2023年5月6日,在昇腾AI开发者峰会上,华为正式发布了面向算子开发场景的昇腾Ascend C编程语言。Ascend C原生支持C/C++编程规范,通过多层接口抽象、并行编程范式、孪生调试等技术,极大提高了算子的开发效率,帮助AI开发者低成本完成算子开发和模型调优部署。
昇腾AI软硬件基础
和CUDA开发的算子运行在GPU上一样,基于Ascend C开发的算子,可以通过异构计算架构CANN(Compute Architecture for Neural Networks)运行在昇腾AI处理器(可简称NPU)上。CANN是使能昇腾AI处理器的一个软件栈,通过软硬件协同优化,能够充分发挥昇腾AI处理器的强大算力。从下面的架构图可以清楚的看到,使用Ascend C编程语言开发的算子通过编译器编译和运行时调度,最终运行在昇腾AI处理器上。
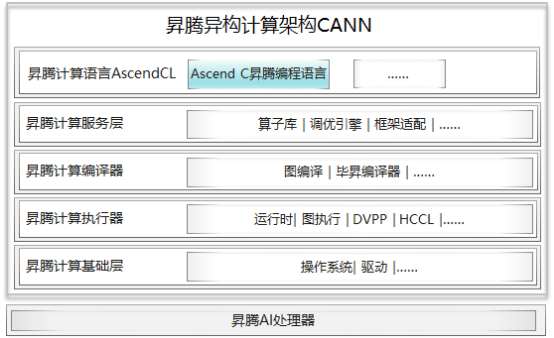
我们知道,通用计算就是我们常写的一些在CPU上运行的计算,它擅长逻辑控制和串行计算,而AI计算相对通用计算来说,更擅长并行计算,可支持大规模的计算密集型任务。如下面左图所示,做一个矩阵乘,使用CPU计算需要三层for循环,而右图在昇腾AI处理器上使用vector计算单元,只需要两层for循环,最小计算代码能同时计算多个数据的乘加,更近一步,如果使用Cube计算单元,只需要一条语句就能完成一个矩阵乘的计算,这就是我们所说的SIMD(单指令多数据)。因此,我们通常使用AI处理器来进行大量的并行计算。
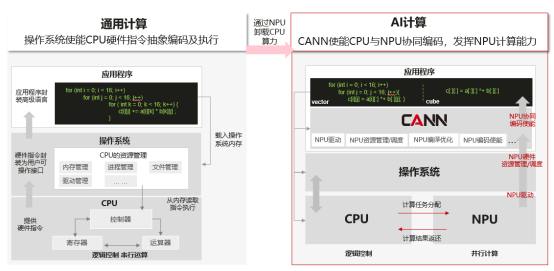
NPU不能独立运行,需要与CPU协同工作,可以看成是CPU的协处理器,CPU负责整个操作系统运行,管理各类资源并进行复杂的逻辑控制,而NPU主要负责并行计算任务。在基于CPU+NPU的异构计算架构中,NPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为主机端(host),而NPU所在位置称为设备端(device),示意图如下:

这里再详细介绍一下昇腾AI处理器。昇腾AI处理器有不同的型号和产品形态,小到模块、加速卡,大到服务器、集群。昇腾AI处理器里面最核心的部件是AI Core,有多个,是神经网络加速的计算核心,每一个AI Core就相当于我们大家平时理解的多核cpu里的每个核,使用Ascend C编程语言开发的算子就运行在AI Core上,因为核心的神经网络计算的加速都来源于AI Core的算力。
AI Core内部的并行计算架构抽象如下图所示:
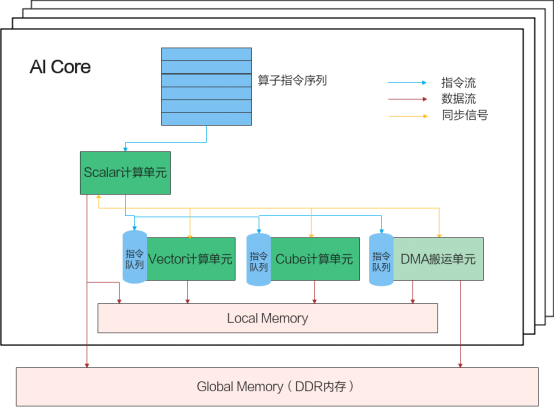
这个并行计算架构抽象核心包含了几个大的部件,AI Core外面有一个Gobal Memory,是多个AI Core共享的,在AI Core内部有一块本地内存Local Memory,因为靠近计算单元,所以它的带宽会非常高,相对的容量就会很小,比如一般是几百K到1M。AI Core内部的核心组件有三个计算单元,标量计算单元、向量计算单元,矩阵计算单元。另外还有一个DMA搬运单元,DMA搬运单元负责在Global Memory和Local Memory之间搬运数据。
AI Core内部的异步并行计算过程:Scalar计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发射给对应单元的指令队列,向量计算单元、矩阵计算单元、数据搬运单元异步并行执行接收到的指令。该过程可以参考上图中蓝色箭头所示的指令流。不同的指令间有可能存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar计算单元也会给对应单元下发同步指令。各单元之间的同步过程可以参考上图中的橙色箭头所示的同步信号流。
AI Core内部数据处理的基本过程:DMA搬入单元把数据搬运到Local Memory,Vector/Cube计算单元完成数据,并把计算结果写回Local Memory,DMA搬出单元把处理好的数据搬运回Global Memory。该过程可以参考上图中的红色箭头所示的数据流。
Ascend C编程模型基础
Ascend C编程范式
Ascend C编程范式是一种流水线式的编程范式,把算子核内的处理程序,分成多个流水任务,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。流水编程范式应用了流水线并行计算方法。
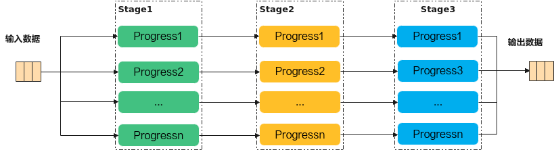
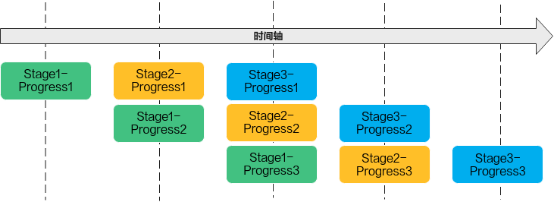
若n=3,即待处理的数据被切分成3片,则上图中的流水任务运行起来的示意图如下,从运行图中可以看出,对于同一片数据,Stage1、Stage2、Stage3之间的处理具有依赖关系,需要串行处理;不同的数据切片,同一时间点,可以有多个任务在并行处理,由此达到任务并行、提升性能的目的。
Ascend C分别针对Vector、Cube编程设计了不同的流水任务。开发者只需要完成基本任务的代码实现即可,底层的指令同步和并行调度由Ascend C框架实现,开发者无需关注。
矢量编程范式
矢量编程范式把算子的实现流程分为3个基本任务:CopyIn,Compute,CopyOut。CopyIn负责搬入操作,Compute负责矢量计算操作,CopyOut负责搬出操作。

我们只需要根据编程范式完成基本任务的代码实现就可以了,底层的指令同步和并行调度由Ascend C框架来实现。
那Ascend C是怎么完成不同任务之间的数据通信和同步的呢?这里Ascend C提供了Queue队列管理的API,主要就是两个队列操作API EnQue、DeQue以及内存的逻辑抽象。
矢量编程中使用到的逻辑位置(QuePosition)定义如下:
- 搬入数据的存放位置:VECIN;
- 计算中间变量的位置:VECCALC;
- 搬出数据的存放位置:VECOUT。
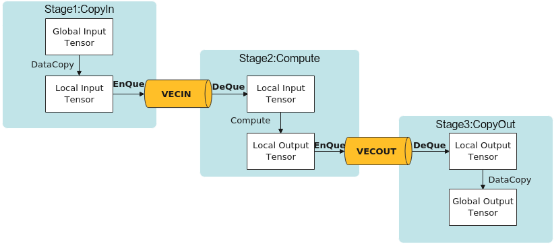
从前面可以看到,矢量编程主要分为CopyIn、Compute、CopyOut三个任务。CopyIn任务中将输入数据从Global内存搬运至Local内存后,需要使用EnQue将LocalTensor放入VECIN的Queue中;Compute任务等待VECIN的Queue中LocalTensor出队之后才可以完成矢量计算,计算完成后使用EnQue将计算结果LocalTensor放入到VECOUT的Queue中;CopyOut任务等待VECOUT的Queue中LocalTensor出队,再将其拷贝到Global内存。这样 ,Queue队列就完成了三个任务间的数据通信和同步。具体流程和流程图如下:
- Stage1:CopyIn任务。使用DataCopy接口将GlobalTensor数据拷贝到LocalTensor。
使用EnQue接口将LocalTensor放入VECIN的Queue中。 - Stage2:Compute任务。使用DeQue接口从VECIN中取出LocalTensor。
使用Ascend C接口完成矢量计算。
使用EnQue接口将计算结果LocalTensor放入到VECOUT的Queue中。 - Stage3:CopyOut任务。
使用DeQue接口从VECOUT的Queue中去除LocalTensor。
使用DataCopy接口将LocalTensor拷贝到GlobalTensor上。
这样我们的kernel实现代码就很清晰了。先初始化内存和队列,然后通过编程范式实现CopyIn、Compute、CopyOut三个Stage就可以了。
SPMD并行编程-多核
最前面介绍昇腾AI处理器的时候,有介绍过AI Core是有多个的,那我们怎么把多个AI Core充分利用起来呢?常用的并行计算方法中,有一种SPMD(Single-Program Multiple-Data)数据并行的方法,简单说就是将数据分片,每片数据经过完整的一个数据处理流程。这个就能和昇腾AI处理器的多核匹配上了,我们将数据分成多份,每份数据的处理运行在一个核上,这样每份数据并行处理完成,整个数据也就处理完了。Ascend C是SPMD(Single-Program Multiple-Data)编程,多个AI Core共享相同的指令代码,每个核上的运行实例唯一的区别是就是block_idx(内置变量)不同,这样我们就可以通过block_idx来区分不同的核,只要对Global Memory上的数据地址进行切分偏移,就可以让每个核处理自己对应的那部分数据了。
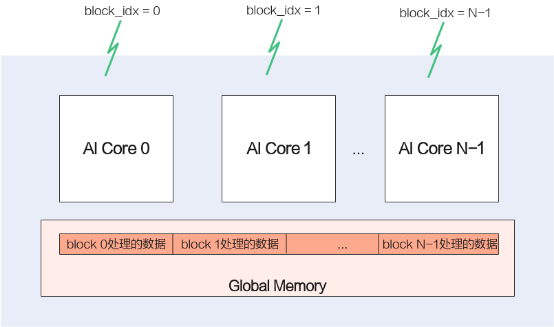
算子被调用时,所有的计算核心都执行相同的实现代码,入口函数的入参也是相同的。每个核上处理的数据地址需要在起始地址上增加block_idx*BLOCK_LENGTH(每个block处理的数据长度)的偏移来获取。这样也就实现了多核并行计算的数据切分。
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// get start index for current core, core parallel
GM_ADDR xGmOffset = x + BLOCK_LENGTH * GetBlockIdx();
GM_ADDR yGmOffset = y + BLOCK_LENGTH * GetBlockIdx();
GM_ADDR zGmOffset = z + BLOCK_LENGTH * GetBlockIdx();
xGm.SetGlobalBuffer((__gm__ half*)xGmOffset, BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)yGmOffset, BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)zGmOffset, BLOCK_LENGTH);
……
}
……
}
Ascend C API介绍
在整个kernel实现中,最最核心的代码就是Add(zLocal, xLocal, yLocal, TILE_LENGTH);通过一个Ascend C提供的API接口完成了所有数据的加法计算,对,没看错,就是这个接口完成了计算。
接下来就介绍下Ascend C提供的API。Ascend C算子采用标准C++语法和一组类库API进行编程,类库API主要包含以下几种,大家可以在核函数的实现中根据自己的需求选择合适的API:
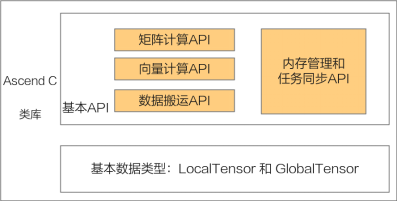
- 计算类API,包括标量计算API、向量计算API、矩阵计算API,分别实现调用Scalar计算单元、Vector计算单元、Cube计算单元执行计算的功能。
- 数据搬运API,上述计算API基于Local Memory数据进行计算,所以数据需要先从Global Memory搬运至Local Memory,再使用计算接口完成计算,最后从Local Memory搬出至Global Memory。执行搬运过程的接口称之为数据搬移接口,比如DataCopy接口。
- 内存管理API,用于分配管理内存,比如AllocTensor、FreeTensor接口。
- 任务同步API,完成任务间的通信和同步,比如EnQue、DeQue接口。
Ascend C API的计算操作数都是Tensor类型:GlobalTensor和LocalTensor。
介绍完Ascend C API种类后,下面来解释下为什么一个Add接口就可以计算所有的数。原来Ascend C编程模型是基于SIMD(单指令多数据)架构的,单条指令可以完成多个数据操作,同时在API内部封装了一些指令的高级功能。
算子执行基本流程
前面有提到,在异构计算架构中,NPU与CPU是协同工作的,在Ascend C编程模型中,我们需要实现NPU侧的代码和CPU侧的代码。在NPU侧的代码我们通常叫做Kernel实现代码,CPU侧的代码我们一般叫做Host实现代码,一份完整的Ascend C代码,通常包括Host侧实现代码和Kernel侧实现代码。Ascend C算子执行的基本流程如下:
- 初始化Device设备;
- 创建Context绑定设备;
- 分配Host内存,并进行数据初始化;
- 分配Device内存,并将数据从Host上拷贝到Device上;
- 用内核调用符<<<>>>调用核函数完成指定的运算;
- 将Device上的运算结果拷贝回Host;
- 释放申请的资源。
核函数介绍
上面的流程中,最重要的一步就是调用核函数来进行并行计算任务。核函数(Kernel Function)是Ascend C算子Device侧实现的入口。在核函数中,需要为在AI核上执行的代码规定要进行的数据访问和计算操作。
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z);
上面这个是一个核函数声明的示例,extern "C"表示核函数按照类C的编译和连接规约来编译和连接,__global__函数类型限定符表示它是一个核函数, __aicore__函数类型限定符表示该核函数在device侧的AI Core上执行。参数列表中的变量类型限定符__gm__,表明该指针变量指向Global Memory上某处内存地址,注意这里的入参只能支持指针或C/C++内置数据类型,样例里指针使用的类型为uint8_t,在后续的使用中需要将其转化为实际的指针类型。
Ascend C编程模型中的核函数采用内核调用符<<<...>>>来调用,样例如下:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
kernel_name即为上面讲的核函数名称,argument list是核函数的函数入参,在<<<>>>中间,有3个参数:
- blockDim,规定了核函数将会在几个核上执行,我们可以先设置为1;
- l2ctrl,保留参数,暂时设置为固定值nullptr,我们不用关注;
- stream,使用aclrtCreateStream创建,用于多线程调度。
样例开发讲解
样例代码结构
|-- CMakeLists.txt //编译工程文件
|-- cmake //编译工程文件
|-- data_utils.h //数据读入写出函数
|-- input //存放脚本生成的输入数据目录
|-- leakyrelu_custom.cpp //算子kernel实现
|-- leakyrelu_custom.py //输入数据和真值数据生成脚本文件
|-- leakyrelu_custom_tiling.h //host侧tiling函数
|-- main.cpp //主函数,host侧调用代码,含cpu域及npu域调用
|-- output //存放算子运行输出数据和标杆数据的目录
|-- readme.md //执行命令说明
|-- run.sh //运行脚本
主要文件
输入数据和真值数据生成脚本文件:KERNEL_NAME.py。
根据算子的输入输出编写生成输入数据和真值数据的脚本。
本例子生成8 * 200 * 1024大小的fp16数据:
……
def gen_golden_data_simple():
total_length_imm = 8 * 200 * 1024
tile_num_imm = 8
//生成tilling的bin文件
total_length = np.array(total_length_imm, dtype=np.uint32)
tile_num = np.array(tile_num_imm, dtype=np.uint32)
scalar = np.array(0.1, dtype=np.float32)
tiling = (total_length, tile_num, scalar)
tiling_data = b''.join(x.tobytes() for x in tiling)
with os.fdopen(os.open('./input/tiling.bin', WRITE_FILE_FLAGS, PEN_FILE_MODES_640), 'wb') as f:
f.write(tiling_data)
//生成输入数据
input_x = np.random.uniform(-100, 100, [8, 200, 1024]).astype(np.float16)
//生成golden数据,功能和LeakyRelu相同
golden = np.where(input_x > 0, input_x, input_x * scalar).astype(np.float16)
input_x.tofile("./input/input_x.bin")
golden.tofile("./output/golden.bin")
编译工程文件:CMakeLists.txt
用于编译cpu侧或npu侧运行的Ascend C算子。主要关注CMakeLists.txt中源文件是否全部列全。
调用算子的应用程序:main.cpp
主要是内存申请,数据拷贝和文件读写等操作,并最终调用算子,相关API的介绍如下:
- AscendCL初始化接口aclInit,用于运行时接口AscendCL的初始化,是程序最先调用的接口;aclrtCreateContext和aclrtCreateStream用于创建Context和Stream,主要用于线程相关的资源管理。
- aclrtMallocHost接口,用于在Host上申请内存:aclError aclrtMallocHost(void **hostPtr, size_t size)
这个函数和C语言中的malloc类似,用于在Host上申请一定字节大小的内存,其中hostPtr是指向所分配内存的指针,size是申请的内存大小,如果需要释放这块内存的话,使用aclrtFreeHost接口释放,这和C语言中的free函数对应。 - aclrtMalloc接口,用于在Device上申请内存:aclError aclrtMalloc(void **devPtr, size_t size, aclrtMemMallocPolicy policy)
和Host上的内存申请接口相比,多了一个policy参数,用于设置内存分配规则,一般设置成ACL_MEM_MALLOC_HUGE_FIRST就可以了。使用完毕后可以用对应的aclrtFree接口释放内存。 - aclrtMemcpy接口,用于Host和Device之间数据拷贝:前面申请的内存区分了Host内存和Device内存,那就会涉及到数据同步的问题,aclrtMemcpy就是用于Host和Device之间数据通信的接口:
aclError aclrtMemcpy(void *dst, size_t destMax, const void *src, size_t count, aclrtMemcpyKind kind)
其中src指向数据源,而dst是目标内存地址,destMax 是目的内存地址的最大内存长度,count是拷贝的字节数,其中aclrtMemcpyKind控制复制的方向:ACL_MEMCPY_HOST_TO_HOST、ACL_MEMCPY_HOST_TO_DEVICE、ACL_MEMCPY_DEVICE_TO_HOST和ACL_MEMCPY_DEVICE_TO_DEVICE,像ACL_MEMCPY_HOST_TO_DEVICE就是将Host上数据拷贝到Device上。 - 核心函数为CPU侧的调用kernel函数
ICPU_RUN_KF(leakyrelu_custom, blockDim, x, y, usrWorkSpace, tiling);
和NPU侧调用的
leakyrelu_custom_do(blockDim, nullptr, stream, xDevice, yDevice, workspaceDevice, tilingDevice);
完整代码如下:
//This file constains code of cpu debug and npu code.We read data from bin file and write result to file.
#include "data_utils.h"
#include "leakyrelu_custom_tiling.h"
#ifndef __CCE_KT_TEST__
#include "acl/acl.h"
extern void leakyrelu_custom_do(uint32_t coreDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y,
uint8_t* workspace, uint8_t* tiling);
#else
#include "tikicpulib.h"
extern "C" __global__ __aicore__ void leakyrelu_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling);
#endif
int32_t main(int32_t argc, char* argv[])
{
size_t tilingSize = sizeof(LeakyReluCustomTilingData);
size_t usrWorkspaceSize = 4096;
size_t sysWorkspaceSize = 16 * 1024 * 1024;
uint32_t blockDim = 8;
#ifdef __CCE_KT_TEST__ //CPU侧调用
//申请内存用于存放workspace和tilling数据
uint8_t* usrWorkSpace = (uint8_t*)AscendC::GmAlloc(usrWorkspaceSize);
uint8_t* tiling = (uint8_t*)AscendC::GmAlloc(tilingSize);
ReadFile("./input/tiling.bin", tilingSize, tiling, tilingSize);
size_t inputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
size_t outputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
//申请内存用于存放输入和输出数据
uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize);
uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize);
//获取输入数据
ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);
// PrintData(x, 16, printDataType::HALF);
//在AIV上执行
AscendC::SetKernelMode(KernelMode::AIV_MODE);
//调用kernel函数
ICPU_RUN_KF(leakyrelu_custom, blockDim, x, y, usrWorkSpace, tiling); // use this macro for cpu debug
// PrintData(y, 16, printDataType::HALF);
WriteFile("./output/output_y.bin", y, outputByteSize);
AscendC::GmFree((void *)x);
AscendC::GmFree((void *)y);
AscendC::GmFree((void *)usrWorkSpace);
AscendC::GmFree((void *)tiling);
#else //NPU侧调用
CHECK_ACL(aclInit(nullptr));
aclrtContext context;
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
uint8_t *xHost, *yHost, *tilingHost, *workspaceHost;
uint8_t *xDevice, *yDevice, *tilingDevice, *workspaceDevice;
//申请host上tilling内存并读入tilling数据
CHECK_ACL(aclrtMallocHost((void**)(&tilingHost), tilingSize));
ReadFile("./input/tiling.bin", tilingSize, tilingHost, tilingSize);
//申请host上workspace内存
CHECK_ACL(aclrtMallocHost((void**)(&workspaceHost), tilingSize));
size_t inputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
size_t outputByteSize = blockDim * 200 * 1024 * sizeof(uint16_t); // uint16_t represent half
size_t workspaceByteSize = sysWorkspaceSize + usrWorkspaceSize;
//申请host和device上的输入输出内存和device上的workspace和tilling内存
CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&workspaceHost), workspaceByteSize));
CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&tilingDevice, tilingSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&workspaceDevice, workspaceByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
// PrintData(xHost, 16, printDataType::HALF);
//从host上拷贝输入数据和tilling数据到device
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(tilingDevice, tilingSize, tilingHost, tilingSize, ACL_MEMCPY_HOST_TO_DEVICE));
//调用核函数
leakyrelu_custom_do(blockDim, nullptr, stream, xDevice, yDevice, workspaceDevice, tilingDevice);
//等待核函数运行完成
CHECK_ACL(aclrtSynchronizeStream(stream));
//拷回运行结果到host
CHECK_ACL(aclrtMemcpy(yHost, outputByteSize, yDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
// PrintData(yHost, 16, printDataType::HALF);
WriteFile("./output/output_y.bin", yHost, outputByteSize);
//释放资源
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(workspaceDevice));
CHECK_ACL(aclrtFree(tilingDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(workspaceHost));
CHECK_ACL(aclrtFreeHost(tilingHost));
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());
#endif
return 0;
}
一键式编译运行脚本run.sh
编译和运行应用程序。
cpu侧运行命令:
bash run.sh leakyrelu_custom ascend910B1 VectorCore cpu
npu侧运行命令:
bash run.sh leakyrelu_custom ascend910B1 VectorCore npu
参数含义如下:
bash run.sh <kernel_name> <soc_version> <core_type> <run_mode>
<kernel_name>表示需要运行的算子。
<soc_version>表示算子运行的AI处理器型号。
<core_type>表示在AI Core上或者Vector Core上运行,参数取值为AiCore/VectorCore。
<run_mode>表示算子以cpu模式或npu模式运行,参数取值为cpu/npu。
kernel实现
函数原型定义
本样例中,函数名为leakyrelu_custom,根据对算子输入输出的分析,确定有2个参数x,y,其中x为输入内存,y为输出内存。核函数原型定义如下所示:
extern "C" __global__ __aicore__ void leakyrelu_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling){ }
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行;为方便起见,统一使用GM_ADDR宏修饰入参,GM_ADDR宏定义:
#define GM_ADDR __gm__ uint8_t* __restrict__
获取tilling数据,并调用算子类的Init和Process函数。
算子类的Init函数,完成内存初始化相关工作,Process函数完成算子实现的核心逻辑。
extern "C" __global__ __aicore__ void leakyrelu_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelLeakyRelu op;
op.Init(x, y, tilingData.totalLength, tilingData.tileNum, tilingData.scalar);
op.Process();
}
对核函数的调用进行封装
封装后得到leakyrelu_custom_do函数,便于主程序调用。#ifndef __CCE_KT_TEST__表示该封装函数仅在编译运行NPU侧的算子时会用到,编译运行CPU侧的算子时,可以直接调用add_custom函数。调用核函数时,除了需要传入输入输出参数x,y,切分相关参数tiling,还需要传入blockDim(核函数执行的核数), l2ctrl(保留参数,设置为nullptr), stream(应用程序中维护异步操作执行顺序的stream)来规定核函数的执行配置。
#ifndef __CCE_KT_TEST__
// call of kernel function
void leakyrelu_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y,
uint8_t* workspace, uint8_t* tiling)
{
leakyrelu_custom<<<blockDim, l2ctrl, stream>>>(x, y, workspace, tiling);
}
#endif
获取tiling参数
主要从tilingPointer中获取tiling的参数totalLength(总长度)、tileNum(切分个数,单核循环处理数据次数)和scalar(LeakyRelu计算标量)。
#define GET_TILING_DATA(tilingData, tilingPointer) \
LeakyReluCustomTilingData tilingData; \
INIT_TILING_DATA(LeakyReluCustomTilingData, tilingDataPointer, tilingPointer); \
(tilingData).totalLength = tilingDataPointer->totalLength; \
(tilingData).tileNum = tilingDataPointer->tileNum; \
(tilingData).scalar = tilingDataPointer->scalar;
#endif // LEAKYRELU_CUSTOM_TILING_H
Init函数
主要获取tiling数据后,设置单核上gm的地址和Buffer的初始化。
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t tileNum, float scalar)
{
ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");
this->blockLength = totalLength / GetBlockNum();
this->tileNum = tileNum;
this->scalar = static_cast<half>(scalar);
ASSERT(tileNum != 0 && "tile num can not be zero!");
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + this->blockLength * get_block_idx(), this->blockLength);
yGm.SetGlobalBuffer((__gm__ half*)y + this->blockLength * get_block_idx(), this->blockLength);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueY, BUFFER_NUM, this->tileLength * sizeof(half));
}
Process函数
主要实现三个CopyIn、Compute、CopyOut这三stage。
__aicore__ inline void Process()
{
// loop count need to be doubled, due to double buffer
int32_t loopCount = this->tileNum * BUFFER_NUM;
// tiling strategy, pipeline parallel
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
CopyIn函数
负责从Global Memory拷贝数据到Local Memory,并将数据加入Queue
__aicore__ inline void CopyIn(int32_t progress)
{
// alloc tensor from queue memory
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
// copy progress_th tile from global tensor to local tensor
DataCopy(xLocal, xGm[progress * tileLength], tileLength);
// enque input tensors to VECIN queue
inQueueX.EnQue(xLocal);
}
Compute函数
负责从Queue中取出数据,进行计算,并将结果放入Queue
__aicore__ inline void Compute(int32_t progress)
{
// deque input tensors from VECIN queue
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = outQueueY.AllocTensor<half>();
// call LeakyRelu instr for computation
LeakyRelu(yLocal, xLocal, scalar, tileLength);
// enque the output tensor to VECOUT queue
outQueueY.EnQue<half>(yLocal);
// free input tensors for reuse
inQueueX.FreeTensor(xLocal);
}
CopyOut函数
负责从Queue中将数据取出,并将数据从Local Memory拷贝到Global Memory。
__aicore__ inline void CopyOut(int32_t progress)
{
// deque output tensor from VECOUT queue
LocalTensor<half> yLocal = outQueueY.DeQue<half>();
// copy progress_th tile from local tensor to global tensor
DataCopy(yGm[progress * tileLength], yLocal, tileLength);
// free output tensor for reuse
outQueueY.FreeTensor(yLocal);
}
编译和执行
在CPU侧执行
执行结果如下:
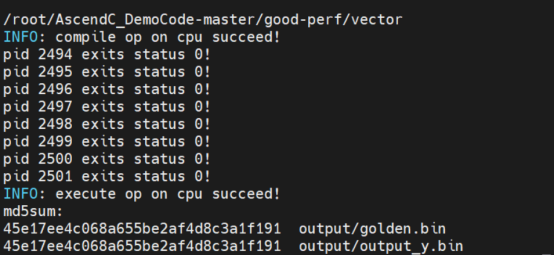
可以看到最后的输出结果output_y.bin和标杆数据golden.bin的MD5值相同,说明计算结果相同。
执行完成后,在input下存放输入数据和tiling数据,在output下面存放了输出数据和标杆数据,npuchk目录下是每个核的npu_check执行结果
在当前目录还有一个可执行二进制文件leakyrelu_custom_cpu,如果执行报错,可以通过gdb调试这个可执行文件,具体调试可参考文末官方教程。
在NPU侧执行
在NPU侧执行有两种方式:仿真执行和上板运行,命令都相同,只是编译选项不同,我们可以通过修改编译选项-DASCEND_RUN_MODE为SIMULATOR运行CAModel仿真,设置为 ONBOARD是上板运行。
function compile_and_execute() {
# 使用cmake编译cpu侧或者npu侧算子, SIMULATOR or ONBOARD
mkdir -p build; cd build; \
cmake .. \
-Dsmoke_testcase=$1 \
-DASCEND_PRODUCT_TYPE=$2 \
-DASCEND_CORE_TYPE=$3 \
-DASCEND_RUN_MODE="SIMULATOR" \
-DASCEND_INSTALL_PATH=$ASCEND_HOME_DIR
VERBOSE=1 cmake --build . --target ${1}_${4}
……
}
参考资料
总之,学习Ascend C,仅需了解C++编程、理解对列通信与内存申请释放机制、通过调用相应的计算接口与搬运接口,就可以写出运行在昇腾AI处理器上的高性能算子。
了解更多Ascend C学习资源,请访问官方教程:Ascend C编程指南(官方教程)