译者 | 朱先忠
审校 | 重楼
引言
可靠的模型评估是MLOP和LLMops的核心,负责指导关键决策,如部署哪个模型或提示符(以及是否部署)。在本文中,我们使用各种提示关键词来提示Google Research的FLAN-T5大型语言模型,试图将文本分类为礼貌或不礼貌两个类型。
在提示候选词中,我们发现,根据观察到的测试准确性,看起来表现最好的提示词实际上往往比其他提示候选词还差。对测试数据的仔细审查表明,这是由于不可靠的注释造成的。因此,在现实世界的应用程序中,您可能会为大型语言模型选择次优提示词(或在模型评估的指导下做出其他次优选择),除非您清理掉测试数据以确保其可靠性。
 选择好的提示词对于确保大型语言模型的准确响应至关重要
选择好的提示词对于确保大型语言模型的准确响应至关重要
虽然噪声注释的危害在训练数据中得到了很好的表征,但本文在测试数据中展示了它们经常被忽视的后果。
我目前的职务是Cleanlab的数据科学家,我很高兴能与大家分享高质量测试数据的重要性,以确保最佳大型语言模型的提示选择。
概述
你可以在链接处下载本文有关测试数据。
本文研究了斯坦福礼貌数据集的二元分类变体(在CC BY许可证v4.0下使用),其中的文本短语被标记为礼貌或不礼貌两种类型。我们使用包含700个短语的固定测试数据集来评估模型。
 显示文本和基本事实礼貌标签的数据集快照
显示文本和基本事实礼貌标签的数据集快照
标准做法是通过对照给定标签来评估分类模型的“好”的程度,例如模型在训练过程中没有看到的例子,通常被称为“测试”、“评估”或“验证”数据。这提供了一个数字指标来衡量模型A与模型B的优劣——如果模型A显示出更高的测试精度,我们估计它是更好的模型,并会选择将其部署在模型B之上。除了模型选择之外,相同的决策框架还可以应用于其他选择,如是否使用:超参数设置A或B、提示A或B,特征集A或B等。
真实世界测试数据中的一个常见问题是,一些例子的标签是不正确的,无论是由于人为注释错误、数据处理错误还是由于传感器噪声等因素导致。在这种情况下,测试准确性成为模型A和模型B之间相对性能的不太可靠的指标。让我们用一个非常简单的例子来说明这一点。想象一下,你的测试数据集中存在两个不礼貌的文本示例,但在不知不觉中,它们被(错误地)标记为“礼貌”类型。例如,在我们的斯坦福礼貌数据集中,我们看到一个真正的人类注释者错误地将“你现在疯了吗?!到底发生了什么?”(Are you crazy down here?! What the heck is going on?)这段文字标记为“礼貌”(polite)类型,而语言表达显然是很激动的。
现在,您的工作是选择最佳模型来对这些示例进行分类。模型A指出两个实例都是不礼貌的,模型B指出两个实例都是礼貌的。基于这些(不正确的)标签,模型A得分为0%,而模型B得分为100%——你选择模型B进行部署!但请稍等一下再想想:到底哪种模型实际上更强一些呢?
尽管上述类似影响微不足道,而且许多人都意识到现实世界的数据充满了标签错误,但人们往往只关注训练数据中的噪声标签,忘记了仔细策划测试数据——即使当其指导了关键决策的时候。本文使用真实数据说明了高质量测试数据在指导大型语言模型提示选择方面的重要性,并展示了一种通过算法技术轻松提高数据质量的方法。
观察测试精度与清洁测试精度
在这里,我们考虑由同一组文本示例构建的两个可能的测试集,它们只在某些(~30%)标签上有所不同。代表你用来评估准确性的典型数据,一个版本的标签来源于每个例子的单个注释(人工评分器),我们将把在此版本上计算的模型预测的准确性报告为观察测试准确性(Observed Test Accuracy)。同一测试集的第二个更干净的版本具有高质量的标签,这些标签是通过每个示例的许多一致注释(源自多个人工评分者)之间的共识建立的。我们将在清洁版本上测量的精度报告为清洁测试精度(Clean Test Accuracy)。因此,清洁测试精度更紧密地反映了您所关心的内容(实际模型部署性能),但在大多数应用程序中,观察测试准确性是您所能观察到的全部内容,除非您首先清洁测试数据!
下面是两个测试示例,其中单个人工注释器错误地标记了示例,但由许多人工注释器组成的小组同意正确的标记。
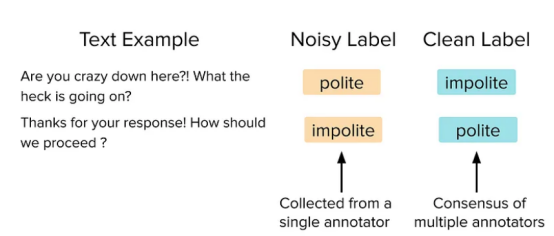
需要说明的是,从单个注释器收集的橙色注释收集起来更便宜,但通常是不正确的。蓝色注释是从多个注释器中收集的,这些注释器更昂贵,但通常更准确。
在现实世界的项目中,你通常无法使用这种“清洁”(clean)的标签,所以你只能测量观察测试准确性。如果您正在根据此指标做出关键决策,例如使用哪种大型语言模型或提示,请确保首先验证标签是高质量的;否则,我们发现您可能会做出错误的决定,如接下来所展示的在选择礼貌分类提示时出现的情况。
噪声评估数据的影响
作为一种对文本礼貌进行分类的预测模型,使用预先训练的大型语言模型(LLM)是很自然的。在这里,我们特别使用了数据科学家最喜欢的大型语言模型——开源的FLAN-T5模型。为了让大型语言模型准确地预测文本的礼貌属性,我们必须给它提供正确的提示。提示工程可以非常敏感,微小的变化会极大地影响准确性!
下面显示的提示A和B(突出显示的文本)是思维链提示的两个不同示例,它们可以附加在任何文本样本前面,以便大型语言模型对其礼貌属性进行分类。这些提示结合了一些镜头和指令提示(稍后详细介绍),提供了示例、正确的响应和鼓励大型语言模型解释其推理的理由。这两个提示之间的唯一区别是高亮显示的文本实际上是从大型语言模型中获得响应。少数镜头的例子和推理保持不变。

思维链提示为模型提供了推理,说明为什么给出的每个文本示例的答案都是正确的。
决定哪种提示更好的自然方法是基于他们观察到的测试准确性。当用于提示FLAN-T5大型语言模型时,我们将在下面看到,提示A产生的分类在原始测试集上的观察测试精度高于提示B产生的分类。所以很明显,我们应该使用提示A部署我们的大型语言模型,对吧?回答是:不要那么快速作出决定!
当我们评估每个提示的清洁测试准确性时,我们发现提示B实际上比提示A好得多(提高了4.5个百分点)。由于清洁测试精度更能反映我们真正关心的真实性能,如果我们仅仅依赖原始测试数据而不检查其标签质量,我们就会做出错误的决定!

使用观察到的准确性,您可以更好地选择提示A。但是,当在清洁过的测试集上进行评估时,提示B实际上是更好的提示
这只是统计波动吗?
McNemar检验是评估ML准确性差异的统计学显著性的推荐方法。当我们应用该测试来评估700个文本示例中提示A与提示B之间4.5%的清洁测试准确性差异时,该差异具有高度统计学意义(p值=0.007,X²=7.086)。因此,所有证据都表明提示B是一个有意义的更好的选择——我们不应该没有通过仔细审核原始测试数据来选择它!
这是不是这两个提示碰巧出现的侥幸结果?
让我们也看看其他类型的提示,看看我们的两个思维链提示的结果是否只是巧合。
指令提示
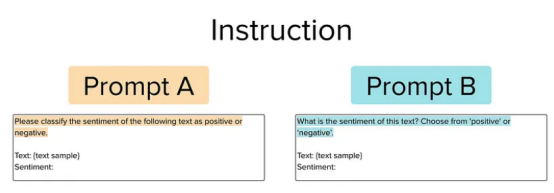
这种类型的提示只是向大型语言模型提供一条指令,说明它需要如何处理给定的文本示例。考虑以下两个提示,我们可能希望在其中进行选择。
少量训练(Few-Shot)提示
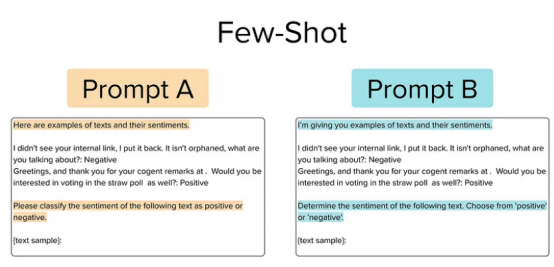
这种类型的提示使用两个指令,一个前缀和一个后缀,还包括来自文本语料库的两个(预先选择的)示例,以便向大型语言模型提供所需输入输出映射的清晰演示。考虑以下两个提示,我们可能希望在其中进行选择。
模板化提示
这种类型的提示除了选择题格式外,还使用了两条指令,一个可选前缀和一个后缀,这样模型就可以作为选择题答案进行分类,而不是直接用预测类进行响应。考虑以下两个提示,我们可能希望在其中进行选择。
各种类型提示的结果对比
除此之外,我们还评估了具有这三种额外类型提示的同一FLAN-T5大型语言模型的分类性能。通过绘制以下所有提示实现的观察测试精度与清洁测试精度,我们看到许多提示对都存在相同的上述问题,依赖观察到的检测精度会导致选择实际上更差的提示。
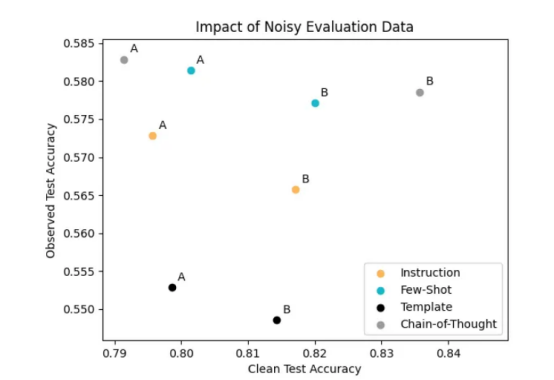
作为一名使用可用测试数据的提示工程师,您可以选择左上角的灰色A提示(最高观测精度),但最佳提示实际上是右上角的灰度B提示(最高清洁精度)。
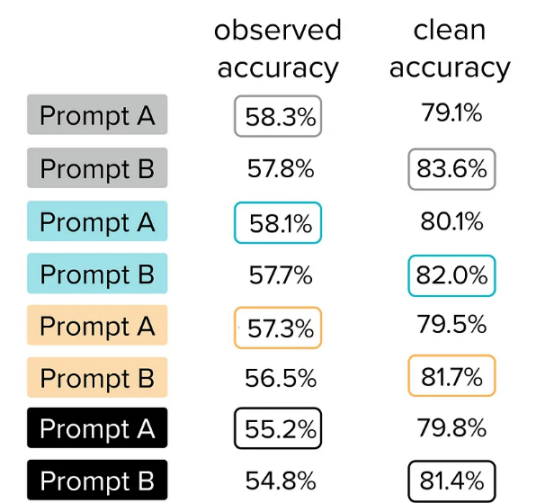
仅根据观察到的测试准确性,您将倾向于在每种类型的提示中选择“A”提示而不是“B”提示。然而,每种提示类型的更好提示实际上是提示B(它具有更高的清洁测试精度)。这些提示对中的每一个都强调了验证测试数据质量的必要性,否则,由于数据问题(如嘈杂的注释),您可能会做出次优决策。
由于存在较高的观察准确性,所有A提示似乎都更好,但当根据实际测试数据进行评估时,所有B提示在客观上都更好。
您还可以在该图中看到,所有A提示观察到的精度都是如何圈出的,这意味着它们的精度高于B提示。类似地,所有B提示的清洁准确度都被圈出,这意味着它们的准确度高于B提示的准确度。就像本文开头的简单示例一样,您倾向于选择所有的A提示,而实际上B提示做得更好。
改进可用的测试数据以实现更可靠的评估
希望高质量评价数据的重要性是显而易见的。让我们来看看修复可用测试数据的几种方法。
手动校正
确保测试数据质量的最简单方法就是简单地手工审核!确保仔细查看每个示例,以验证其标记是否正确。根据测试集的大小,这可能可行,也可能不可行。如果你的测试集相对较小(大约100个例子),你可以仔细查看它们,并做出任何必要的更正。如果你的测试集很大(1000多个例子),那么手工完成这项工作将过于耗时和耗费精力。我们的测试集相当大,所以我们不会使用这种方法!
算法校正
评估可用(可能有噪声)测试集的另一种方法是使用以数据为中心的人工智能算法来诊断可以解决的问题,以获得同一数据集的更可靠版本(而不必收集许多额外的人工注释)。在这里,我们使用Confident Learning算法(通过开源的cleanlab软件包)来检查我们的测试数据,这些数据会自动估计哪些示例被错误标记。然后,我们只检查这些自动检测到的标签问题,并根据需要修复它们的标签,以生成更高质量的测试数据集版本。我们将在这个版本的测试数据集上进行的模型精度测量称为CL测试精度。
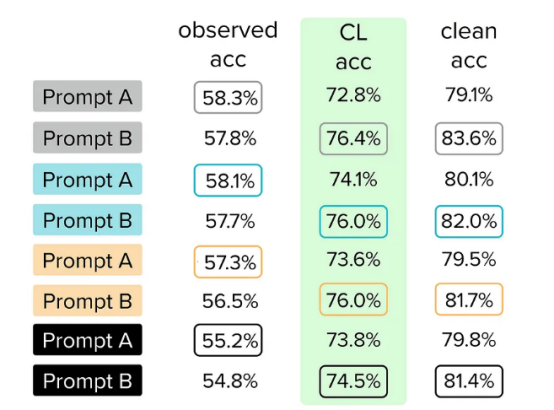
所有B提示的CL测试精度都更高。使用CL,我们更正了原始测试数据,现在可以信任我们的模型并及时做出决定。
使用这个新的CL校正测试集进行模型评估,我们看到以前的所有B提示现在都正确地显示出比A提示更高的准确性。这意味着我们可以相信,基于CL校正测试集做出的决策比基于有噪声的原始测试数据做出的决策更可靠。
当然,自信学习不能神奇地识别任何数据集中的所有错误。该算法检测标记错误的效果将取决于基线ML模型的合理预测,即使如此,某些类型的系统引入的错误仍将无法检测(例如,如果我们完全交换两类的定义)。
关于可以证明自信学习有效的数学假设的精确列表,请参阅Northcutt等人的原始论文。对于许多真实世界的文本/图像/音频/表格数据集,该算法似乎至少提供了一种有效的方法,可以将有限的数据审查资源集中在大型数据集中最可疑的例子上。
因此,你并不总是需要花费时间/资源来策划一个“完美”的评估集——使用Confident Learning等算法来诊断和纠正可用测试集中可能存在的问题,可以提供高质量的数据,以确保最佳的提示和模型选择。
最后,除非另有说明,否则本文中所有图片均由作者本人提供。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Beware of Unreliable Data in Model Evaluation: A LLM Prompt Selection case study with Flan-T5,作者:Chris Mauck