我们平时在阅读论文或者科学文献时,见到的文件格式基本上是 PDF(Portable Document Format)。据了解,PDF 成为互联网上第二重要的数据格式,占总访问量的 2.4%。
然而,存储在 PDF 等文件中的信息很难转成其他格式,尤其对数学公式更是显得无能为力,因为转换过程中很大程度上会丢失信息。就像下图所展示的,带有数学公式的 PDF,转换起来就比较麻烦。

现在,Meta AI 推出了一个 OCR 神器,可以很好的解决这个难题,该神器被命名为 Nougat。Nougat 基于 Transformer 模型构建而成,可以轻松的将 PDF 文档转换为 MultiMarkdown,扫描版的 PDF 也能转换,让人头疼的数学公式也不在话下。

- 论文地址:https://arxiv.org/pdf/2308.13418v1.pdf
- 项目主页:https://facebookresearch.github.io/nougat/
Nougat 不但可以识别文本中出现的简单公式,还能较为准确地转换复杂的数学公式。

公式中出现的上标、下标等各种数学格式也分的清清楚楚:

Nougat 还能识别表格:

扫描产生畸变的文本也能处理:

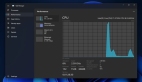
不过,Nougat 生成的文档中不包含图片,如下面的柱状图:
看到这,网友纷纷表示:(转换)效果真是绝了。

方法概述
本文架构是一个编码器 - 解码器 Transformer 架构,允许端到端的训练,并以 Donut 架构为基础。该模型不需要任何 OCR 相关输入或模块,文本由网络隐式识别。该方法的概述见下图 1。
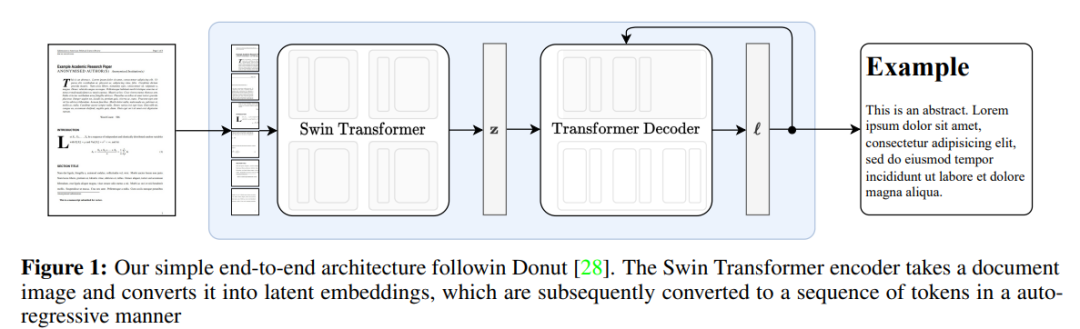
该研究用到了 2 个 Swin Transformer ,一个参数量为 350M,可处理的序列长度为 4096,另一参数量为 250M,序列长度为 3584。在推理过程中,使用贪婪解码生成文本。
在图像识别任务中,使用数据增强技术来提高泛化能力往往是有益的。由于本文只研究数字化的学术研究论文,因此需要使用一些变换来模拟扫描文件的不完美和多变性。这些变换包括侵蚀、扩张、高斯噪声、高斯模糊、位图转换、图像压缩、网格变形和弹性变换 。每种变换都有固定的概率应用于给定的图像。这些变换在 Albumentations 库中实现。在训练过程中,研究团队也会通过随机替换 token 的方式,对实际文本添加扰动。

每种变换的效果概览
数据集构建与处理
据研究团队所知,目前还没有 PDF 页面和相应源代码的配对数据集,因此他们从 arXiv 上开放获取的文章中创建了自己的数据集。为了数据多样性,数据集中还包括 PubMed Central (PMC) 开放访问非商业数据集的一个子集。预训练期间,还加入了部分行业文档库 (IDL)。
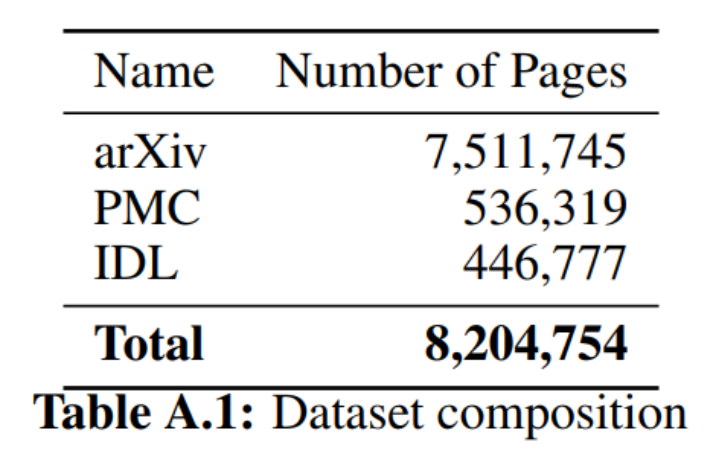
表 1 数据集构成
在处理数据集的过程中,研究团队也将不同来源的数据进行了合适的处理,下图展示了他们对 arXiv 文章进行源代码收集并编译 PDF 的过程。详细内容请阅读全文。

源文件被转换成 HTML,然后再转换成 Markdown。
研究团队根据 PDF 文件中的分页符分割 markdown 文件,并将每个页面栅格化为图像以创建最终配对的数据集。在编译过程中,LaTeX 编译器自动确定 PDF 文件的分页符。由于他们不会为每篇论文重新编译 LaTeX 源文件,因此必须将源文件分割成若干部分,分别对应不同的页面。为此,他们使用 PDF 页面上的嵌入文本,并将其与源文本进行匹配。
但是,PDF 中的图形和表可能并不对应于它们在源代码中的位置。为了解决这个问题,研究团队使用 pdffigures2 在预处理步骤中删除这些元素。将识别出的字幕与 XML 文件中的字幕进行比较,根据它们的 Levenshtein 距离进行匹配。一旦源文档被拆分为单独的页面,删除的图形和表就会重新插入到每一页的末尾。为了更好地匹配,他们还使用 pylatexence -library 将 PDF 文本中的 unicode 字符替换为相应的 LaTeX 命令。
词袋匹配:首先,研究团队使用 MuPDF 从 PDF 中提取文本行,并对其进行预处理,删除页码和页眉 / 页脚。然后使用词袋模型与 TF-IDF 向量化器和线性支持向量机分类器。将模型拟合到以页码为标签的 PDF 行。然后,他们将 LaTeX 源代码分成段落,并预测每个段落的页码。理想情况下,预测将形成阶梯函数,但在实践中,信号将有噪音。为了找到最佳边界点,他们采用类似于决策树的逻辑,并最小化基于 Gini 不纯度的度量:
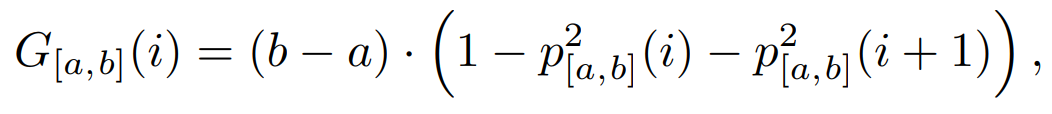
其中 是在区间 [a,b] 中选择具有预测页码 i 的元素的概率,该区间描述了哪些段落 (元素) 被考虑用于分割。
是在区间 [a,b] 中选择具有预测页码 i 的元素的概率,该区间描述了哪些段落 (元素) 被考虑用于分割。
区间 [a, b] 的最佳拆分位置 t 为:
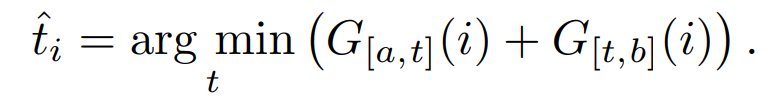
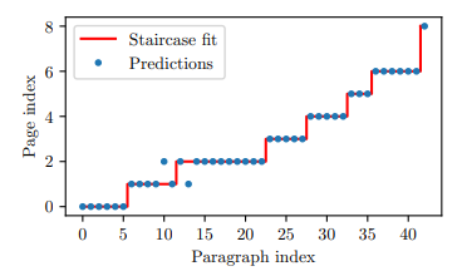
搜索过程从所有段落开始,对于后续的每个分页,搜索区间的下界设置为前一个分页位置。
模糊匹配:在第一次粗略的文档分割之后,研究团队尝试找到段落中的准确位置。通过使用 fuzzysearch 库,将预测分割位置附近的源文本与嵌入的 PDF 文本的前一页的最后一个句子和下一页的第一个句子进行比较,就可以达到这个目的。如果两个分隔点在源文本中的相同位置,则认为换页是准确的,得分为 1。另一方面,如果分割位置不同,则选择具有最小归一化 Levenshtein 距离的分割位置,并给出 1 减距离的分数。要包含在数据集中,PDF 页面的两个分页符的平均得分必须至少为 0.9。如此一来,所有页面的接受率约为 47%。
实验
实验中用到的文本包含三种类别:纯文本、数学表达式以及表格。
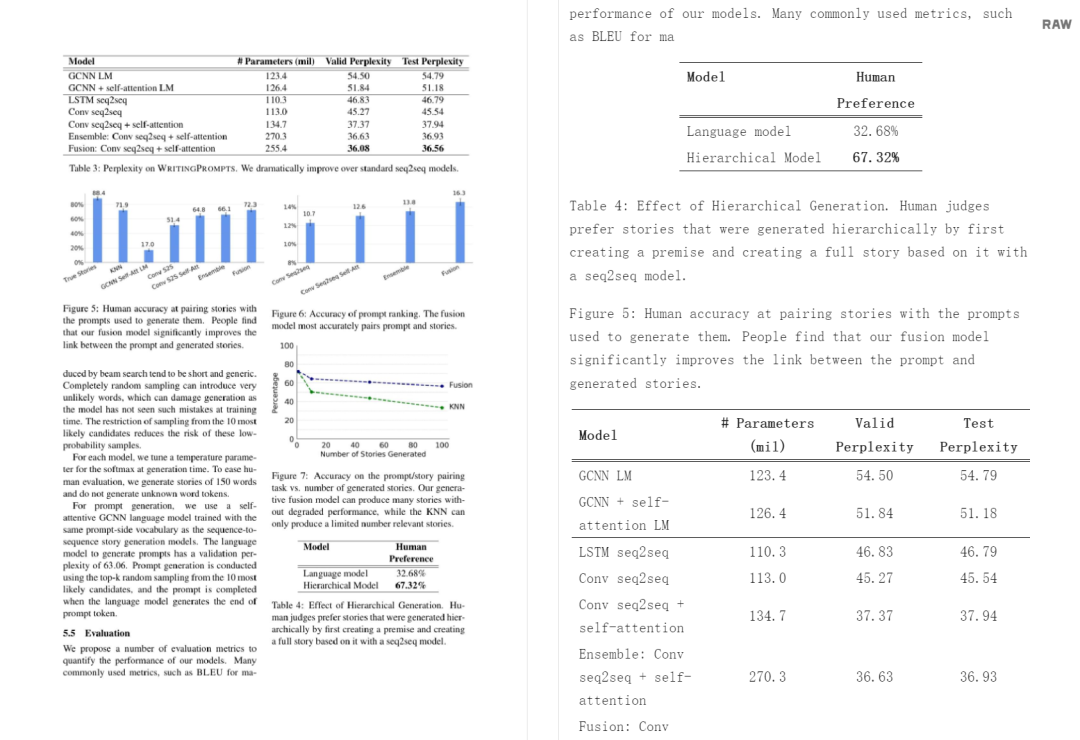
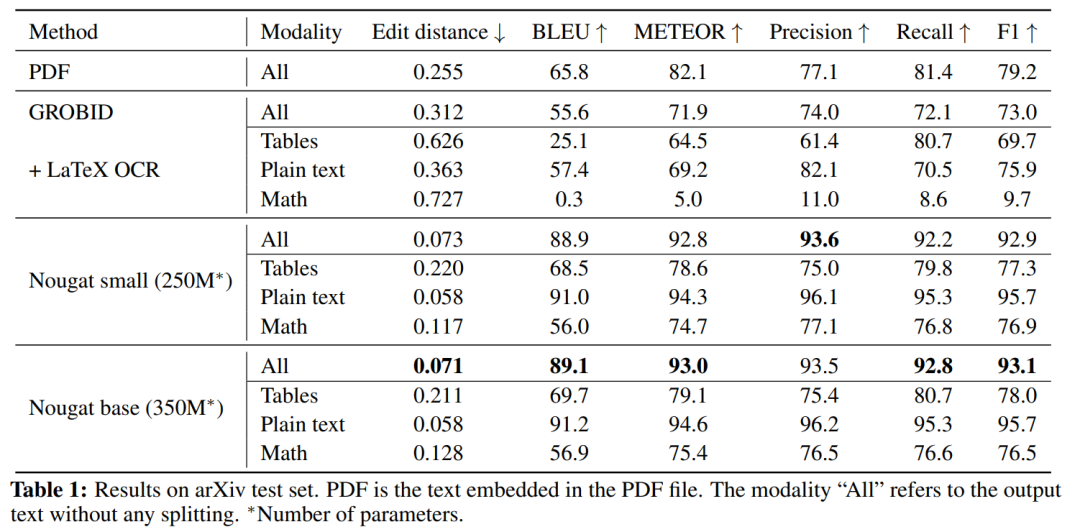
结果如表 1 所示。Nougat 优于其他方法,在所有指标中取得最高分,并且具有 250M 参数模型的性能与 350M 参数模型相当。
下图为 Nougat 优对一篇论文的转换结果:

Meta 表示,Nougat 在配备 NVIDIA A10G 显卡和 24GB VRAM 机器上可并行处理 6 个页面,生成速度在很大程度上取决于给定页面上的文本量。在不进行任何推理优化的情况下,基础模型每批次平均生成时间为 19.5s(token 数≈1400),与经典方法(GROBID 10.6 PDF/s )相比速度还是非常慢的,但 Nougat 可以正确解析数学表达式。