大规模语言模型(LLM)使用户可以借助提示和上下文学习来构建强大的自然语言处理系统。然而,从另一角度来看,LLM 在特定自然语言处理任务上表现存在一定退步:这些模型的部署需要大量计算资源,并且通过 API 与模型进行交互可能引发潜在的隐私问题。
为了应对这些问题,来自卡内基梅隆大学(CMU)和清华大学的研究人员,共同推出了 Prompt2Model 框架。该框架的目标是将基于 LLM 的数据生成和检索方法相结合,以克服上述挑战。使用 Prompt2Model 框架,用户只需提供与 LLM 相同的提示,即可自动收集数据并高效地训练适用于特定任务的小型专业模型。
研究人员在三个自然语言处理子任务上进行了实验。采用少量样本提示作为输入,仅需花费 5 美元收集数据并进行 20 分钟的训练,Prompt2Model 框架生成的模型在性能上相较强大的 LLM 模型 gpt-3.5-turbo 表现出 20% 的性能提升。与此同时,模型的体积缩小了高达 700 倍。研究人员进一步验证了这些数据在真实场景中对模型效果的影响,使得模型开发人员能够在部署前预估模型的可靠性。该框架已以开源形式提供:

- 框架的 GitHub 仓库地址:https://github.com/neulab/prompt2model
- 框架演示视频链接:youtu.be/LYYQ_EhGd-Q
- 框架相关论文链接:https://arxiv.org/abs/2308.12261
背景
从零开始建立特定自然语言处理任务系统通常相当复杂。系统的构建者需要明确定义任务范围,获取特定的数据集,选择合适的模型架构,进行模型训练和评估,然后将其部署以供实际应用。
大规模语言模型(LLM)如 GPT-3 为这一过程提供了更加简便的解决方案。用户只需提供任务提示(instruction)以及一些示例(examples),LLM 便能生成相应的文本输出。然而,通过提示生成文本可能会消耗大量计算资源,并且使用提示的方式不如经过专门训练的模型稳定。此外,LLM 的可用性还受到成本、速度和隐私等方面的限制。
为了克服这些问题,研究人员开发了 Prompt2Model 框架。该框架将基于 LLM 的数据生成与检索技术相结合,以解决上述限制。该系统首先从 prompt 中提取关键信息,然后生成并检索训练数据,最终生成可供部署的专业化模型。
Prompt2Model 框架自动执行以下核心步骤:
- 数据集与模型检索:收集相关数据集和预训练模型。
- 数据集生成:利用 LLM 创建伪标记数据集。
- 模型微调:通过混合检索数据和生成数据对模型进行微调。
- 模型测试:在测试数据集和用户提供的真实数据集上对模型进行测试。
经过多个不同任务的实证评估,Prompt2Model 所花费成本显著降低,模型的体积也大幅缩小,但性能超越了 gpt-3.5-turbo。Prompt2Model 框架不仅可作为高效构建自然语言处理系统的工具,还可用作探索模型集成训练技术的平台。

框架
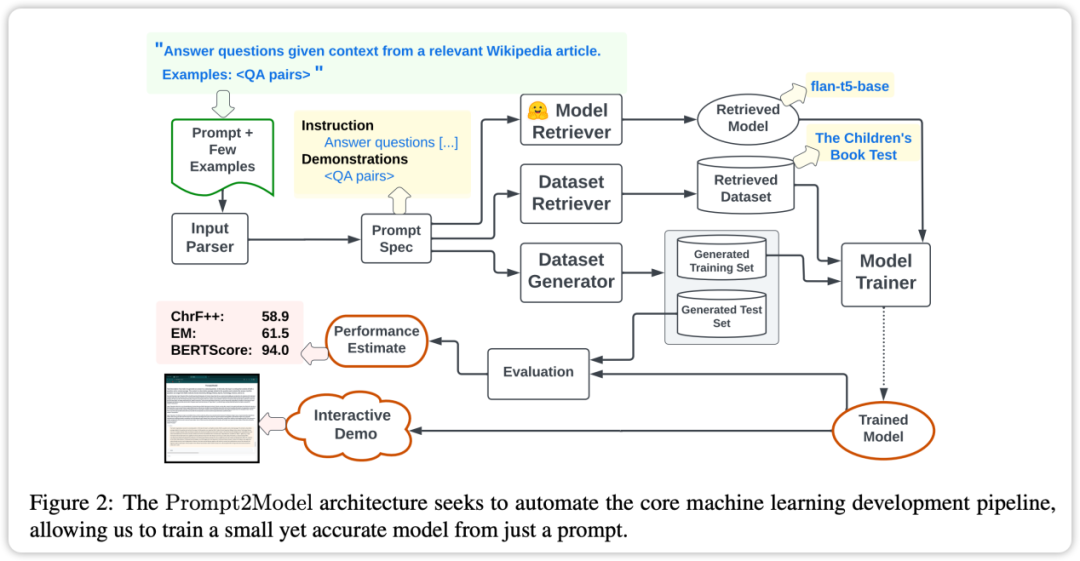
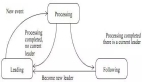
Prompt2Model 框架的核心特点为高度自动化。其流程涵盖了数据收集、模型训练、评估和部署等多个环节,如上图所示。其中,自动化数据收集系统扮演了关键角色,它通过数据集检索和基于 LLM 的数据生成,获取与用户需求密切相关的数据。接着,系统会检索预训练模型,并在获取的数据集上进行微调。最后,系统会在测试集上对经过训练的模型进行评估,并创建用于与模型交互的 Web 用户界面(UI)。
Prompt2Model 框架的关键特点包括:
- Prompt 驱动:Prompt2Model 的核心思想在于使用 prompt 作为驱动,用户可以直接描述所需的任务,而无需深入了解机器学习的具体实现细节。
- 自动数据收集:框架通过数据集检索和生成技术来获取与用户任务高度匹配的数据,从而建立训练所需的数据集。
- 预训练模型:框架利用预训练模型并进行微调,从而节省大量的训练成本和时间。
- 效果评估:Prompt2Model 支持在实际数据集上进行模型测试和评估,使得在部署模型之前就能进行初步预测和性能评估,从而提高了模型的可靠性。
这些特点使 Prompt2Model 框架成为一个强大的工具,能够高效地完成自然语言处理系统的构建过程,并且提供了先进的功能,如数据自动收集、模型评估以及用户交互界面的创建。
实验与结果
在实验设计方面,研究者选择了三项不同的任务,以评估 Prompt2Model 系统的性能:
- 机器阅读问答(Machine Reading QA):使用 SQuAD 作为实际评估数据集。
- 日语自然语言到代码转换(Japanese NL-to-Code):使用 MCoNaLa 作为实际评估数据集。
- 时间表达式规范化(Temporal Expression Normalization):使用 Temporal 数据集作为实际评估数据集。
此外,研究者还选用了 GPT-3.5-turbo 作为基准模型进行对比。实验结果得出以下结论:
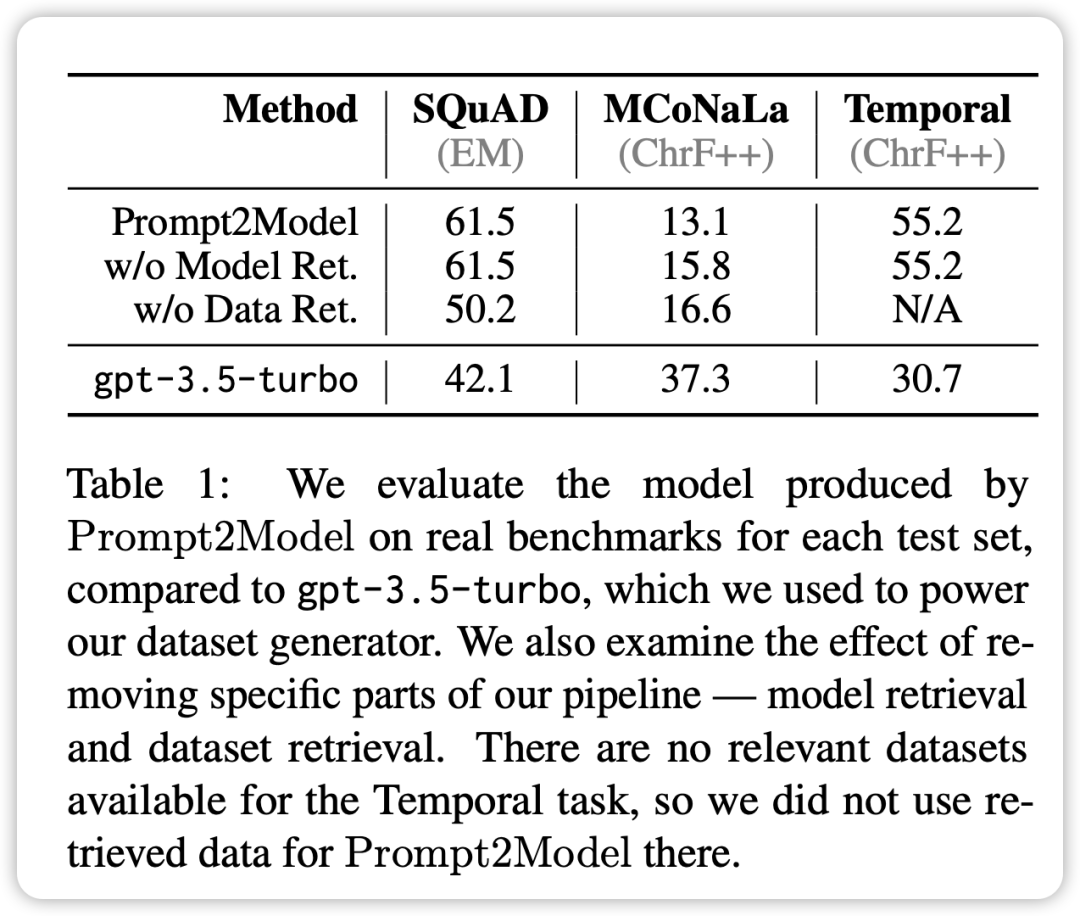
- 在除了代码生成任务之外的各项任务中,Prompt2Model 系统所生成的模型明显优于基准模型 GPT-3.5-turbo,尽管生成的模型参数规模远小于 GPT-3.5-turbo。
- 通过将检索数据集与生成数据集进行混合训练,可以达到与直接使用实际数据集训练相媲美的效果。这验证了 Prompt2Model 框架能够极大地降低人工标注的成本。
- 数据生成器所生成的测试数据集能够有效区分不同模型在实际数据集上的性能。这表明生成的数据具有较高的质量,在模型训练方面具有充分的效果。
- 在日语到代码转换任务中,Prompt2Model 系统的表现不如 GPT-3.5-turbo。
这可能是因为生成的数据集质量不高,以及缺乏适当的预训练模型等原因所致。
综合而言,Prompt2Model 系统在多个任务上成功生成了高质量的小型模型,极大地减少了对人工标注数据的需求。然而,在某些任务上仍需要进一步改进。

总结
研究团队所推出的 Prompt2Model 框架实现了仅通过自然语言提示来自动构建任务特定模型的功能。这一创新显著地降低了构建定制化自然语言处理模型的门槛,进一步扩展了 NLP 技术的应用范围。
验证实验结果显示,Prompt2Model 框架所生成的模型相较于大型语言模型,其规模显著减小,且在多个任务上表现优于诸如 GPT-3.5-turbo 等模型。同时,该框架生成的评估数据集也被证实能够有效评估不同模型在真实数据集上的性能。这为指导模型的最终部署提供了重要价值。
Prompt2Model 框架为行业和广大用户提供了一种低成本、易于上手的途径,以获取满足特定需求的 NLP 模型。这对于推动 NLP 技术的广泛应用具有重要意义。未来的工作将继续致力于进一步优化框架的性能。
按照文章顺序,本文作者如下:
Vijay Viswanathan: http://www.cs.cmu.edu/~vijayv/
Chenyang Zhao: https://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch: https://www.cs.cmu.edu/~abertsch/
Tongshuang Wu: https://www.cs.cmu.edu/~sherryw/
Graham Neubig: http://www.phontron.com/