













译者 | 布加迪
审校 | 重楼
当我自学机器学习时,经常试着根据项目教程编写代码,我会按照作者概述的步骤来做。但有时候,我的模型的表现会比教程作者的模型要差。也许您也遇到过类似的情况。或者,您只是从GitHub拉取了同事的代码。而您模型的性能指标与同事的报告声称的性能指标不一样。所以做同样的事情并不能保证同样的结果,是不是?这是机器学习中一个普遍存在的问题:可再现性难题。
不用说,机器学习模型只有在别人可以复制试验并再现结果时才有用。从典型的“它在我的机器上工作”问题到机器学习模型训练方式的细微变化,可再现性存在几个挑战。
我们在本文中将仔细研究机器学习中可再现性的挑战和重要性,以及数据管理、版本控制和实验跟踪在解决机器学习可再现性挑战中的作用。
什么是机器学习背景下的可再现性?
不妨看看如何在机器学习的背景下最准确地定义可再现性。
假设一个现有的项目针对给定的数据集使用特定的机器学习算法。有了数据集和算法,我们应该能够运行算法(想运行多少次就运行多少次),并在每次运行时再现(或复制)结果。
但机器学习中的可再现性并非没有挑战。我们已经讨论了其中几个挑战,不妨在下一节中更详细地讨论它们。
机器学习中可再现性的挑战
任何应用环境都存在可靠性和可维护性等挑战。然而在机器学习应用中,还存在额外的挑战。
当我们谈论机器学习应用时,我们通常指端到端机器学习管道,它们通常包括以下步骤:
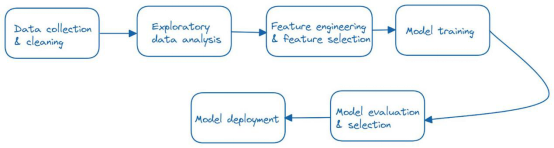
由于其中一个或多个步骤的变更,可能会出现可再现性问题。大多数变更都可以记录在下面其中一种变更中:
- 环境变更
- 代码变更
- 数据变更
不妨看看这每一种变更在如何阻碍可再现性。
环境变更
Python和基于Python的机器学习框架使得开发机器学习应用程序变得轻而易举。然而,Python中的依赖项管理(管理某个项目所需的不同库和版本)却并非易事。一个小小的变更就足以破坏代码,比如使用不同版本的库和使用被废弃的参数的函数调用。
这还包括操作系统的选择。存在与硬件相关的挑战,比如GPU浮点精度方面的差异等。
代码变更
从清洗输入数据集以确定哪些样本进入训练数据集,到训练神经网络时随机初始化权重,随机性在机器学习中扮演着重要作用。
设置不同的随机种子可能导致全然不同的结果。对于我们训练的每个模型,都有一组超参数。因此,调整一个或多个超参数也可能导致不同的结果。
数据变更
即便使用相同的数据集,我们也看到超参数值和随机性的不一致性如何使复制结果变得困难。因此,当数据发生变化(数据分布变化、记录子集的修改或丢弃某些样本)时,显然很难再现结果。
总之,当我们试图复制机器学习模型的结果时,哪怕是代码、所用的数据集和机器学习模型运行的环境出现小小的变化,也会阻止我们获得与原始模型相同的结果。
如何应对可再现性挑战?
现在我们看看如何应对这些挑战。
数据管理
我们发现可再现性最明显的挑战之一是数据方面。有某些数据管理方法(比如对数据集进行版本控制),这样我们就可以跟踪数据集变更,并存储数据集方面的有用元数据。
版本控制
应该使用Git之类的版本控制系统来跟踪代码的任何变更。
在现代软件开发中,您可能遇到过CI/CD管道,它们可以大大简化以下操作,并大大提高效率:跟踪变更、测试新变更,并将它们推送到生产环境。
在其他软件应用程序中,跟踪代码的变更简单直观。然而在机器学习中,代码变更还可能需要对所用的算法和超参数值进行更改。即使对于简单的模型,我们可以尝试的可能性的数量也非常多。这就是实验跟踪的意义所在。
实验跟踪
构建机器学习应用程序等同于进行广泛的试验。从算法到超参数,我们尝试不同的算法和超参数值,因此跟踪这些试验很重要。
跟踪机器学习试验包括如下:
- 记录超参数扫描
- 记录模型的性能指标和模型检查点
- 存储关于数据集和模型的实用元数据
用于机器学习实验跟踪和数据管理等操作的工具
如前所述,控制数据集版本、跟踪代码变更以及跟踪机器学习实验都可以复制机器学习应用程序。下面几个工具可以帮助您构建可再现的机器学习管道:
结语
综上所述,我们已回顾了机器学习中可再现性的重要性和挑战。我们讨论了数据和模型版本控制以及实验跟踪等方法。此外,我们还列出了一些可以用于实验跟踪和更有效的数据管理的工具。
原文标题:The Importance of Reproducibility in Machine Learning,作者:Bala Priya C


















