












过去十年间,仅靠简单的神经网络计算,以及大规模的训练数据支持,自然语言处理领域取得了相当大的突破,由此训练得到的预训练语言模型,如BERT、GPT-3等模型都提供了强大的通用语言理解、生成和推理能力。
前段时间,斯坦福大学大学教授Christopher D. Manning在Daedalus期刊上发表了一篇关于「人类语言理解和推理」的论文,主要梳理自然语言处理的发展历史,并分析了基础模型的未来发展前景。

论文链接:https://direct.mit.edu/daed/article/151/2/127/110621/Human-Language-Understanding-amp-Reasoning

论文作者Christopher Manning是斯坦福大学计算机与语言学教授,也是将深度学习应用于自然语言处理领域的领军者,研究方向专注于利用机器学习方法处理计算语言学问题,以使计算机能够智能处理、理解并生成人类语言。
Manning教授是ACM Fellow,AAAI Fellow 和ACL Fellow,他的多部著作,如《统计自然语言处理基础》、《信息检索导论》等都成为了经典教材,其课程斯坦福CS224n《深度学习自然语言处理》更是无数NLPer的入门必看。
NLP的四个时代
第一时代(1950-1969)
NLP的研究最早始于机器翻译的研究,当时的人们认为,翻译任务可以基于二战期间在码破译的成果继续发展,冷战的双方也都在开发能够翻译其他国家科学成果的系统,不过在此期间,人们对自然语言、人工智能或机器学习的结构几乎一无所知。
当时的计算量和可用数据都非常少,虽然最初的系统被大张旗鼓地宣传,但这些系统只提供了单词级的翻译查找和一些简单的、基于规则的机制来处理单词的屈折形式(形态学)和词序。
第二时代(1970-1992)
这一时期可以看到一系列NLP演示系统的发展,在处理自然语言中的语法和引用等现象方面表现出了复杂性和深度,包括Terry Winograd的SHRDLU,Bill Woods的LUNAR,Roger Schank的SAM,加里Hendrix的LIFER和Danny Bobrow的GUS,都是手工构建的、基于规则的系统,甚至还可用用于诸如数据库查询之类的任务。
语言学和基于知识的人工智能正在迅速发展,在这个时代的第二个十年,出现了新一代手工构建的系统,在陈述性语言知识和程序处理之间有着明确的界限,并且受益于语言学理论的发展。
第三时代(1993-2012)
在此期间,数字化文本的可用数量显著提升,NLP的发展逐渐转为深度的语言理解,从数千万字的文本中提取位置、隐喻概念等信息,不过仍然只是基于单词分析,所以大部分研究人员主要专注于带标注的语言资源,如标记单词的含义、公司名称、树库等,然后使用有监督机器学习技术来构建模型。
第四时代(2013-现在)
深度学习或人工神经网络方法开始发展,可以对长距离的上下文进行建模,单词和句子由数百或数千维的实值向量空间进行表示,向量空间中的距离可以表示意义或语法的相似度,不过在执行任务上还是和之前的有监督学习类似。
2018年,超大规模自监督神经网络学习取得了重大成功,可以简单地输入大量文本(数十亿个单词)来学习知识,基本思想就是在「给定前几个单词」的情况下连续地预测下一个单词,重复数十亿次预测并从错误中学习,然后就可以用于问答或文本分类任务。
预训练的自监督方法的影响是革命性的,无需人类标注即可产生一个强大的模型,后续简单微调即可用于各种自然语言任务。
模型架构
自2018年以来,NLP应用的主要神经网络模型转为Transformer神经网络,核心思想是注意力机制,单词的表征计算为来自其他位置单词表征的加权组合。
Transofrmer一个常见的自监督目标是遮罩文本中出现的单词,将该位置的query, key和value向量与其他单词进行比较,计算出注意力权重并加权平均,再通过全连接层、归一化层和残差连接来产生新的单词向量,再重复多次增加网络的深度。
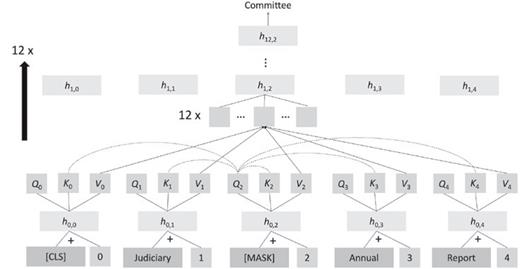
虽然Transformer的网络结构看起来不复杂,涉及到的计算也很简单,但如果模型参数量足够大,并且有大量的数据用来训练预测的话,模型就可以发现自然语言的大部分结构,包括句法结构、单词的内涵、事实知识等。
prompt生成
从2018年到2020年,研究人员使用大型预训练语言模型(LPLM)的主要方法就是使用少量的标注数据进行微调,使其适用于自定义任务。
但GPT-3(Generative Pre-training Transformer-3)发布后,研究人员惊讶地发现,只需要输入一段prompt,即便在没有训练过的新任务上,模型也可以很好地完成。
相比之下,传统的NLP模型由多个精心设计的组件以流水线的方式组装起来,先捕获文本的句子结构和低级实体,然后再识别出更高层次的含义,再输入到某些特定领域的执行组件中。
在过去的几年里,公司已经开始用LPLM取代这种传统的NLP解决方案,通过微调来执行特定任务。
机器翻译
早期的机器翻译系统只能在有限的领域中覆盖有限的语言结构。
2006年推出的谷歌翻译首次从大规模平行语料中构建统计模型;2016年谷歌翻译转为神经机器翻译系统,质量得到极大提升;2020年再次更新为基于Transformer的神经翻译系统,不再需要两种语言的平行语料,而是采用一个巨大的预训练网络,通过一个特别的token指示语言类型进行翻译。
问答任务
问答系统需要在文本集合中查找相关信息,然后提供特定问题的答案,下游有许多直接的商业应用场景,例如售前售后客户支持等。
现代神经网络问答系统在提取文本中存在的答案具有很高的精度,也相当擅长分类出不存在答案的文本。
分类任务
对于常见的传统NLP任务,例如在一段文本中识别出人员或组织名称,或者对文本中关于产品的情感进行分类(积极或消极),目前最好的系统仍然是基于LPLM的微调。
文本生成
除了许多创造性的用途之外,生成系统还可以编写公式化的新闻文章,比如体育报道、自动摘要等,也可以基于放射科医师的检测结果生成报告。
不过,虽然效果很好,但研究人员们仍然很怀疑这些系统是否真的理解了他们在做什么,或者只是一个无意义的、复杂的重写系统。
意义(meaning)
语言学、语言哲学和编程语言都在研究描述意义的方法,即指称语义学方法(denotational semantics)或指称理论(heory of reference):一个词、短语或句子的意义是它所描述的世界中的一组对象或情况(或其数学抽象)。
现代NLP的简单分布语义学认为,一个词的意义只是其上下文的描述,Manning认为,意义产生于理解语言形式和其他事物之间的联系网络,如果足够密集,就可以很好地理解语言形式的意义。
LPLM在语言理解任务上的成功,以及将大规模自监督学习扩展到其他数据模态(如视觉、机器人、知识图谱、生物信息学和多模态数据)的广泛前景,使得AI变得更加通用。
基础模型
除了BERT和GPT-3这样早期的基础模型外,还可以将语言模型与知识图神经网络、结构化数据连接起来,或是获取其他感官数据,以实现多模态学习,如DALL-E模型,在成对的图像、文本的语料库进行自监督学习后,可以通过生成相应的图片来表达新文本的含义。
我们目前还处于基础模型研发的早期,但未来大多数信息处理和分析任务,甚至像机器人控制这样的任务,都可以由相对较少的基础模型来处理。
虽然大型基础模型的训练是昂贵且耗时的,但训练完成后,使其适应于不同的任务还是相当容易的,可以直接使用自然语言来调整模型的输出。
但这种方式也存在风险:
1. 有能力训练基础模型的机构享受的权利和影响力可能会过大;
2. 大量终端用户可能会遭受模型训练过程中的偏差影响;
3. 由于模型及其训练数据非常大,所以很难判断在特定环境中使用模型是否安全。
虽然这些模型的最终只能模糊地理解世界,缺乏人类水平的仔细逻辑或因果推理能力,但基础模型的广泛有效性也意味着可以应用的场景非常多,下一个十年内或许可以发展为真正的通用人工智能。
















