2021年,华盛顿大学语言学家Emily M. Bender发表了一篇论文,认为大型语言模型不过是「随机鹦鹉」(stochastic parrots)而已,它们并不理解真实世界,只是统计某个词语出现的概率,然后像鹦鹉一样随机产生看起来合理的字句。
由于神经网络的不可解释性,学术界也弄不清楚语言模型到底是不是随机鹦鹉,各方观点差异分歧极大。
由于缺乏广泛认可的测试,模型是否能「理解世界」也成为了哲学问题而非科学问题。
最近,来自哈佛大学、麻省理工学院的研究人员共同发表了一项新研究Othello-GPT,在简单的棋盘游戏中验证了内部表征的有效性,他们认为语言模型的内部确实建立了一个世界模型,而不只是单纯的记忆或是统计,不过其能力来源还不清楚。

论文链接:https://arxiv.org/pdf/2210.13382.pdf
实验过程非常简单,在没有任何奥赛罗规则先验知识的情况下,研究人员发现模型能够以非常高的准确率预测出合法的移动操作,捕捉棋盘的状态。
吴恩达在「来信」栏目中对该研究表示高度认可,他认为基于该研究,有理由相信大型语言模型构建出了足够复杂的世界模型,在某种程度上来说,确实理解了世界。
博客链接:https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
不过吴恩达也表示,虽然哲学很重要,但这样的争论可能会无休无止,所以不如编程去吧!
棋盘世界模型
如果把棋盘想象成一个简单的「世界」,并要求模型在对局中不断决策,就可以初步测试出序列模型是否能够学习到世界表征。

研究人员选择一个简单的黑白棋游戏奥赛罗(Othllo)作为实验平台,其规则是在8*8棋盘的中心位置,先放入四个棋子,黑白各两个;然后双方轮流下子,在直线或斜线方向,己方两子之间的所有敌子(不能包含空格)全部变为己子(称为吃子),每次落子必须有吃子;最后棋盘全部占满,子多者为胜。
相比国际象棋来说,奥赛罗的规则简单得多;同时棋类游戏的搜索空间足够大,模型无法通过记忆完成序列生成,所以很适合测试模型的世界表征学习能力。
Othello语言模型
研究人员首先训练了一个GPT变体版语言模型(Othello-GPT),将游戏脚本(玩家做出的一系列棋子移动操作)输入到模型中,但模型没有关于游戏及相关规则的先验知识。
模型也没有被明确训练以追求策略提升、赢得对局等,只是在生成合法奥赛罗移动操作时准确率比较高。
数据集
研究人员使用了两组训练数据:
锦标赛(Championship)更关注数据质量,主要是从两个奥赛罗锦标赛中专业的人类玩家采用的、更具战略思考的移动步骤,但分别只收集到7605个和132921个游戏样本,两个数据集合并后以8:2的比例随机分成训练集(2000万个样本)和验证集(379.6万个)。
合成(Synthetic)更关注数据的规模,由随机的、合法的移动操作组成,数据分布不同于锦标赛数据集,而是均匀地从奥赛罗游戏树上采样获得,其中2000万个样本用于训练,379.6万个样本用于验证。
每场游戏的描述由一串token组成,词表大小为60(8*8-4)
模型和训练
模型的架构为8层GPT模型,具有8个头,隐藏维度为512
模型的权重完全随机初始化,包括word embedding层,虽然表示棋盘位置的词表内存在几何关系(如C4低于B4),但这种归纳偏置并没有明确表示出来,而是留给模型学习。
预测合法移动
模型的主要评估指标就是模型预测的移动操作是否符合奥赛罗的规则。
在合成数据集上训练的Othello-GPT错误率为0.01%,在锦标赛数据集上的错误率为5.17%,相比之下,未经训练的Othello-GPT的错误率为93.29%,也就是说这两个数据集都一定程度上让模型学会了游戏规则。
一个可能的解释是,模型记住了奥赛罗游戏的所有移动操作。
为了验证这个猜想,研究人员合成了一个新的数据集:在每场比赛开始时,奥赛罗有四种可能的开局棋位置(C5、D6、E3和F4),将所有C5开局的走法移除后作为训练集,再将C5开局的数据作为测试,也就是移除了近1/4的博弈树,结果发现模型错误率仍然只有0.02%
所以Othello-GPT的高性能并不是因为记忆,因为测试数据是训练过程中完全没见过的,那到底是什么让模型成功预测?
探索内部表征
一个常用的神经网络内部表征探测工具就是探针(probe),每个探针是一个分类器或回归器,其输入由网络的内部激活组成,并经过训练以预测感兴趣的特征。
在这个任务中,为了检测Othello-GPT的内部激活是否包含当前棋盘状态的表征,输入移动序列后,用内部激活向量对下一个移动步骤进行预测。
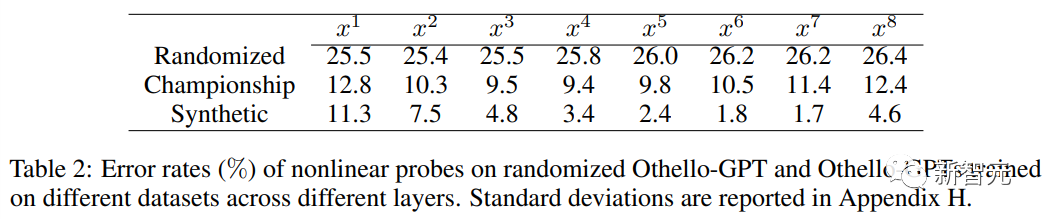
当使用线性探针时,训练后的Othello-GPT内部表征只比随机猜测的准确率高了一点点。

当使用非线性探针(两层MLP)时,错误率大幅下降,证明了棋盘状态并不是以一种简单的方式存储在网络激活中。
干预实验
为了确定模型预测和涌现世界表征之间的因果关系,即棋盘状态是否确实影响了网络的预测结果,研究人员进行了一组干预(intervention)试验,并测量由此产生的影响程度。
给定来自Othello-GPT的一组激活,用探针预测棋盘状态,记录相关联的移动预测,然后修改激活,让探针预测更新的棋盘状态。
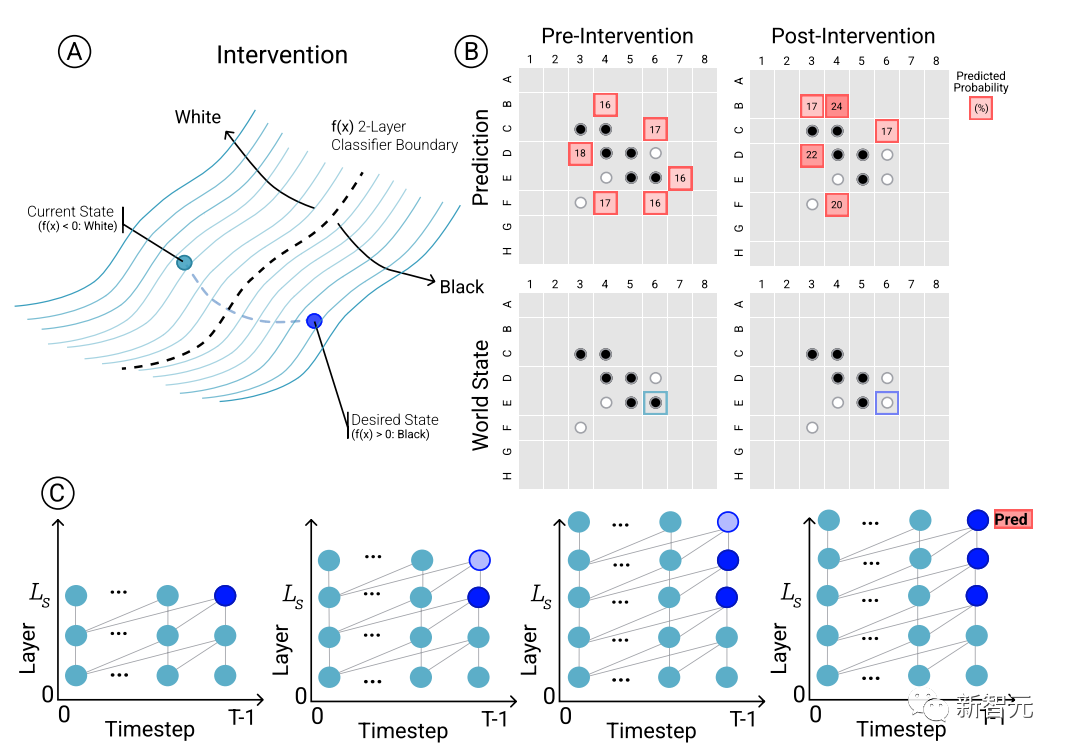
干预操作包括将某个位置的棋子从白色变成黑色等,一个小的修改就会导致模型结果发现内部表征能够可靠地完成预测,即内部表征与模型预测之间存在因果影响。
可视化
除了干预实验验证内部表征的有效性外,研究人员还将预测结果可视化,比如说对于棋盘上的每个棋子,可以询问模型如果用干预技术将该棋子改变,模型的预测结果将如何变化,对应预测结果的显著性。
然后根据当前棋盘状态的top1预测的显著性对牌进行着色可视化,因为绘制出来的图是基于网络的潜空间而输入,所以也可以叫做潜在显著性图(latent saliency map)。
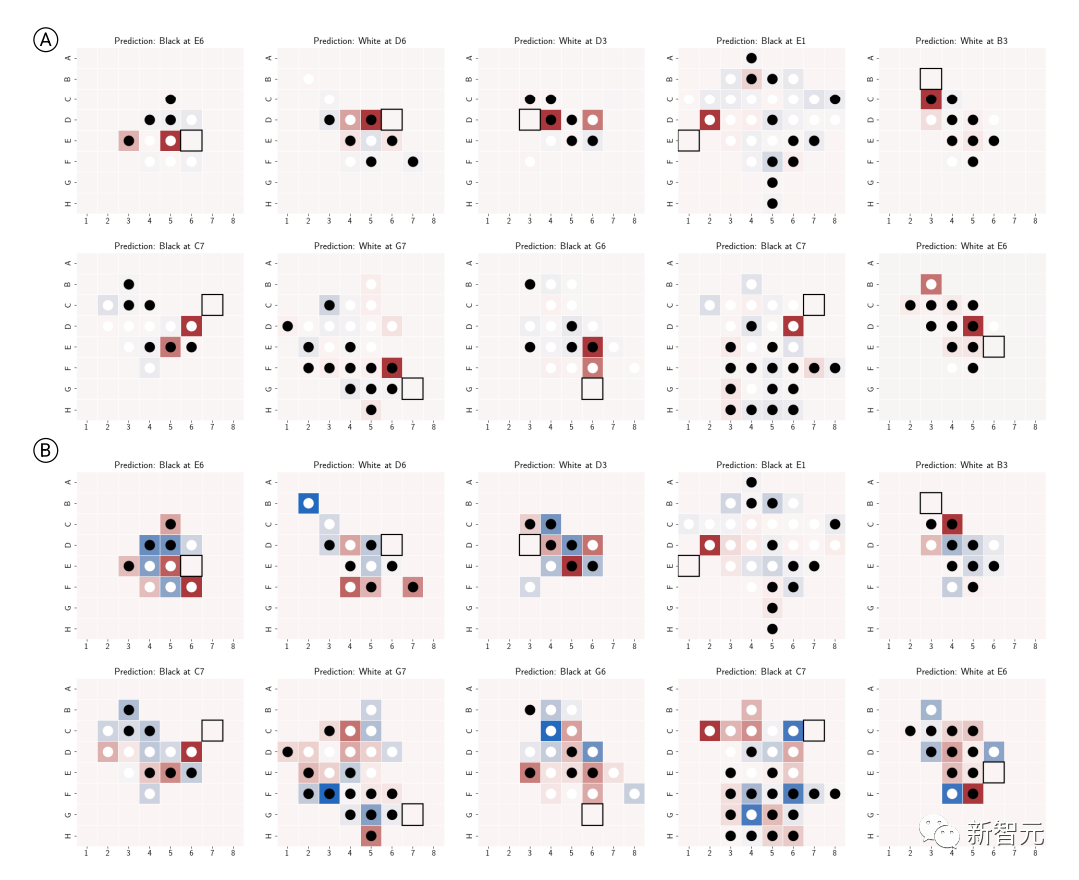
可以看到,在合成和锦标赛数据集上训练的Othello-GPTs的top1预测的潜显著性图中都展现出了清晰的模式。
合成版Othello-GPT在合法操作位置中显示出了更高的显著性值,非法操作的显著性值明显更低,稍微有点经验的棋手都能看出模型的意图;
锦标赛版的显著图更复杂,虽然合法操作位置的显著性值比较高,但其他位置也显示出较高的显著性,可能是因为奥赛罗高手考虑更多的是全局特征。