













数据库领域的国际顶级学术会议 VLDB 2023 在加拿大温哥华落幕。VLDB 会议全称 International Conference on Very Large Data Bases,是数据库领域历史悠久的三大顶级会议 (SIGMOD、VLDB、ICDE) 之一,每届会议集中展示了当前数据库研究的前沿方向、工业界的最新技术和各国的研发水平,吸引了全球顶级研究机构投稿。

该会议对系统创新性、完整性、实验设计等方面都要求极高,VLDB 的论文接受率总体较低(约 18%),必须是贡献很大的论文才有机会被录用。今年的竞争更为激烈。据官方显示,今年 VLDB 共有 9 篇论文脱颖而出,获得了最佳论文奖项,其中不乏斯坦福、CMU、微软研究院、VMware 研究院、Meta 等全球知名高校、研究机构、科技巨头的身影。
其中由第四范式、清华大学以及新加坡国立大学联合完成的 "FEBench: A Benchmark for Real-Time Relational Data Feature Extraction" 论文,获得了最佳工业界论文 Runner Up 奖项。

该论文由第四范式、清华大学以及新加坡国立大学合作完成,提出了一个基于工业界真实场景积累的实时特征计算测试基准,用于评测基于机器学习的实时决策系统。

- 论文地址:https://github.com/decis-bench/febench/blob/main/report/febench.pdf
- 项目地址:https://github.com/decis-bench/febench
项目背景
基于人工智能的决策系统目前已经在很多行业场景实现了广泛的应用,其中大量的场景涉及到基于实时数据的计算,比如金融行业的反欺诈、零售行业的实时线上推荐等场景。机器学习驱动的实时决策系统一般会包含两个最主要的计算环节,即特征和模型。其中,由于业务逻辑的多样化和线上的低延迟、高并发的需求,特征计算往往成为整个决策系统的瓶颈,需要大量的工程化实践来构建一个生产环境可用、稳定高效的实时特征计算平台。如下图 1 列举了一个常见的反欺诈应用的实时特征计算场景。基于原始的刷卡流水记录表格进行特征计算,生成新的特征(包含如最近 10 秒内最大 / 最小 / 平均刷卡金额等特征),进一步输入下游模型,进行实时推理。
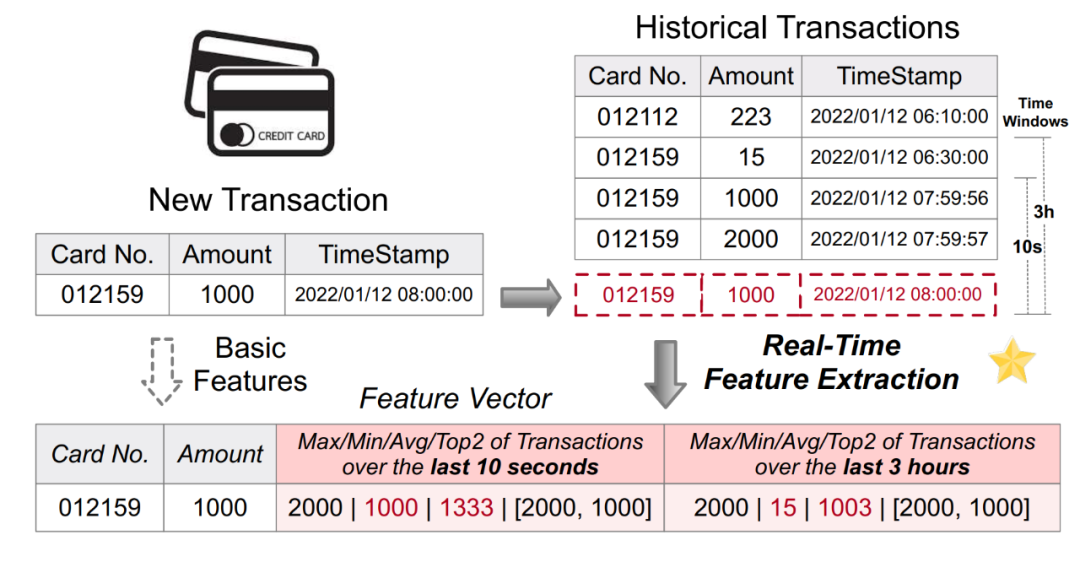
图 1. 反欺诈应用中的实时特征计算
一般来说,实时特征计算平台需要满足如下两个基本要求:
- 线上线下一致性:由于机器学习应用一般会分为线上和线上两个流程,即基于历史数据的训练和基于实时数据的推理。因此确保线上线下的特征计算逻辑一致性,对于保证线上线下最终业务效果一致至关重要。
- 线上服务的高效性:线上服务针对实时数据和计算,满足低延迟、高并发、高可用等需求。
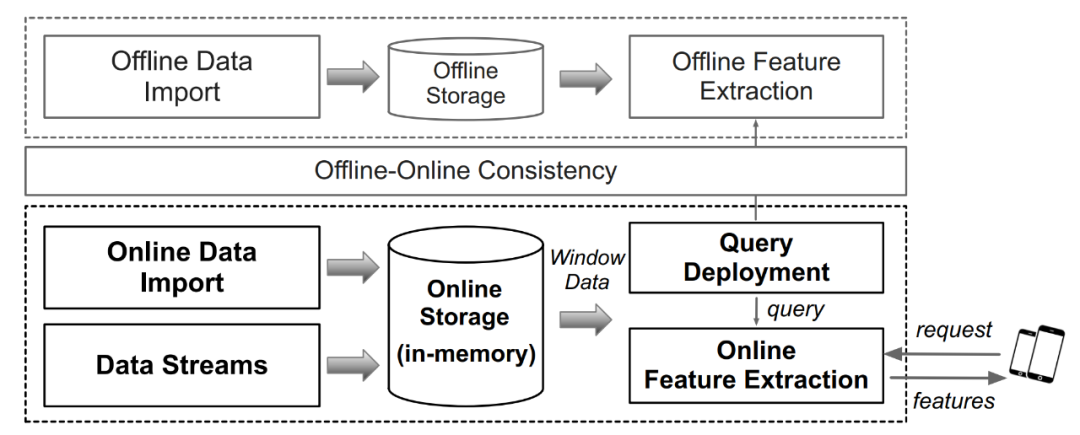
图 2. 实时特征计算平台架构及工作流程
如上图 2 列举了一个常见的实时特征计算平台的架构。简单来说主要包含了离线计算引擎和在线计算引擎,其中的关键点是保证离线和在线计算引擎的计算逻辑一致性。目前市面上有许多特征平台可以满足上述要求,构成一个完整的实时特征计算平台,包括通用系统如 Flink,或者专用系统如 OpenMLDB、Tecton、Feast 等。但是,目前工业界缺少一个面向实时特征的专用基准来对这类系统的性能进行严谨科学的评估。针对该需求,本篇论文作者构建了 FEBench,一个实时特征计算基准测试,用于评估特征计算平台的性能,分析系统的整体延迟、长尾延迟和并发性能等。
技术原理
FEBench 基准的构建主要包含三部分工作:数据集搜集、查询生成、以及模板选择。
数据集搜集
研究团队总共收集了 118 个可以用于实时特征计算场景的数据集,这些数据集来自 Kaggle,Tianchi,UCI ML,KiltHub 等公开数据网站以及第四范式内部可公开数据,覆盖了工业界的典型使用场景,如金融、零售、医疗、制造、交通等行业场景。研究小组进一步按照表格数量及数据集大小将收集到的数据集进行了归类,如下图 3 所示。
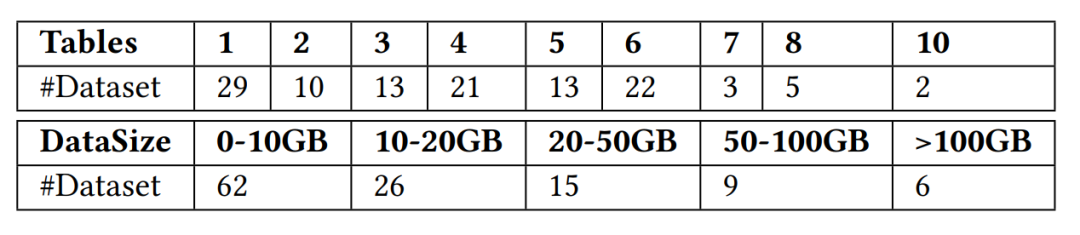
图 3. FEBench 中数据集的表格数量及数据集大小
查询生成
由于数据集数量较大,为每一个数据集人工生成特征抽取的计算逻辑工作量十分巨大,因此研究人员利用了如 AutoCross(参考论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications) 等自动机器学习技术,来为收集到的数据集自动化生成查询。FEBench 的特征选择和查询生成过程包括以下四个步骤(如下图 4 所示):
- 通过识别数据集中的主表(存储流式数据)和辅助表(例如静态 / 可追加 / 快照表),进行初始化。随后,分析主表和辅助表中具有相似名称或键关系的列,并枚举列之间的一对一 / 一对多关系,这些关系对应不同的特征操作模式。
- 将列关系映射到特征操作符。
- 在提取所有候选特征后,利用 Beam 搜索算法迭代生成有效的特征集。
- 选择的特征被转换为语义上等效的 SQL 查询。
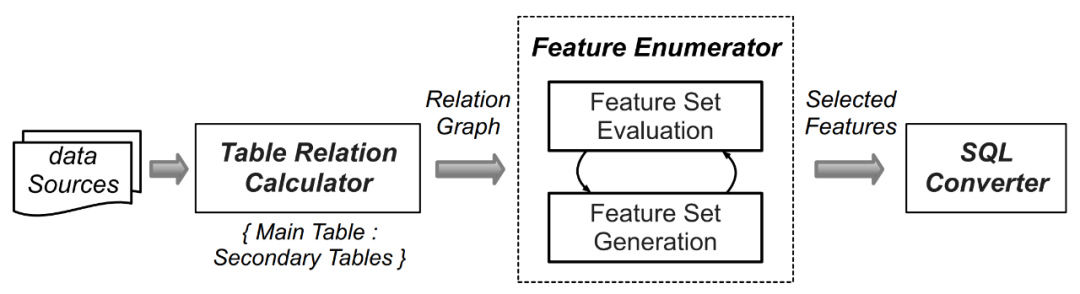
图 4. FEBench 中查询的生成流程
模板选择
在为每一个数据集生成查询以后,研究人员进一步使用聚类算法选取代表性的查询作为查询模板,来减少对相似任务的冗余测试。对于收集到的 118 个数据集和特征查询,采用 DBSCAN 对这些查询进行聚类,步骤如下:
- 将每个查询的特征划分为五个部分:输出列数、查询操作符总数、复杂运算符的出现频率、嵌套子查询层数以及时间窗口中最大元组的数量。由于特征工程查询通常涉及时间窗口,查询复杂性不受批处理数据规模的影响,因此数据集大小没有作为聚类特征之一。
- 使用逻辑回归模型评估查询特征与查询执行特性的关系,特征作为模型输入,特征查询的执行时间为模型输出。使用每个特征的回归权重作为其聚类权重,以考虑不同特征对聚类结果的重要性。
- 基于加权查询特征,使用 DBSCAN 算法将特征查询划分为多个聚类。
如下图 5 可视化了 118 个数据集在各个考量指标下的分布。其中图(a)展示了统计性质的指标,包括输出列数,查询操作符总数和嵌套子查询层数;图(b)展示了与查询执行时间相关性最高的指标,包括聚合操作个数,嵌套子查询层数和时间窗口个数。
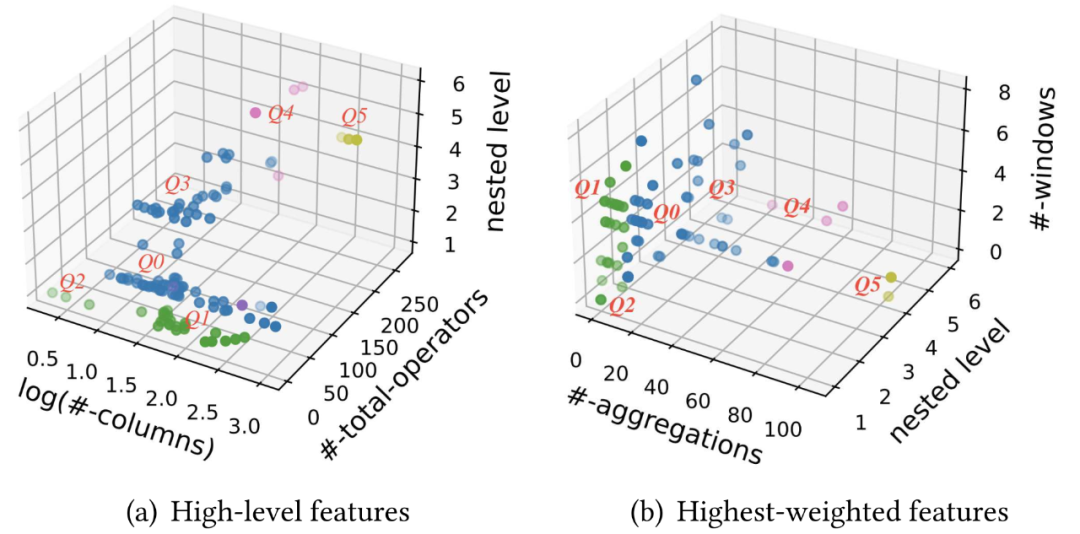
图 5. 118 个特征查询通过聚类分析得到 6 个集群,生成查询模板(Q0-5)
最终,根据聚类结果,将 118 个特征查询分为 6 个集群。对于每个集群,选择质心附近的查询作为候选模板。此外,考虑到不同应用场景下的人工智能应用可能有不同的特征工程需求,围绕每个集群的质心,尝试选择来自不同场景的查询,以更好地覆盖不同的特征工程场景。最终,从 118 个特征查询中选择了 6 个查询模板,适用于不同场景,包括交通、医疗保健、能源、销售,以及金融交易。这 6 个查询模板最终构成了 FEBench 最为核心的数据集和查询,用于进行实时特征计算平台的性能测试。
基准评测( OpenMLDB vs Flink)
研究人员在两个典型的工业界系统 Flink(通用的批处理和流处理一致性计算平台)及 OpenMLDB(专用实时特征计算平台)上部署了 FEBench 进行测试,并分析了两个系统各自的优缺点以及背后的原因。实验展示了 Flink 和 OpenMLDB 由于架构设计不同带来的性能差异,并由此说明了 FEBench 分析目标系统的能力。其评测的主要结论如下。
- Flink 比 OpenMLDB 在延迟上慢两个数量级(图 6)。研究人员分析,其造成差距的主要原因在于两者系统架构的不同实现方式,其中 OpenMLDB 作为实时特征计算的专用系统,包含了基于内存的双层跳表等专门针对时序数据优化的数据结构,最终相比较于 Flink,在特征计算场景上有明显的性能优势。当然 Flink 作为通用系统,在可适用场景上比 OpenMLDB 更为广泛。
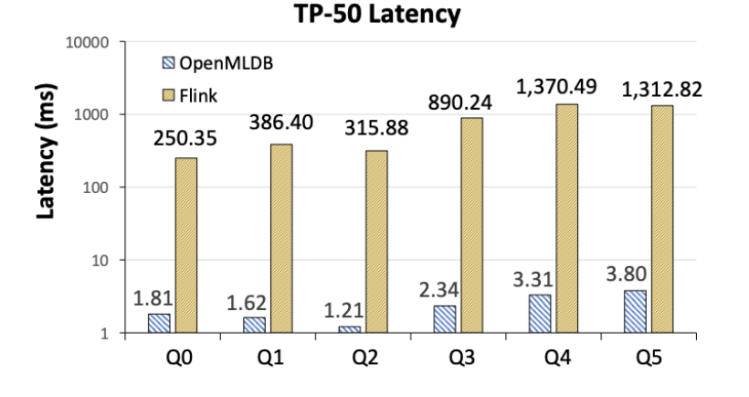
图 6. OpenMLDB 与 Flink 的 TP-50 延迟对比
- OpenMLDB 表现出明显的长尾延迟问题,而 Flink 的尾延迟更稳定(图 7)。注意,以下数字显示均为归一化到 OpenMLDB 和 Flink 各自的 TP-50 下的延迟性能,并不代表绝对性能的比较。
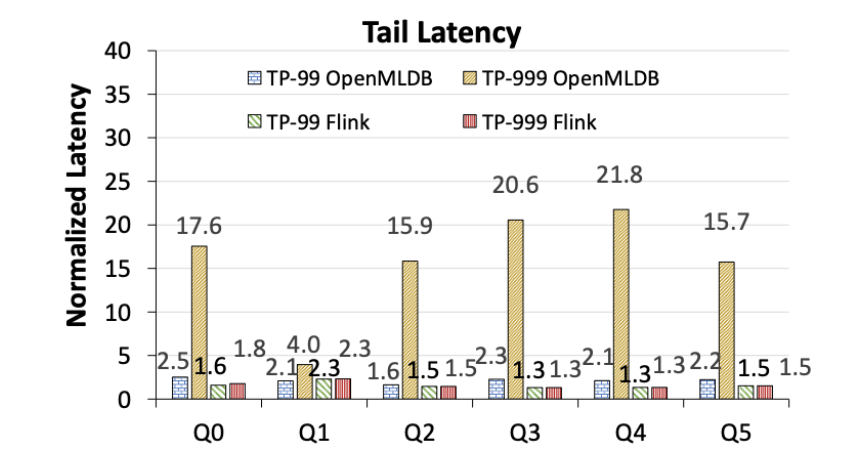
图 7. OpenMLDB 与 Flink 的尾延迟对比(归一化到各自的 TP-50 延迟)
研究人员对上述的性能结果进行了进一步的深入分析:
- 微架构指标分析:根据执行时间进行拆解分析,包括指令完成、错误分支预测、后端依赖和前端依赖等指标。不同查询模板的性能瓶颈在微观结构层面上有所不同。如下图 8 所示,Q0-Q2 的性能瓶颈主要在前端依赖,占整个运行时间的 45% 以上,这种情况下执行的操作相对简单,大部分时间花在处理用户请求和特征提取指令的切换上面。而对于 Q3-Q5,后端依赖(缓存失效等)和指令运行(更多复杂指令)成为更主要的因素。OpenMLDB 的针对性优化使得它在性能上更加出色。
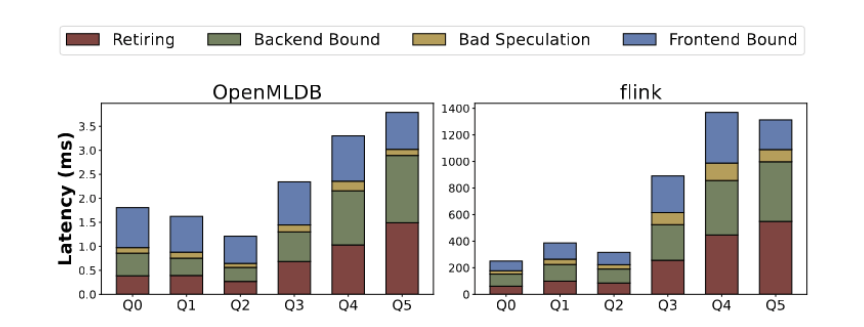
图 8. OpenMLDB 与 Flink 的微架构指标分析
- 执行计划分析:以 Q0 为例,下图 9 比较了 Flink 和 OpenMLDB 的执行计划差异。Flink 中的计算运算符花费最多的时间,而 OpenMLDB 通过优化窗口处理和使用自定义聚合函数等优化技术减少了执行延迟。
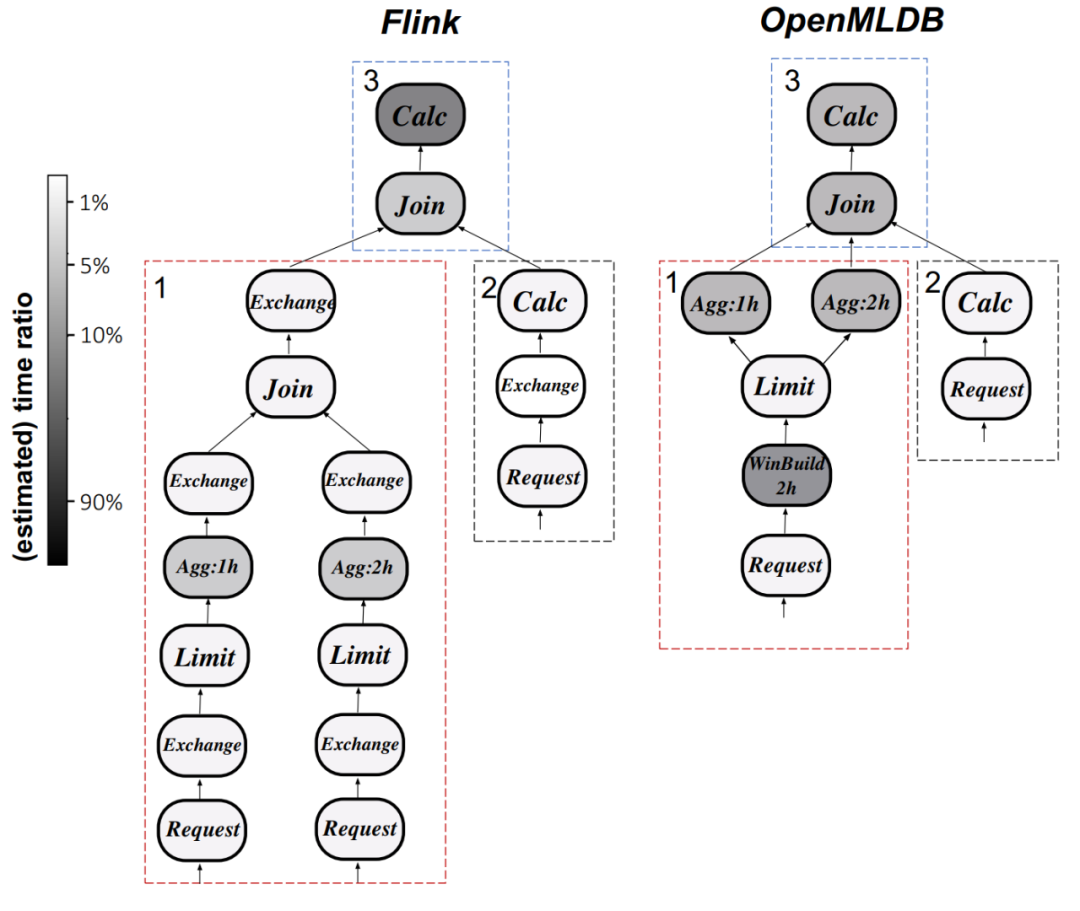
图 9. OpenMLDB 与 Flink 的执行计划(Q0)对比
如果用户期望复现以上实验结果,或者在本地系统上进行基准测试(论文作者也鼓励将测试结果在社区提交共享),可以访问 FEBench 的项目主页,获得更多信息。
- FEBench 项目:https://github.com/decis-bench/febench
- Flink 项目:https://github.com/apache/flink
- OpenMLDB 项目:https://github.com/4paradigm/OpenMLDB



























