点中:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPU我们可以使用下列命令修改这个部署
bash
$ kubectl apply -f podinfo.yaml选择恰当数量的CPU和内存以优化实例的运行,这是个充满挑战的工作。Learnk8s计算器工具可以帮助我们更快速地完成这项工作。
一个问题解决了,但是创建新节点花费的时间呢?
迟早我们会需要四个以上的副本,我们是否真的需要等待好几分钟,随后才能创建新的Pod?
简单来说:是的!Linode必须从头开始创建和配置新虚拟机,随后将其连接到集群。这个过程经常会超过两分钟。
但其实还有替代方案:我们可以在需要时主动创建已经配置好的节点。
例如:我们可以配置让Autoscaler始终准备好一个备用节点。当Pod被部署到备用节点后,Autoscaler可以主动创建另一个备用节点。然而Autoscaler并没有内置这样的功能,但我们可以很容易地重新创建。
我们可以创建一个请求数与节点资源相等的Pod:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8G
用下列命令将资源提交至集群:
bash
kubectl apply -f placeholder.yaml这个Pod完全不执行任何操作。
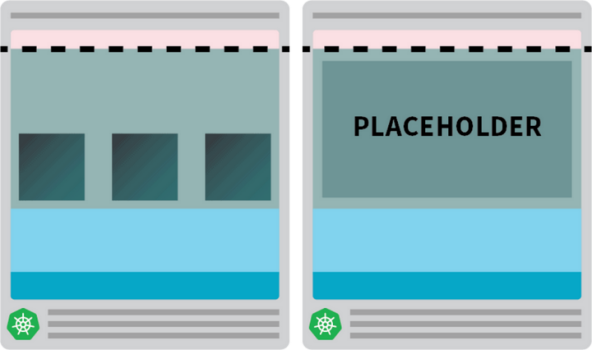
用占位Pod保护节点上的所有资源
该节点的作用只是确保节点能够被充分使用起来。
随后还需要确保当工作负载需要扩展时,这个占位Pod能够被快速清除。为此我们可以使用Priority Class。
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8G用下列命令将其提交至集群:
bash
kubectl apply -f placeholder.yaml至此,配置工作已全部完成。
我们可能需要等待一会让Autoscaler创建节点,随后我们将有两个节点:
- 一个包含四个Pod的节点
- 一个包含一个占位Pod的节点
如果将部署扩展为5个副本会怎样?是否要等待Autoscaler创建另一个新节点?
用下列命令测试看看吧:
bash
kubectl scale deployment/podinfo --replicas=5我们将会看到:
- 第五个Pod会立即创建出来,并在10秒内变为“正在运行”的状态。
- 占位Pod会被清除,以便为第五个Pod腾出空间。
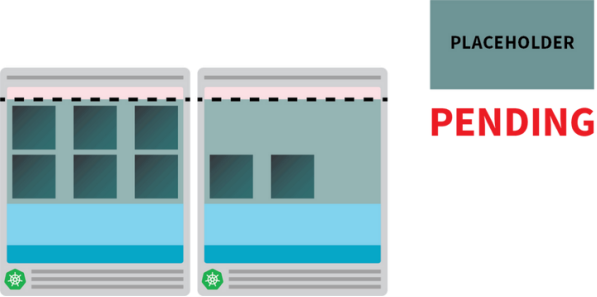
占位Pod会被清除,以便为常规Pod腾出空间
随后:
- Cluster autoscaler会注意到未决的占位Pod并配置一个新的节点。
- 占位Pod会被部署到新创建的节点中。
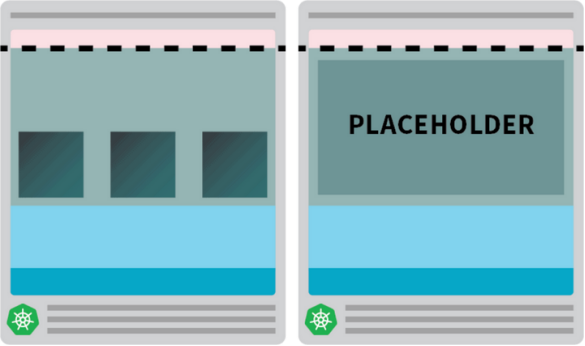
未决的Pod触发了Cluster autoscaler新建节点
在可以有更多节点时,为何又要主动创建出一个节点?
我们可以将占位Pod扩展到多个副本,每个副本都会预配置一个Kubernetes节点,准备接受标准工作负载。然而这些节点虽然是闲置的,但它们产生的费用依然会计入云服务账单。因此一定要慎重,不要创建太多节点。
将Cluster Autoscaler与Horizontal Pod Autoscaler配合使用
为理解这项技术的含义,我们可以将Cluster autoscaler和Horizontal Pod Autoscaler(HPA)结合在一起来看。HPA可用于提高部署中的副本数量。
随着应用程序收到越来越多流量,我们可以让Autoscaler调整处理请求的副本数量。当Pod耗尽所有可用资源后,会触发Cluster autoscaler新建一个节点,
这样HPA就可以继续创建更多副本。
可以这样新建一个集群来测试上述效果:
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpa用下列命令验证安装过程已成功完成:
bash
$ kubectl get pods -A --kubecnotallow=kubeconfig-hpa使用环境变量导出kubeconfig文件是一种方便的做法,为此我们可以运行:
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get pods接下来使用Helm安装Prometheus并查看该部署的相关指标。我们可以在官网上了解安装Helm的详细方法。
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusKubernetes为HPA提供了一个控制器,借此可以动态增减副本数量。然而HPA也有一些局限性:
- 无法拆箱即用。需要安装Metrics Server来汇总并暴露出指标。
- PromQL查询无法做到拆箱即用。
好在我们可以使用KEDA,它通过一些实用功能(包括从Prometheus读取指标)扩展了HPA控制器的用法。KEDA是一种Autoscaler,可适用于下列三个组件:
- Scaler
- Metrics Adapter
- Controller
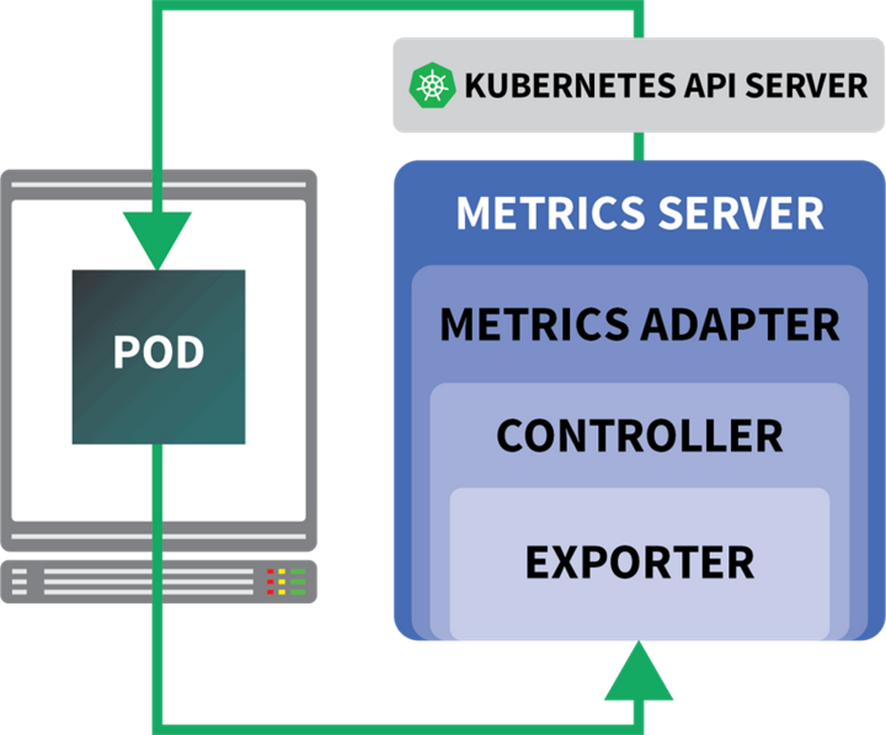
KEDA架构
我们可以通过Helm安装KEDA:
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda安装好Prometheus和KEDA之后,来创建一个部署吧。
在这个实验中,我们将使用一个每秒可以处理固定数量请求的应用。每个Pod每秒最多可以处理十个请求,如果Pod收到第11个请求,会将请求挂起,稍后再处理。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfo
使用下列命令将资源提交至集群:
bash
$ kubectl apply -f rate-limiter.yaml为了生成一些流量,我们可以使用Locust。下列YAML定义将创建一个分布式负载测试集群:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script运行下列命令将其提交至集群:
bash
$ kubectl locust.yamlLocust会读取下列locustfile.py文件,该文件存储在一个ConfigMap中:
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")该文件并没有什么特别的作用,只是向一个URL发出请求。若要连接至Locust仪表板,我们需要提供其负载均衡器的IP地址。为此可使用下列命令获取地址:
bash
$ kubectl get service locust -o jsnotallow='{.status.loadBalancer.ingress[0].ip}'随后打开浏览器并访问该IP地址即可。
此外还需要注意一个问题:Horizontal Pod Autoscaler。KEDA autoscaler会用一个名为ScaledObject的特殊对象来封装Horizontal Autoscaler。
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA可以连接由Prometheus收集的指标,并将其发送给Kubernetes。最后,它还将使用这些指标创建一个Horizontal Pod Autoscaler (HPA)。
我们可以用下列命令手工检查HPA:
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfo并使用下列命令提交该对象
bash
$ kubectl apply -f scaled-object.yaml接下来可以测试扩展效果了。请在Locust仪表板中用下列设置启动一项实验:
- Number of users:300
- Spawn rate:0.4
- Host:http://podinfo
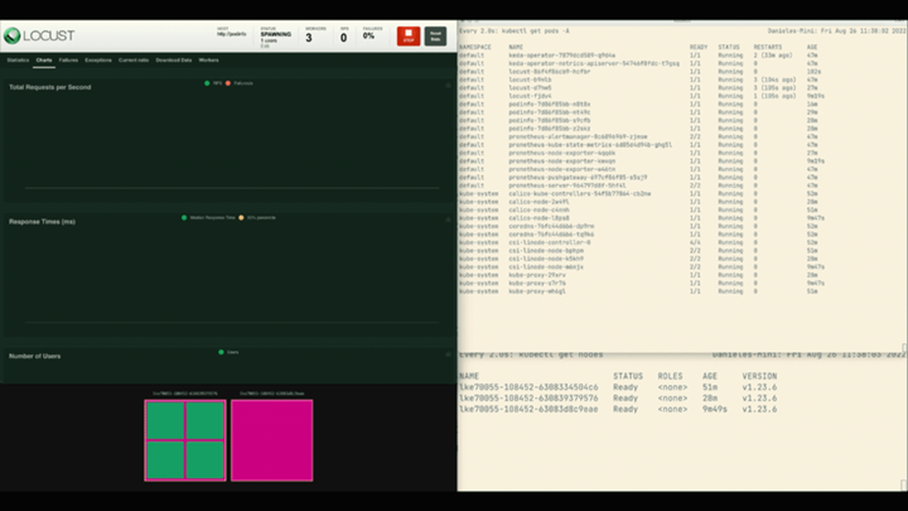
集群和Horizontal pod autoscaler的结合
可以看到,副本的数量增加了!
效果不错,但有个问题不知道你是否注意到。
当该部署扩展到8个Pod后,需要等待几分钟,随后才能在新节点中创建新的Pod。在这段时间里,每秒处理的请求数量也不再增加了,因为当前的8个副本每个都只能处理10个请求。
让我们试试看收缩容量并重复该实验:
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove pods这次,我们将用一个占位Pod实现超量配置(Overprovision):
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9G运行下列命令将其提交至集群:
bash
kubectl apply -f placeholder.yaml打开Locust仪表板并用下列设置重复实验:
- Number of users:300
- Spawn rate:0.4
- Host:http://podinfo
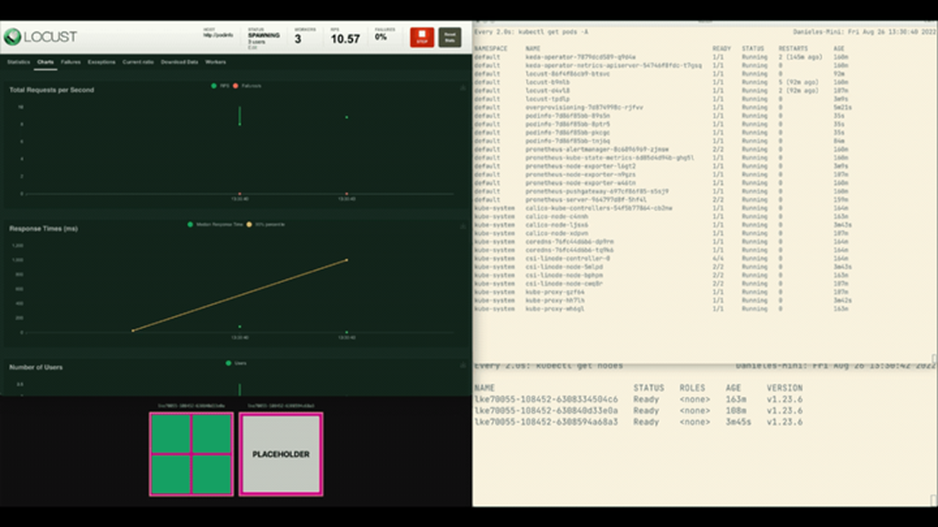
在超量配置的情况下进行集群和Horizontal pod autoscaler的结合
这一次,新节点将在后台创建,每秒请求数量将持续增减,不会原地踏步。很棒!
总结
本文介绍了下列内容:
- Cluster autoscaler并不追踪CPU或内存用量,而是会监控未决的Pod。
- 我们可以用可用内存和CPU的总量来创建一个Pod,从而主动配置Kubernetes节点。
- Kubernetes节点会为Kubelet、操作系统以及排空阈值保留一定的资源。
- 我们可以结合使用Prometheus和KEDA,从而通过PromQL查询扩展自己的Pod。
这篇文章的内容感觉还行吧?有没有想要立即在 Linode 平台上亲自尝试一下?别忘了,现在注册可以免费获得价值 100 美元的使用额度,快点自己动手体验本文介绍的功能和服务吧↓↓↓
出海云服务,选择Akamai Linode!
欢迎关注Akamai,第一时间了解高可用的MySQL/MariaDB参考架构,以及丰富的应用程序示例。



















