背景介绍
为了应对处理各类复杂音视频通信场景,如多设备、多人、多噪音场景,流媒体通信技术渐渐成为人们生活中不可或缺的技术。为达到更好的主观体验,使用户听得清、听得真,流媒体音频技术方案融合了传统机器学习和基于AI的语音增强方案,利用深度神经网络技术方案,在语音降噪、回声消除、干扰人声消除和音频编解码等方向,为实时通信中的音频质量保驾护航。
作为语音信号处理研究领域的旗舰国际会议,Interspeech一直代表着声学领域技术最前沿的研究方向,Interspeech 2023 收录了多篇和音频信号语音增强算法相关的文章,其中,火山引擎流媒体音频团队共有 4 篇研究论文被大会接收,论文方向包括语音增强、基于AI编解码 、回声消除、无监督自适应语音增强。
值得一提的是,在无监督自适应语音增强领域,字节跳动与西工大联合团队在今年的CHiME (Computational Hearing in Multisource Environments) 挑战赛子任务无监督域自适应对话语音增强(Unsupervised domain adaptation for conversational speech enhancement, UDASE) 获得了冠军(https://www.chimechallenge.org/current/task2/results)。CHiME挑战赛是由法国计算机科学与自动化研究所、英国谢菲尔德大学、美国三菱电子研究实验室等知名研究机构所于2011年发起的一项重要国际赛事,重点围绕语音研究领域极具挑战的远场语音处理相关任务,今年已举办到第七届。历届CHiME比赛的参赛队伍包括英国剑桥大学、美国卡内基梅隆大学、约翰霍普金斯大学、日本NTT、日立中央研究院等国际著名高校和研究机构,以及清华大学、中国科学院大学、中科院声学所、西工大、科大讯飞等国内顶尖院校和研究所。
本文将介绍这 4 篇论文解决的核心场景问题和技术方案,分享火山引擎流媒体音频团队在语音增强,基于AI编码器,回声消除和无监督自适应语音增强领域的思考与实践。
基于可学习梳状滤波器的轻量级语音谐波增强方法
论文地址:https://www.isca-speech.org/archive/interspeech_2023/le23_interspeech.html
背景
受限于时延和计算资源,实时音视频通信场景下的语音增强,通常使用基于滤波器组的输入特征。通过梅尔和ERB等滤波器组,原始频谱被压缩至维度更低的子带域。在子带域上,基于深度学习的语音增强模型的输出是子带的语音增益,该增益代表了目标语音能量的占比。然而,由于频谱细节丢失,在压缩的子带域上增强的音频是模糊的,通常需要后处理以增强谐波。RNNoise和PercepNet等使用梳状滤波器增强谐波,但由于基频估计以及梳状滤波增益计算和模型解耦,它们无法被端到端优化;DeepFilterNet使用一个时频域滤波器抑制谐波间噪声,但并没有显式利用语音的基频信息。针对上述问题,团队提出了一种基于可学习梳状滤波器的语音谐波增强方法,该方法融合了基频估计和梳状滤波,且梳状滤波的增益可以被端到端优化。实验显示,该方法可以在和现有方法相当的计算量下实现更好的谐波增强。
模型框架结构
基频估计器(F0 Estimator)
为了降低基频估计难度并使得整个链路可以端到端运行,将待估计的目标基频范围离散化为N个离散基频,并使用分类器估计。添加了1维代表非浊音帧,最终模型输出为N+1维的概率。和CREPE一致,团队使用高斯平滑的特征作为训练目标,并使用Binary Cross Entropy作为损失函数:


可学习梳状滤波器(Learnable Comb Filter)
对上述每一个离散基频,团队均使用类似PercepNet的FIR滤波器进行梳状滤波,其可以表示为一个受调制的脉冲串:

在训练时使用二维卷积层(Conv2D)同时计算所有离散基频的滤波结果,该二维卷积的权重可以表示为下图矩阵,该矩阵有N+1维,每一维均使用上述滤波器初始化:

通过目标基频的独热标签和二维卷积的输出相乘得到每一帧基频对应的滤波结果:


谐波增强后的音频将和原始音频加权相加,并和子带增益相乘得到最后的输出:

在推断时,每一帧仅需要计算一个基频的滤波结果,因此该方法的计算消耗较低。
模型结构

团队使用双路卷积循环神经网络(Dual-Path Convolutional Recurrent Network, DPCRN)作为语音增强模型主干,并添加了基频估计器。其中Encoder和Decoder使用深度可分离卷积组成对称结构,Decoder有两个并行支路分别输出子带增益G和加权系数R。基频估计器的输入是DPRNN模块的输出和线性频谱。该模型的计算量约为300 M MACs,其中梳状滤波计算量约为0.53M MACs。
模型训练
在实验中,使用VCTK-DEMAND和DNS4挑战赛数据集进行训练,并使用语音增强和基频估计的损失函数进行多任务学习。


实验结果
流媒体音频团队将所提出的可学习梳状滤波模型和使用PercepNet的梳状滤波以及DeepFilterNet的滤波算法的模型进行对比,它们分别被称作DPCRN-CF、DPCRN-PN和DPCRN-DF。在VCTK测试集上,本文提出的方法相对现有方法均显示出优势。

同时团队对基频估计和可学习的滤波器进行了消融实验。实验结果显示,相对于使用基于信号处理的基频估计算法和滤波器权重,端到端学习得到的结果更优。

基于Intra-BRNN 和GB-RVQ 的端到端神经网络音频编码器
论文地址:https://www.isca-speech.org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
背景
近年来,许多神经网络模型被用于低码率语音编码任务,然而一些端到端模型未能充分利用帧内相关信息,且引入的量化器有较大量化误差导致编码后音频质量偏低。为了提高端到端神经网络音频编码器质量,流媒体音频团队提出了一种端到端的神经语音编解码器,即CBRC(Convolutional and Bidirectional Recurrent neural Codec)。CBRC使用1D-CNN(一维卷积) 和Intra-BRNN(帧内双向循环神经网络) 的交错结构以更有效地利用帧内相关性。此外,团队在CBRC中使用分组和集束搜索策略的残差矢量量化器(Group-wise and Beam-search Residual Vector Quantizer,GB-RVQ)来减少量化噪声。CBRC以20ms帧长编码16kHz音频,没有额外的系统延迟,适用于实时通信场景。实验结果表明,码率为3kbps的 CBRC编码语音质量优于12kbps的Opus。
模型框架结构

CBRC总体结构
Encoder和Decoder网络结构
Encoder采用4个级联的CBRNBlocks来提取音频特征,每个CBRNBlock由三个提取特征的ResidualUnit和控制下采样率的一维卷积构成。Encoder中特征每经过一次下采样则特征通道数翻倍。在ResidualUnit中由残差卷积模块和残差双向循环网络构成,其中卷积层采用因果卷积,而Intra-BRNN中双向GRU结构只处理20ms帧内音频特征。Decoder网络为Encoder的镜像结构,使用一维转置卷积进行上采样。1D-CNN和Intra-BRNN的交错结构使Encoder和Decoder充分利用20ms音频帧内相关性而不引入额外的延时。

CBRNBlock结构
分组和集束搜索残差矢量量化器 GB-RVQ
CBRC使用残差矢量量化器(Residual Vector Quantizer,RVQ)将编码网络输出特征量化压缩到指定比特率。RVQ以多层矢量量化器(Vector Quantizer,VQ)级联来压缩特征,每层VQ对前一层VQ量化残差进行量化,可显著降低同等比特率下单层VQ的码本参数量。团队在CBRC中提出了两种更优的量化器结构,即分组残差矢量量化器 (Group-wise RVQ) 和集束搜索残差矢量量化器(Beam-search RVQ)。
分组残差矢量量化器 Group-wise RVQ | 集束搜索残差矢量量化器 Beam-search RVQ |
|
|


Group-wise RVQ将Encoder输出进行分组,同时使用分组的RVQ对分组后特征进行独立量化,随后分组量化输出拼接输入Decoder。Group-wise RVQ以分组量化方式降低了量化器的码本参数量和计算复杂度,同时降低了CBRC端到端训练难度进而提升了CBRC编码音频质量。
团队将Beam-search RVQ引入到神经音频编码器端到端训练中,使用Beam-search算法选择RVQ中量化路径误差最小的码本组合,以降低量化器的量化误差。原RVQ算法在每层VQ量化中选择误差最小的码本为输出,但每层VQ量化最优的码本组合后不一定是全局最优码本组合。团队使用Beam-search RVQ,在每层VQ中以量化路径误差最小准则保留k个最优的量化路径,实现在更大的量化搜索空间中选择更优的码本组合,降低量化误差。
Beam-search RVQ算法简要过程: 1、每层VQ输入前层VQ的个候选量化路径,得到个候选量化路径。 2、从个候选量化路径中选择个量化路径误差最小的个量化路径作为当前VQ层输出。 3、在最后一层VQ中选择量化路径误差最小的路径作为量化器的输出。 |
|

模型训练
在实验中,使用LibriTTS数据集中245小时的16kHz语音进行训练,将语音幅度乘以随机增益后输入模型。训练中损失函数由频谱重建多尺度损失,判别器对抗损失和特征损失,VQ量化损失和感知损失构成。

实验结果
主客观得分
为了评估CBRC编码语音质量,构建了10条多语种音频对比集,在该对比集上与其他音频编解码器进行了对比。为了降低计算复杂的影响,团队设计了轻量化的CBRC-lite,其计算复杂度略高于Lyra-V2。由主观听感比较结果可知,CBRC在3kbps上语音质量超过了12kbps的Opus,同样超过了3.2kbps的Lyra-V2,这表明所提出方法的有效性。https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb中提供了CBRC编码后音频样音。
客观分 | 主观听感得分 |
|
|


消融实验
团队设计了针对Intra-BRNN、Group-wise RVQ 和 Beam-search RVQ的消融实验。实验结果表明在Encoder和Decoder使用Intra-BRNN均可明显提升语音质量。此外,团队统计了RVQ中码本使用频次并计算熵解码以对比不同网络结构下码本使用率。相比于全卷积结构,使用Intra-BRNN的CBRC将潜在编码比特率从4.94kbps提升到5.13kbps。同样,在 CBRC中使用Group-wise RVQ 和 Beam-search RVQ均能显著提升编码语音质量,且相比于神经网络本身的计算复杂度, GB-RVQ带来的复杂度增加几乎可忽略。


样音
原始音频
arctic_a0023_16k,字节跳动技术团队,5秒
es01_l_16k,字节跳动技术团队,10秒
CBRC 3kbps
arctic_a0023_16k_CBRC_3kbps,字节跳动技术团队,5秒
es01_l_16k_CBRC_3kbps,字节跳动技术团队,10秒
CBRC-lite 3kbps
arctic_a0023_16k_CBRC_lite_3kbps,字节跳动技术团队,5秒
es01_l_16k_CBRC_lite_3kbps,字节跳动技术团队,10秒
基于两阶段渐进式神经网络的回声消除方法
论文地址:https://www.isca-speech.org/archive/pdfs/interspeech_2023/chen23e_interspeech.pdf
背景
在免提通信系统中,声学回声是令人烦恼的背景干扰。当远端信号从扬声器播放出来,然后由近端麦克风记录时,就会出现回声。回声消除 (AEC) 旨在抑制麦克风拾取的不需要的回声。在现实世界中,有很多非常需要消除回声的应用,例如实时通信、智能教室 、车载免提系统等等。
最近,采用深度学习 (DL) 方法的数据驱动 AEC 模型已被证明更加稳健和强大 。这些方法将 AEC 表述为一个监督学习问题,其中输入信号和近端目标信号之间的映射函数通过深度神经网络 (DNN) 进行学习。然而,真实的回声路径极其复杂,这对 DNN 的建模能力提出了更高的要求。为了减轻网络的建模负担,大多数现有的基于 DL 的 AEC 方法采用一个前置的线性回声消除(LAEC) 模块来抑制大部分回声的线性分量。但是,LAEC 模块有两个缺点:1)不合适的 LAEC 可能会导致近端语音的一些失真,以及 2)LAEC 收敛过程使线性回声抑制性能不稳定。由于 LAEC 是自优化的,因此 LAEC 的缺点会给后续的神经网络带来额外的学习负担。
为了避免 LAEC 的影响并保持更好的近端语音质量,本文探索了一种新的基于端到端 DL 的两阶段处理模式,并提出了一种由粗粒度 (coarse-stage) 和细粒度 (fine-stage) 组成的两阶段级联神经网络(TSPNN) 用于回声消除任务。大量的实验结果表明,所提出的两阶段回声消除方法能够达到优于其他主流方法的性能。
模型框架结构
如下图所示,TSPNN 主要由三个部分组成:时延补偿模块 (TDC)、粗粒度处理模块 (coarse-stage) 和细粒度处理模块 (fine-stage)。TDC 负责对输入的远端参考信号 (ref) 和近端麦克风信号 (mic) 进行对齐,有利于后续模型收敛。coarse-stage 负责将大部分的回声 (echo) 和噪声 (noise) 从 mic 中去除,极大减轻后续 fine-stage 阶段模型学习负担。同时,coarse-stage 结合了语音活跃度检测 (VAD) 任务进行多任务学习,强化模型对近端语音的感知能力,减轻对近端语音的损伤。fine-stage 负责进一步消除残余回声和噪声,并结合邻居频点信息来较好地重构出近端目标信号。

为了避免独立优化每个阶段的模型而导致的次优解,本文采用级联优化的形式来同时优化 coarse-stage 和 fine-stage,同时松弛对 coarse-stage 的约束,避免对近端语音造成损伤。此外,为了让模型能够具有感知近端语音的能力,本发明引入了 VAD 任务进行多任务学习,在损失函数中加入 VAD 的 Loss。最终损失函数为:
其中 分别表示目标近端信号复数谱、coarse-stage 和 fine-stage 估计的近端信号复数谱;分别表示coarse-stage估计的近端语音活跃状态、近端语音活跃检测标签; 为一个控制标量,主要用于调节训练阶段对不同阶段的关注程度。本发明限制 来松弛对 coarse-stage 的约束,有效避免 coarse-stage 对近端的损伤。
实验结果
实验数据
火山引擎流媒体音频团队所提两阶段回声消除系统还与其他方法做了比较,实验结果表明,所提能够达到优于其他主流方法的效果。

具体例子
- 实验结果 Github 链接:https://github.com/enhancer12/TSPNN
- 双讲场景效果表现:

CHiME-7 无监督域自适应语音增强(UDASE)挑战赛冠军方案
论文地址:https://www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf
背景:
近年来,随着神经网络和数据驱动的深度学习技术的发展,语音增强技术的研究逐渐转向基于深度学习的方法,越来越多基于深度神经网络的语音增强模型被提出。然而这些模型大多基于有监督学习,都需要大量的配对数据进行训练。然而在实际场景中,无法同时收录到嘈杂场景的语音和与之配对的不受干扰的干净语音标签,通常采用数据仿真的形式,单独采集干净语音与各种各样的噪声,将其按照一定信噪比混合得到带噪音频。这导致了训练场景与实际应用场景的不匹配,模型性能在实际应用中有所下降。
为了更好的解决以上域不匹配问题,利用真实场景中大量无标签数据,无监督、自监督语音增强技术被提出。CHiME挑战赛赛道2旨在利用未标记的数据来克服在人工生成的标记数据上训练的语音增强模型因训练数据与实际应用场景的不匹配导致的性能下降问题,研究的重点在于如何借助目标域的无标签数据和集外的有标签数据来提升目标域的增强结果。
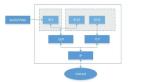
模型框架结构:

无监督域自适应语音增强系统流程图
如上图所示,所提框架是一个教师学生网络。首先在域内数据上使用语音活动检测、UNA-GAN、仿真房间冲击响应、动态加噪等技术生成最接近目标域的有标签数据集,在该域外有标签数据集上预训练教师降噪网络Uformer+。接着在域内无标签数据上借助该框架更新学生网络,即利用预训练的教师网络从带噪音频中估计干净语音和噪声作为伪标签,将他们打乱顺序重新混合作为学生网络输入的训练数据,利用伪标签有监督的训练学生网络。使用预训练的MetricGAN判别器估计学生网络生成的干净语音质量评分,并与最高分计算损失,以指导学生网络生成更高质量的干净音频。每训练一定步长后以一定权重将学生网络的参数更新到教师网络中,以获取更高质量的监督学习伪标签,如此重复。
Ufomer+网络
Uformer+是在Uformer网络基础上加入MetricGAN改进得到的。Uformer是一个基于 Unet 结构的复数实数双路径conformer网络,它具有两条并行的分支,幅度谱分支和复数谱分支,网络结构如下图所示。幅度分支用于进行主要的噪声抑制功能,能够有效抑制大部分噪声。复数分支作为辅助,用于补偿语谱细节和相位偏差等损失。MetricGAN的主要思想是使用神经网络模拟不可微的语音质量评价指标,使其可以被用于网络训练中,以减少训练和实际应用时评价指标不一致带来的误差。这里团队使用感知语音质量评价(PESQ)作为MetricGAN网络估计的目标。

Uformer网络结构图
RemixIT-G框架
RemixIT-G是一个教师学生网络,首先在域外有标签数据上预训练教师Uformer+模型,使用该预训练教师模型解码域内带噪音频,估计噪声和语音。接下来在同一批次内打乱估计的噪声和语音的顺序,重新将噪声和语音按打乱后的顺序混合成为带噪音频,作为训练学生网络的输入。由教师网络估计的噪声和语音作为伪标签。学生网络解码重混合的带噪音频,估计噪声和语音,与伪标签计算损失,更新学生网络参数。学生网络估计的语音被送入预训练的MetricGAN判别器中预测PESQ,并与PESQ最大值计算损失,更新学生网络参数。
所有训练数据完成一轮迭代后根据如下公式更新教师网络的参数:,其中为训练第K轮教师网络的参数, 为第K轮学生网络的参数。即将学生网络的参数以一定权重与教师网络相加。
数据扩充方法 UNA-GAN

UNA-GAN结构图
无监督噪声自适应数据扩充网络UNA-GAN是一种基于生成对抗网络的带噪音频生成模型。其目的是在无法获取独立的噪声数据的情况下,只使用域内带噪音频,直接将干净语音转化为带有域内噪声的带噪音频。生成器输入干净语音,输出仿真的带噪音频。判别器输入生成的带噪音频或真实的域内带噪音频,判断输入的音频来自真实场景还是仿真生成。判别器主要根据背景噪声的分布来区分来源,在这个过程中,人类语音被视为无效信息。通过执行以上对抗训练的过程,生成器试图将域内噪声直接添加在输入的干净音频上,以迷惑判别器;判别器试图尽力区分带噪音频的来源。为了避免生成器添加过多噪声,覆盖掉输入音频中的人类语音,使用了对比学习。在生成的带噪音频、和输入的干净语音对应位置采样256个块。相同位置的块的配对被视为正样例,不同位置的块的配对被视为负样例。使用正负样例计算交叉熵损失。
实验结果
结果表明所提出的Uformer+相比基线Sudo rm-rf具有更强的性能,数据扩充方法UNA-GAN也具有生成域内带噪音频的能力。域适应框架RemixIT基线在SI-SDR上取得了较大提升,但在DNS-MOS上指标较差。团队提出的改进RemixIT-G同时在两个指标上都取得了有效提升,并在竞赛盲测集上取得了最高的主观测听MOS打分。最终测听结果如下图所示。

总结与展望
上述介绍了火山引擎流媒体音频团队基于深度学习在特定说话人降噪,AI编码器,回声消除和无监督自适应语音增强方向做出的一些方案及效果,未来场景依然面临着多个方向的挑战,如怎么样在各类终端上部署运行轻量低复杂度模型及多设备效果鲁棒性,这些挑战点也将会是流媒体音频团队后续重点的研究方向。