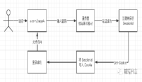
什么是网络爬虫?
网络爬虫是一种自动化程序,用于抓取互联网上的数据。网络爬虫可以自动访问网页、解析网页内容、提取所需数据、存储数据等。通过使用网络爬虫,我们可以获取大量的数据,从而进行数据分析、数据挖掘等应用。
网络爬虫的设计原则
在设计网络爬虫时,需要遵循以下原则:
- 遵守网站的规则。在抓取网站数据时,需要遵守网站的robots协议和使用条款等规定,不得未经授权地进行抓取。
- 考虑网络性能和资源消耗。在抓取网站数据时,需要考虑网络性能和资源消耗,避免对网站造成不必要的负担。
- 考虑数据质量和数据安全。在抓取网站数据时,需要考虑数据质量和数据安全,避免抓取到恶意数据或错误数据。
网络爬虫的实现
在实现网络爬虫时,需要遵循以下步骤:
- 确定目标网站。在抓取网站数据时,需要确定目标网站,并确定目标数据的类型和来源。
- 分析网站结构。在抓取网站数据时,需要分析网站结构,确定需要抓取的数据页面、数据位置、数据格式等。
- 编写抓取程序。在抓取网站数据时,需要编写抓取程序,包括访问网站、解析网页、提取数据等功能。
- 存储数据。在抓取网站数据时,需要存储数据,包括数据的格式、存储位置、存储方式等。
- 定期更新数据。在抓取网站数据时,需要定期更新数据,保证数据的及时性和准确性。
常用的网络爬虫API
在Python中,常用的网络爬虫API包括:
- requests库:用于发送HTTP请求和接收HTTP响应。例如,使用requests.get(url)来发送GET请求,使用requests.post(url, data)来发送POST请求。
- BeautifulSoup库:用于解析HTML和XML文档。例如,使用BeautifulSoup(html, 'html.parser')来解析HTML文档,使用BeautifulSoup(xml, 'xml')来解析XML文档。
- lxml库:用于解析HTML和XML文档。例如,使用lxml.html.parse(url)来解析HTML文档,使用lxml.etree.parse(url)来解析XML文档。
- re库:用于进行正则表达式匹配。例如,使用re.findall(pattern, string)来查找字符串中的所有匹配项,使用re.sub(pattern, repl, string)来替换字符串中的匹配项。
网络爬虫的实现示例
以下是一个使用Python和requests库实现网络爬虫的示例:
import requests
from bs4 import BeautifulSoup
url = 'https://www.python.org/'
# 发送HTTP请求
response = requests.get(url)
# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
# 提取数据
title = soup.title.string
links = [link.get('href') for link in soup.find_all('a')]
# 打印结果
print(title)
for link in links:
print(link)在上面的示例中,我们使用了requests库来发送HTTP请求和接收HTTP响应,使用了BeautifulSoup库来解析HTML文档。我们首先发送HTTP请求,然后解析HTML文档,使用soup.title.string来获取HTML文档中的标题,使用soup.find_all('a')来获取HTML文档中的所有链接,使用link.get('href')来获取链接的URL。最后,我们打印结果,包括标题和所有链接的URL。
爬取网络视频
我们可以使用Python和第三方库you-get来实现爬取网络视频的功能。you-get是一个开源命令行工具,用于从各种视频网站下载视频。
首先,我们需要安装you-get库。使用以下命令安装:
pip install you-get然后,我们可以使用以下代码来实现爬取网络视频的功能:
import subprocess
url = 'https://www.bilibili.com/video/BV1Kf4y1W7ND'
# 下载视频
subprocess.call(['you-get', '-o', 'videos', url])在上面的代码中,我们首先指定了要下载的视频的URL,然后使用subprocess.call函数调用you-get命令行工具来下载视频。我们指定了视频下载到videos文件夹中。
爬取网络歌曲
我们可以使用Python和第三方库requests和beautifulsoup4来实现爬取网络歌曲的功能。我们可以从音乐网站上获取歌曲的下载链接,并使用requests库下载歌曲。
以下是一个示例代码:
import requests
from bs4 import BeautifulSoup
url = 'https://music.163.com/#/song?id=1443868572'
# 发送HTTP请求
response = requests.get(url)
# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
# 获取歌曲下载链接
download_url = soup.find('a', {'class': 'u-btni u-btni-dl'})['href']
# 下载歌曲
response = requests.get(download_url)
with open('song.mp3', 'wb') as f:
f.write(response.content)在上面的代码中,我们首先指定了要下载的歌曲的URL,然后使用requests库发送HTTP请求并解析HTML文档。我们使用soup.find方法查找歌曲下载链接的HTML元素,并获取其href属性。然后,我们使用requests库下载歌曲,并将其保存到名为song.mp3的文件中。
爬取网络图片
我们可以使用Python和第三方库requests和beautifulsoup4来实现爬取网络图片的功能。我们可以从图片网站上获取图片的URL,并使用requests库下载图片。
以下是一个示例代码:
import requests
from bs4 import BeautifulSoup
url = 'https://www.douban.com/photos/album/160971840/'
# 发送HTTP请求
response = requests.get(url)
# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
# 获取图片URL列表
img_urls = [img['src'] for img in soup.find_all('img')]
# 下载图片
for img_url in img_urls:
response = requests.get(img_url)
with open('image.jpg', 'wb') as f:
f.write(response.content)在上面的代码中,我们首先指定了要下载的图片所在的URL,然后使用requests库发送HTTP请求并解析HTML文档。我们使用soup.find_all方法查找所有图片的HTML元素,并获取其src属性。然后,我们使用requests库下载图片,并将其保存到名为image.jpg的文件中。
以上就是三个使用Python编写的爬虫示例,分别用于爬取网络视频、网络歌曲和网络图片。请注意,这些示例代码仅供学习和参考。
总结
通过本文,您已经了解了Python网络爬虫的设计和实现。您现在应该能够使用Python和相关库来实现网络爬虫,包括常用的API(如requests、BeautifulSoup等)。