在弹性容器化环境中,拥有低效代码是非常昂贵的。通过向左监控方法和可观测性解决方案,可以帮助解决这个问题。
向左移动(Shift-left)是一种软件开发和运维的方法,强调在软件开发生命周期的早期进行测试、监控和自动化。向左移动的目标是在问题出现之前及时发现并迅速解决,以防止问题的发生。
当您早期识别到可扩展性问题或错误时,解决起来更快、更具成本效益。将低效代码转移到云容器中可能非常昂贵,因为它可能会激活自动扩展功能,增加您的月度费用。此外,在您能够识别、隔离和修复问题之前,您将处于紧急状态。
问题陈述
我想给您演示一个案例,我们成功地避免了一个潜在的应用程序问题,在生产环境中可能会造成重大影响。
2022年我们的Kubernetes报告提供了关于团队如何利用Kubernetes、AI中的K8s、集群可观测性方面的见解等内容。
我正在审查最近应用程序更改后的UAT基础架构的性能报告。这是一个使用MariaDB作为后端、运行在Apache反向代理和AWS应用负载均衡器后面的Spring Boot微服务。新功能成功集成,并且通过了所有UAT测试用例。然而,我注意到MariaDB性能仪表板中的性能图表与部署前的模式有所偏离。
以下是事件的时间轴。
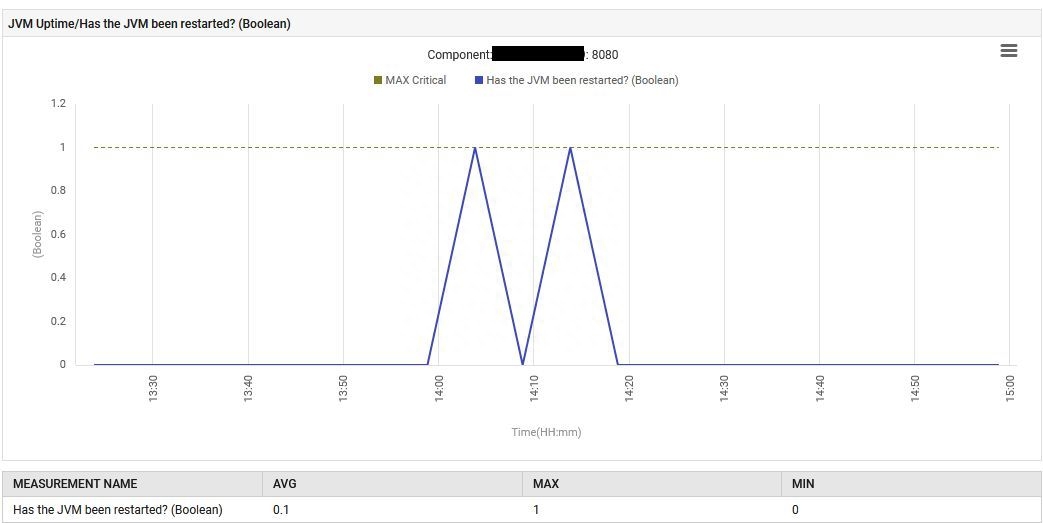
8月6日14:13,应用程序使用包含嵌入式Tomcat的新Spring Boot jar文件重新启动。
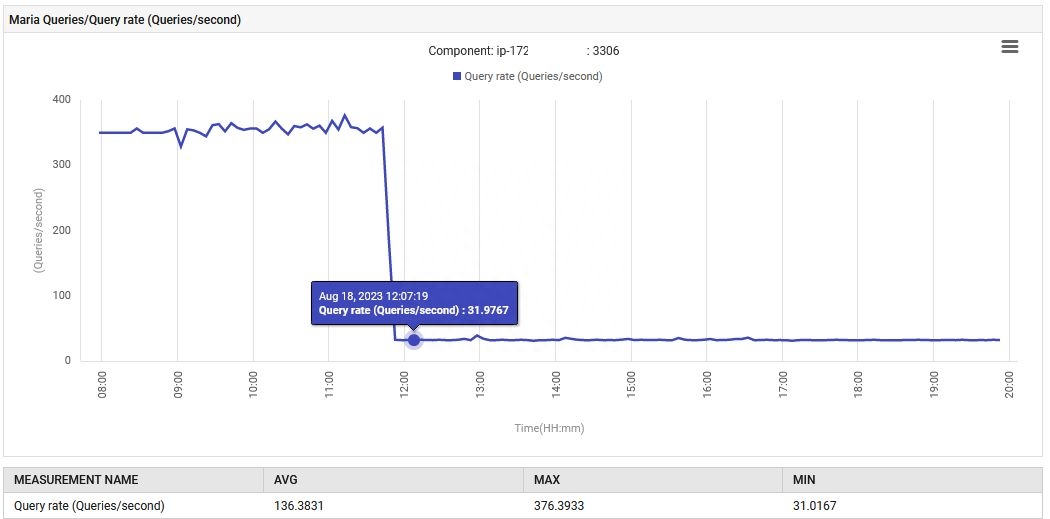
14:52,MariaDB的查询处理速率从每秒0.1增加到88次查询/秒,然后增加到301次查询/秒。
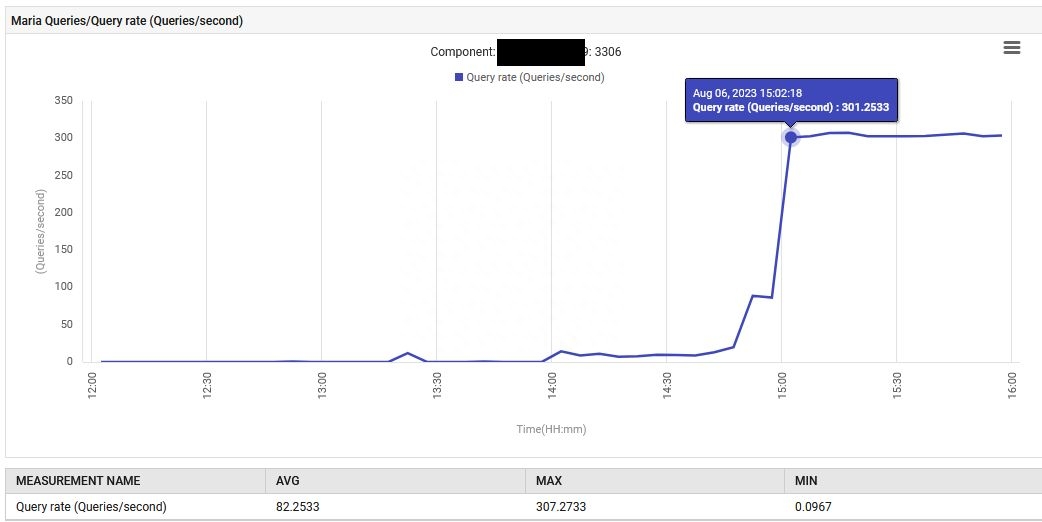
此外,系统CPU利用率从1%提高到6%。

最后,JVM在G1 Young Generation Garbage Collection上花费的时间从0%增加到0.1%,并保持在这个水平。
该应用程序在UAT阶段异常地发出300次查询/秒,远远超出了其设计要求。新功能导致数据库连接增加,因此查询量显著增加。然而,监控仪表板显示,在部署新版本之前,问题措施是正常的。
解决方案
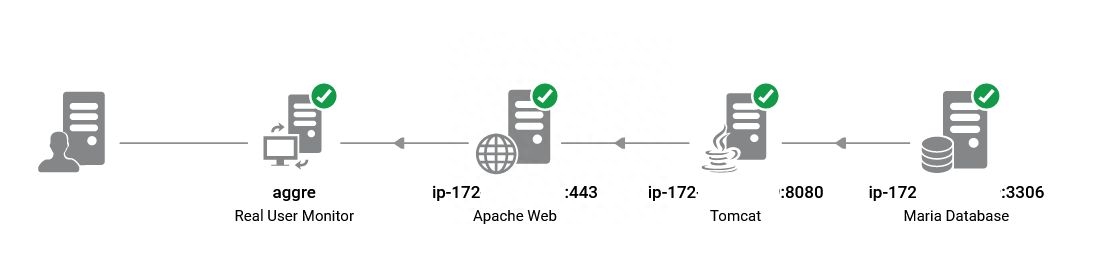
这是一个使用JPA查询MariaDB的Spring Boot应用程序。该应用程序的设计是在两个容器上运行以实现最小负载,但可以扩展到十个容器。
如果一个单独的容器可以生成每秒300次查询,那么如果所有十个容器都运行,它可以处理每秒3000次查询吗?数据库能否拥有足够的连接来满足应用程序其他部分的需求?
我们别无选择,只能返回开发人员的工作台,检查Git中的更改。
新的更改将从一个表中获取少量记录并进行处理。这是我们在服务类中观察到的代码。
List<X> findAll = this.xRepository.findAll();不,使用Spring的CrudRepository的findAll()方法而没有分页是低效的。分页有助于减少从数据库检索数据所需的时间,通过限制获取的数据量。这是我们主要的关系型数据库(RDBMS)教育所教导我们的。此外,分页有助于保持内存使用低,以防止应用程序由于数据过载而崩溃,并减少Java虚拟机的垃圾回收工作量,正如前面问题陈述中提到的。
这个测试是在一个容器中使用2000条记录进行的。如果这段代码被部署到生产环境中,其中每个容器有约20万条记录,那么可能会给团队带来很大的压力和忧虑。
应用程序在将方法添加WHERE子句后重新构建。
List<X> findAll =
this.xRepository.findAllByY(Y);恢复了正常运行。每秒查询数从300降至30,垃圾收集的工作量恢复到原始水平。此外,系统的CPU使用率降低。
学习和总结
任何从事站点可靠性工程(SRE)工作的人都会理解这个发现的重要性。我们能够在不提高严重性1级别的情况下采取行动。如果这个有缺陷的软件包部署到生产环境中,可能会触发客户的自动扩展阈值,即使没有额外的用户负载,也会启动新的容器。
这个故事有三个主要的要点。
首先,最好从一开始就启用一个可观测性解决方案,因为它可以提供事件的历史记录,用于识别潜在问题。如果没有这个历史记录,我可能不会认真对待0.1%的垃圾回收百分比和6%的CPU消耗,代码可能会发布到生产环境中,造成灾难性的后果。扩大监控解决方案的范围到UAT服务器有助于团队在问题发生前识别潜在根本原因并防止问题发生。
其次,在测试过程中应存在与性能相关的测试用例,并由具有可观测性经验的人员进行审查。这将确保对代码的功能和性能进行测试。
第三,云原生的性能跟踪技术对于接收有关高利用率、可用性等方面的警报非常有用。为了实现可观测性,您可能需要准备合适的工具和专业知识。祝编码愉快!