












最近,在一场无人机比赛中,一架自主控制的无人机战胜了顶级人类玩家。
这架自主控制无人机是由来自苏黎世大学的研究团队设计研发的 Swift 系统,研究成果登上了最新一期的《Nature》杂志封面。

研究内容:https://www.nature.com/articles/s41586-023-06419-4
在这场无人机比赛中,人类操纵者通过机载摄像机操纵无人机通过 3D 赛道,这是为了让操纵者从无人机的视角观察环境。自主无人机要达到人类控制无人机的水平是非常具有挑战性的,因为无人机需要仅通过机载传感器估计其在赛道中的速度和位置。
而 Swift 战胜的是世界冠军级人类玩家,他们分别是:2019 年无人机竞速联盟世界冠军 Alex Vanover、两届 MultiGP 国际公开赛冠军 Thomas Bitmatta 和三届瑞士全国冠军 Marvin Schaepper。
下图 1a 是这次比赛的赛道,Swift 不仅赢得了与人类冠军的比赛,还创造了最快的比赛纪录。这项工作是移动机器人和机器智能领域的一个里程碑。

图 1
下面我们就来看一下自主无人机 Swift 的技术方法。
Swift 技术介绍
Swift 是一个仅使用机载传感器和计算完成自主控制的四旋翼飞行器,由两个关键模块组成:
- 感知系统,将高维的视觉和惯性信息转换成低维表征;
- 控制策略,摄取感知系统产生的低维表征并产生控制命令。
其中,控制策略由一个前馈神经网络来表征,并使用无模型 on-policy 深度强化学习(RL)进行训练。
由于模拟与现实世界在传感和动力学方面存在差异,仅在模拟中优化策略会导致无人机的现实性能较差,因此研究团队利用物理系统收集的数据来估计非参数经验噪声模型(non-parametric empirical noise model)。实验表明,这些经验噪声模型有助于将控制策略从模拟成功转移到现实。
具体来说,Swift 将机载传感器的读数映射成控制命令,这一映射包括两部分:(1) 观察策略,将高维的视觉和惯性信息提炼成特定于任务的低维编码;(2) 控制策略,将编码转换成无人机命令。Swift 系统整体概览如下图 2 所示:
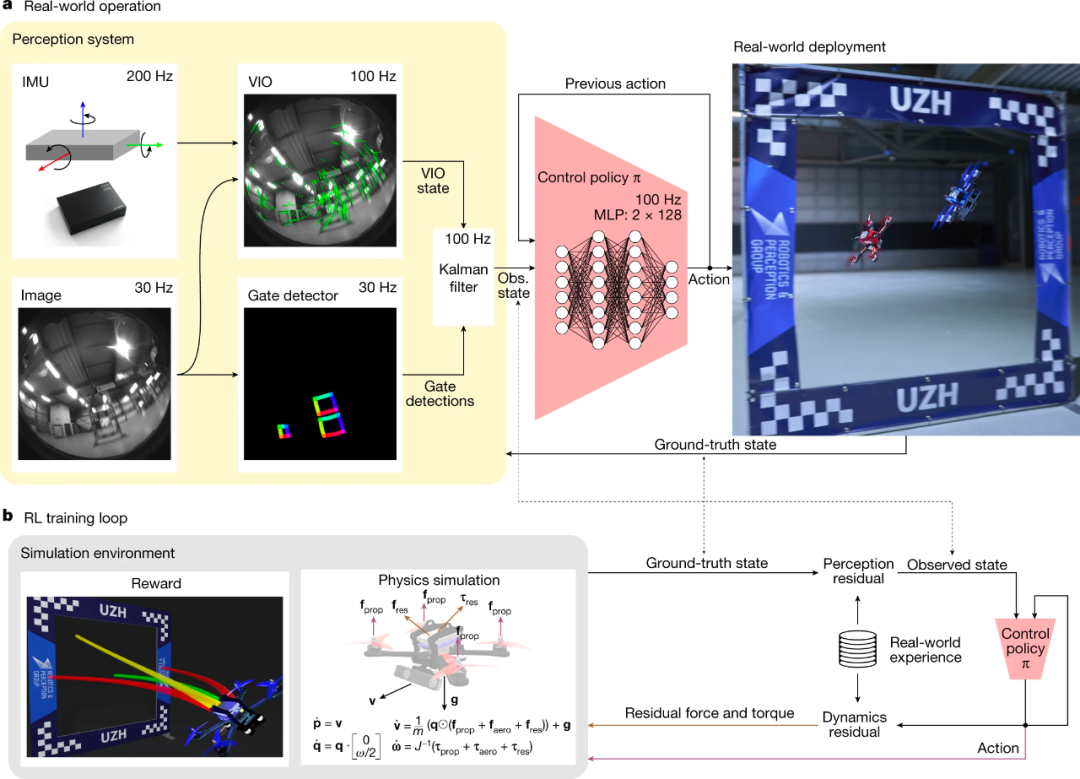
图 2
如图 1 所示场景,Swift 的观察策略需要运行视觉 - 惯性估计器和门检测器。其中,门检测器是一个卷积神经网络,用于检测机载图像中的赛车门,然后使用检测到的门来估计无人机在赛道上的全局位置和飞行方向。这是使用相机后方交会算法(camera-resectioning algorithm),并结合赛道地图来完成的。最后,Swift 用卡尔曼滤波(Kalman filter)将全局姿态估计(从门检测器获得)与视觉 - 惯性估计结合起来,从而更准确地表征机器人的状态。
控制策略(用一个两层感知器表征),负责将卡尔曼滤波(Kalman filter)的输出映射成无人机控制命令。控制策略在模拟中使用无模型 on-policy 深度强化学习(RL)进行训练。在训练期间,该策略会考虑相机视野内下一个竞赛门的信息,将奖励最大化,以提高姿态估计的准确性。
实验及结果
为了评估 Swift 的性能,该研究进行了一系列的比赛实验,并与轨迹规划和模型预测控制(MPC)进行了比较。
如下图 3b 所示,在与 A. Vanover 的 9 场比赛中,Swift 赢了 5 场;在与 T. Bitmatta 的 7 场比赛中,Swift 赢了 4 场;在与 M. Schaepper 的 9 场比赛中,Swift 赢了 6 场。在 Swift 记录的 10 次失利中,40% 是因为与对手相撞,40% 是因为与竞赛门相撞,20% 是因为比人类控制的无人机慢。总体而言,在与人类控制无人机进行的比赛中,Swift 获胜次数最多,并且它还创造了最快的比赛纪录,比人类控制无人机(A. Vanover)的最佳时间快了半秒。
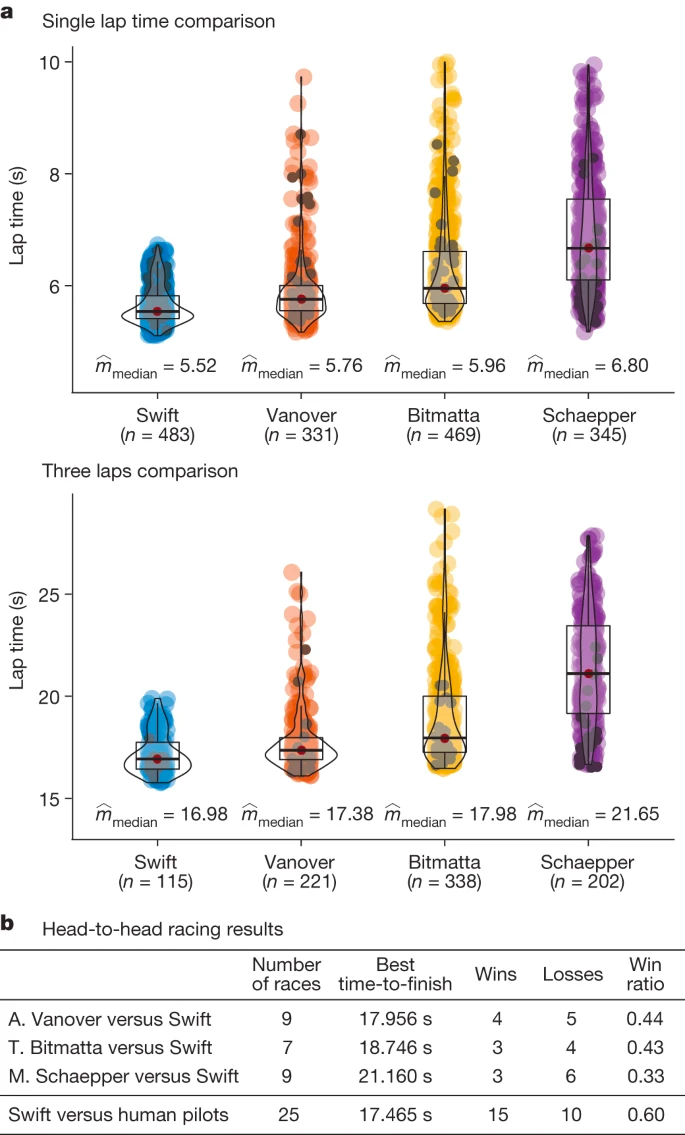
图 3
为了对 Swift 的性能进行更细致的分析,该研究比较了 Swift 和人类控制无人机的最快单圈飞行速度,结果如下图 4 和表 1 所示。
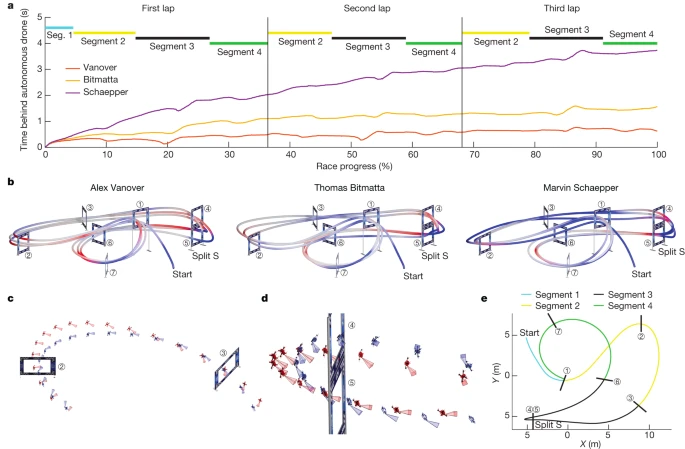
图 4
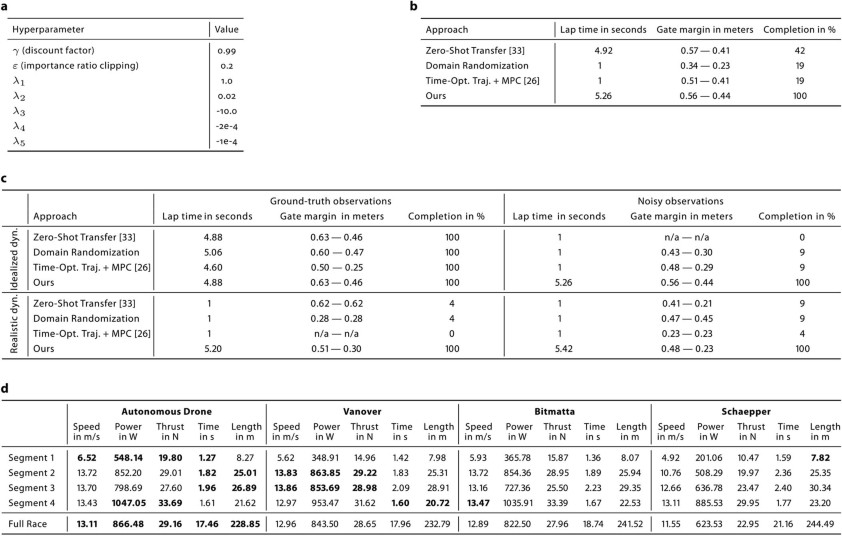
表 1
虽然从整体上看,Swift 比所有人类控制无人机都要快,但它在赛道的每个赛段上的速度并不快,如表 1 所示。
研究团队仔细分析发现:在起飞时,Swift 的反应时间较短,平均比人类飞行员早 120 毫秒起飞;Swift 的加速也更快,进入第一个竞赛门时速度更高。在急转弯时,如图 4cd 所示,Swift 的动作更加紧凑。
研究团队还提出一种假设,Swift 在比人类操控者更长的时间尺度上优化轨迹。众所周知,无模型 RL 可以通过价值函数优化长期奖励(long-term reward)。相反,人类操控者规划运动的时间尺度较短,最多只能预测未来一个竞赛门。






















