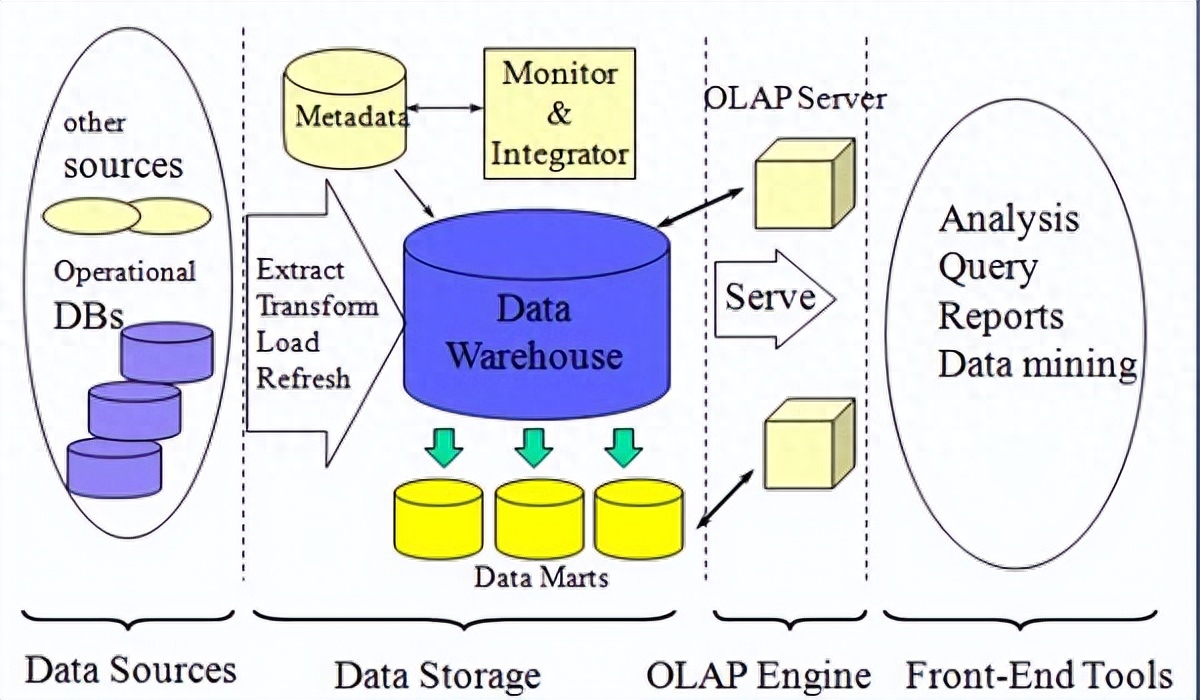
数据仓库是企业中存储和管理大量结构化数据的核心组件,用于支持业务分析和决策制定。构建和优化数据仓库的架构和模型设计是确保数据仓库能够高效、可扩展地满足业务需求的关键要素。本文将探讨如何构建与优化数据仓库架构与模型设计的关键步骤和最佳实践。
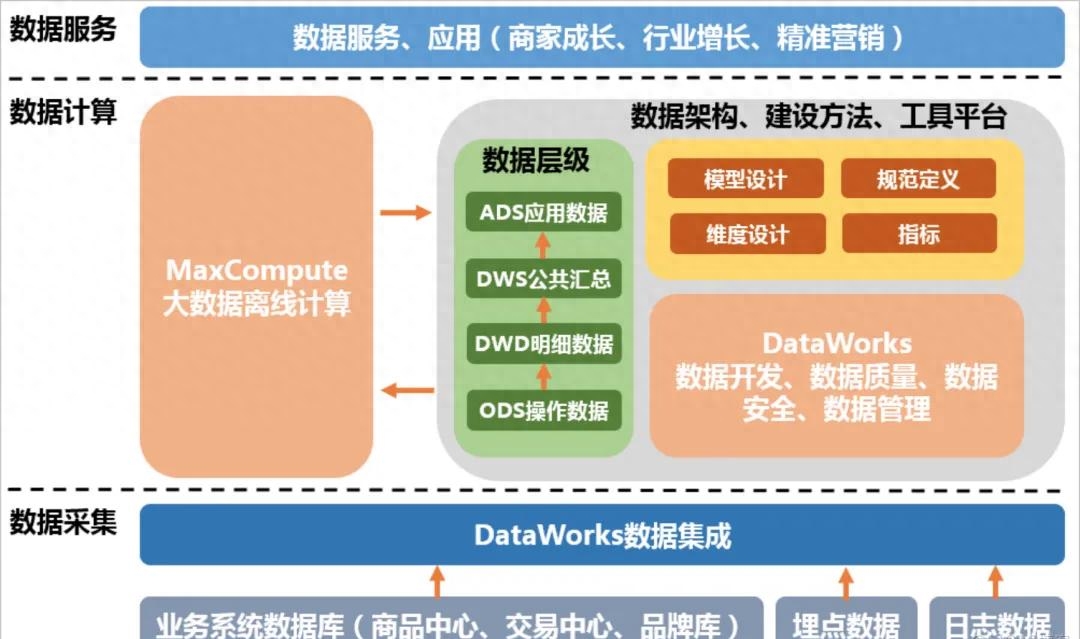
1、架构设计
数据仓库的架构设计决定了数据的存储、处理和访问方式,影响着数据仓库的性能和扩展性。以下是一些构建数据仓库架构的关键步骤:

业务需求分析:深入了解业务需求,明确数据仓库的功能和服务范围。与业务部门紧密合作,确定数据仓库的关键业务指标和数据粒度。

数据源集成:识别和整合企业内外部的数据源,包括数据库、应用系统、API等。通过ETL(抽取、转换、加载)过程将数据源的数据导入到数据仓库中。

数据模型设计:基于业务需求和数据关系,设计合适的数据模型。常见的数据模型包括维度建模(如星型模型和雪花模型)和面向文档的模型(如文档数据库)。数据模型需要考虑数据的查询和分析需求,以及数据的一致性和可扩展性。

数据存储和处理:选择合适的数据存储和处理技术,如关系型数据库、列式数据库、大数据平台等。根据数据量和性能要求,确定数据的分区、索引和分布策略,优化数据的存储和访问效率。

数据访问和报表:设计合适的数据访问接口和报表工具,以便用户能够方便地查询和分析数据。提供灵活的查询功能和可视化报表,支持自定义指标和数据透视。
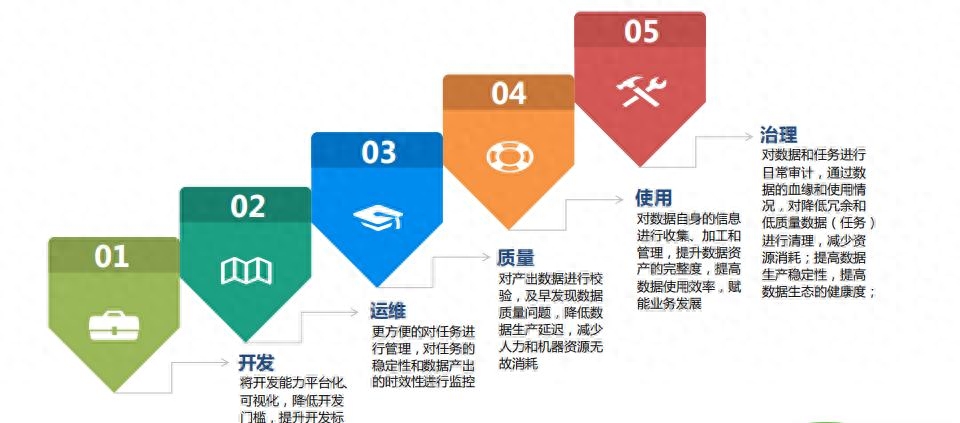
2、模型设计与优化
数据仓库的模型设计是构建高效的数据分析和查询环境的关键。以下是一些模型设计与优化的最佳实践:

维度建模:采用维度建模可以简化数据模型的设计和查询操作,提高查询性能。使用事实表和维度表来描述业务事实和业务维度,构建星型模型或雪花模型。合理定义维度层次、维度关系和度量指标,以满足不同粒度的查询需求。

数据分区:对大规模数据进行数据分区可以提高数据查询的性能。根据数据的特点和查询模式,将数据按照时间、地理位置、业务部门等进行分区。分区可以提高数据的存取效率,减少不必要的数据扫描和计算。
索引优化:合理设计和管理索引可以加速数据查询。根据查询的字段和条件,创建合适的索引。考虑索引的选择性、大小和更新成本,权衡查询性能和维护成本。

数据聚合:通过数据聚合可以减少数据的冗余和复杂性,提高查询性能。根据业务需求,对数据进行聚合,生成预计算的汇总数据或指标。通过聚合操作,可以加速复杂的查询和分析操作。

缓存优化:利用缓存技术可以减少数据仓库的访问次数,提高查询性能。将常用的查询结果和计算结果缓存起来,以便下次查询时直接获取。缓存可以使用内存缓存、分布式缓存或者查询结果缓存等方式实现。

数据压缩与分区裁剪:对数据进行压缩可以减少存储空间,并提高数据的读取速度。使用合适的压缩算法和压缩技术,根据数据的特点选择合适的压缩方式。同时,利用分区裁剪技术可以减少不必要的数据扫描,提高查询效率。

定期维护和优化:数据仓库的模型设计和优化是一个持续的过程。定期进行性能分析和优化,识别潜在的性能瓶颈和问题。根据监测结果进行索引重建、数据重分区和性能调优,保持数据仓库的高效运行。

通过合理的架构设计和模型优化,构建和优化数据仓库可以提供高效、可靠的数据分析环境。充分了解业务需求,设计合适的数据模型,选择适当的数据存储和处理技术,以及进行模型优化和性能调优,可以实现数据仓库的高性能查询和分析,为企业提供准确、及时的数据支持,推动业务决策和创新的发展。