一、背景介绍
目前实时数仓提供的投放实时指标优先级别越来越重要,不再是单独的报表展示等功能,特别是提供给下游规则引擎的相关数据,直接对投放运营的广告投放产生直接影响,数据延迟或者异常均可能产生直接或者间接的资产损失。
 图片
图片
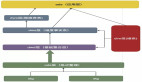
从投放管理平台的链路全景图来看,实时数仓是不可或缺的一环,可以快速处理海量数据,并迅速分析出有效信息,同时支持投放管理平台的手动控盘。实时节点事故,将可能导致整个投放链路无法正常运行,另外,投放规则引擎是自动化操作,服务需要24小时运行,所以需要配置及时有效的数据质量监控预警,能快速识别到波动异常或者不符合业务的数据,从而计划引入混沌工程,希望可以通过主动注入故障的方式、尽可能提前感知风险、发现潜在问题,并针对性地进行防范、加固,避免故障发生时所带来的严重后果,提高实时数仓整体抗风险能力。
二、演练范围
为了能更细致反应出混沌演练情况,根据演练的内容不同,将实时数仓混沌分为两部分:技术侧和业务侧。
技术侧混沌:基于中间件、数据库、JVM、基础资源、网络、服务等注入常见的异常,根据实际业务中梳理的应用核心场景进行混沌演练,检验系统的脆弱性和应急响应能力,从而提升团队的稳定性保障处理能力。
 图片
图片
业务侧混沌:对于电商活动密集型的公司来说,各种到达率、曝光率,以及更加宏观的 GMV、用户拉新数、用户召唤数等,都能表现出业务的健康程度,在实际生活中,为了描述一种稳定状态,我们需要一组指标构成一种模型,而不是单一指标。无论是否采用混沌工程,识别出这类指标的健康状态都是至关重要的,所以要围绕它们建立一整套完善的数据采集、监控、预警机制,当业务指标发生波动较大时,我们能搞快速感知、定位、修复止血。
 图片
图片
过往数仓混沌工程均是技术侧,此次在投放链路已搭建完成主备链路的前提下,期望通可以通过多轮业务侧混沌,提高系统整体的数据异动感知能力。
三、演练计划
工欲善其事,必先利其器,在执行混沌演练前,需要准备好前置工作,制定合理的演练SOP、方案、计划,对演练环境、脚本、数据、工具,场景及爆炸半径等进行可能性评估,在确认可行性ok的情况下,约好关联方时间,再进行实践操作。
 图片
图片
本篇主要和大家分享基于业务侧的实时数仓混沌演练过程:
1.编写演练SOP
SOP是一种标准的作业程序,就是将某一事件的操作步骤和要求,进行细化、量化及优化,形成一种标准的操作过程,关于业务侧混沌,尤其是实时数仓数据相关的演练,我们也是第一次做,目前在业界也没有找到相关的演练指导参考,处于探索阶段,为了方便项目进度的顺利进行及后续演练操作更加规范、高效,在演练前期大家经过沟通、讨论后,项目前期梳理的SOP演练模板,如下:
 图片
图片
2.演练方案调研
先收集实时数仓投放链路核心指标范围,在此基础上,拉取一段时间内的历史数据进行分析,找到每个指标对应的健康波动阀值,从而在配置相应的DQC规则监控,对于波动不在健康阀值的异常指标,在分钟级别(预期15min)内及时告警,并快速排查响应。为此,在演练前期,我们经历过一系列的方案调研、探索,如下:
「下文提供的方案,指标数据都是以设备激活数为例进行分析」
方案一: 按照天维度,收集最近一段时间,同一天每个整点设备激活数,占当天大盘占比,统计出最小值、最大值,作为该指标的健康波动阀值;
 图片
图片
- 方案二: 按照天维度,收集一段时间内,同一天相邻整点指标波动数据找规律,比如每天上午9点到10点的波动数据,然后分别通过一系列的数学分布方法进行数据统计,从而希望找一个相对稳定的波动区间;
 图片
图片
- 方案三: 按照天维度,收集一段时间内,相邻天整点指标波动数据找规律,比如昨天上午9点到前天上午9点的波动数据,然后分别通过一系列的数学分布方法进行数据统计,从而希望找一个相对稳定的波动区间;
 图片
图片
- 方案四:在前面三种方案的基础上,指标在工作日和周末的波动可能不一样,所以我们在日维度统计的基础上,我们也调研了周维度同比波动分布情况,比如每周一上午9点到上午10点的波动数据,然后分别通过一系列的数学分布方法进行数据统计,从而希望找一个相对稳定的波动区间;
 图片
图片
- 方案五:同理,我们也调研了周维度环比波动分布情况,比如本周一上午9点到上周一上午9点的波动数据,然后分别通过一系列的数学分布方法进行数据统计,从而希望找一个相对稳定的波动区间;
 图片
图片
- 方案六:基于主备链路,在source源相同的情况下,经过实时数仓计算出的指标,在同一段时间两条链路sink出来的结果数据,正常应该是保持一致,或者波动较小,比如10分钟延迟的主备链路,波动不超过10%,平均差异做到一致性做到90%以上。
方案1到5,都尝试过一遍,每个方案场景数据通过最大值、最小值、平均值、各百分位分布、方差、标准差等统计出来的数据分析,很难找到一个相当稳定的波动规律,也无法框定指标具体的阀值区间,实际演练过程,如果设置的波动告警阀值过大,真实生产上业务数据波动异常时,无法及时告警发现;设置过小,将导致告警频繁,对其准确性、有效性可能存在质疑,而且,实时投放的核心指标有几十个,每个指标对应的健康阀值都不一样,要收集、分析成本非常高,从演练的效果上看,也不是很明显。
整体评估下来,演练主要采用的是方案六:涉及到的实时投放核心指标数共收集29个,一段时间内(15min),主备链路指标波动差异不超过10%。
3.演练方式
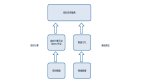
红蓝对抗演练,将团队分为红(防)蓝(攻)两组。
测试人员组成蓝军:负责制定混沌演练方案,执行目标系统故障注入,详细记录演练过程;
实时数仓开发为红军:负责发现故障、应急响应、排除故障,同时验证系统在不同故障场景下的容错能力、监控能力、人员响应能力、恢复能力等可靠性能力。
 图片
图片
四、演练流程
整体演练过程,大致分为三个阶段:准备阶段、攻防阶段及复盘阶段。
 图片
图片
1.准备阶段
- 方案准备完评审通过后,确认好链路计划;
- 蓝军按计划根据事先制定的攻击方案,提前准备好相应的测试数据、脚本;
- 红军按计划根据事先制定的攻击方案,在演练前,提前确保环境可用,并进行监控防御、应急响应措施。
2.攻防阶段
- 蓝队根据事先制定的攻击方案,模拟真实的攻击行为,按照约定的时间在演练链路(备用链路)进行攻击,进行故障注入,同时记录好相应的操作步骤,方便后续报告梳理;
- 红队在蓝军攻击后,通过飞书/邮件告警等通知方式实时关注监控系统运行情况,如有异常告警,需第一时间进行问题排查定位,在评估修复方案;
- 在攻防对抗的过程中,蓝军可根据红军的防御措施进行调整和改进攻击策略,尽力突破系统的防御并达到既定目标,同时红军也可分析蓝军的攻击手法和行为模型,不断改进防御措施来加强防御。
3.复盘和改进阶段
- 在混沌演练结束后,进行总结和评估,分析红队和蓝队的表现,评估系统的安全性和抗攻击能力;
- 总结经验教训,总结成功的防御措施和失败的攻击手法,以便于改进系统的安全策略;
- 根据评估结果和总结经验,制定改进计划,修补系统中的漏洞和薄弱点,提升系统的抗风险能力。
五、攻防实战
本次演练共计有29个指标波动case,整体演练操作大同小异。
 图片
图片
以其中case17 “召回商品收藏uv在某个渠道下整点波动异常”为例,具体的演练操作流程如下。
1.数据准备
- 通过后台数据库,拉出生产主(备)链路,某个渠道(如`media_id` = '2')下某个整点(如`hour` = 10)下,召回商品收藏uv对应的整体统计值N。
--渠道小时整点维度下,商品收藏uv汇总数据
select
`指标名称`,
`日期`,
'2' as `指标ID`,
`小时段`,
sum(`指标值`)
from table_a
where
date = date_format(now(), '%Y%m%d')
and `指标名称` in ( '商品收藏uv' )
and `小时段` = 10
AND `指标id` = '2'
GROUP BY
`指标名称`,
`日期`,
`小时段`
order by
指标名称;- 拉出备用链路,某个渠道(如`media_id` = '2')下某个整点(如`hour` = 10)下,具体的一条明细数据,记录商品收藏uv对应的值为n,把n改为n+0.1N,后续注入进备用链路,从而使得主备波动差异在10%。
-- 明细数据
select
t.指标名称,t.账户id,t.计划ID,t.设备类型,t.指标值
from
(
select
`账户id`,
`计划id`,
`指标名称`,
`指标值`,
`设备类型` ,
row_number() over (partition by 指标名称 order by 指标值 desc ) as rn
from table_a
where
date = date_format(now(), '%Y%m%d')
and `指标名称` in ('商品收藏uv')
and `设备类型` = '召回'
and `小时段` = 10
AND `指标id` = '2'
) t
where
t.rn = 1
ORDER BY 指标名称;整理后得到需要注入的数据数据,见标黄部分。 图片
图片
2.故障注入odps
- 将需要注入的数据导入odps。
导入前,需要在datawork空间中新建测试表du_qa_dw_dev.hundun_case,用于导入演练数据
-- drop table if EXISTS du_qa_dw_dev.hundun_case;
CREATE TABLE IF NOT EXISTS hundun_case
(
message STRING COMMENT '消息内容'
)
COMMENT '混沌演练'
;- 往du_qa_dw_dev.hundun_case表里灌数。
 图片
图片
 图片
图片
- 验证数据导入是否成功。
 图片
图片
3.odps同步到kafka
执行flink同步脚本,将odsp du_qa_dw_dev.hundun_case表表数据同步到对应的kafka topic中。
flink任务脚本:
--SQL
--********************************************************************--
--odps同步到kakfa脚本,用于实时数仓混沌演练异常注入使用
--********************************************************************--
-- 基本函数
CREATE FUNCTION JsonParseField AS 'com.alibaba.blink.udx.log.JsonParseField';
CREATE FUNCTION jsonStringUdf AS 'com.alibaba.blink.udx.udf.JsonStringUdfV2';
---同步账号表
CREATE TABLE `source` (
message VARCHAR
) WITH (
'connector' = 'du-odps',
'endPoint' = '***',
'project' = '***',
'tableName' = 'hundun_case_01',
'accessId' = '*******',
'accessKey' = '*******'
);
CREATE TABLE `kafka_sink` (
`messageKey` VARBINARY,
`message` VARBINARY,
PRIMARY KEY (`messageKey`) NOT ENFORCED
) WITH (
'connector' = 'du-kafka',
'topic' = '********',
'properties.bootstrap.servers' = '*******',
'properties.compression.type' = 'gzip',
'properties.batch.size' = '40960',
'properties.linger.ms' = '1000',
'key.format' = 'raw',
'value.format' = 'raw',
'value.fields-include' = 'EXCEPT_KEY'
);
INSERT INTO kafka_sink
SELECT
cast(MD5(message) as VARBINARY),
cast(message as VARBINARY)
FROM source
;4.kafka平台查询数据
执行完flink同步任务后,可通过后台查询,对应的数据是否同步成功。 图片
图片
5.异常注入通知
在异常注入完成后,可以通过飞书群通知,告知红军,如收到告警,需第一时间群告知。
蓝军:蓝军已完成数据准备,请红军在演练前确保环境OK且已完成规则配置,另外务必将演练时间计划及时同步通知到下游关联方;
蓝军:已完成注入。
6.告警触发通知
- 红军在演练前,可通过监控平台提前配置好防御规则。
 图片
图片
- 在异常注入后,如符合预期,在15min内发现指标波动异常,红军需及时同步到演练群中。
中危**双链路主备一致监控
服务名:**** 环境:****** 告警时间:****** 触发条件:**双链路比对波动异常,持续10分钟 告警详情:指标:prd_collect_uv主对比备下降:[-10%] 主:1066 备:956
业务域:实时数仓
应用负责人:***
- 如不符合预期,未在15min内发现指标波动异常,红军需及时定位、跟进问题,并在修复后,沟通后续演练验证修复结果。
红军:15min内未收到告警,定位中
红军:原因已找到,由于***造成,导致告警数据没有及时发出,正在修复处理
红军:已修复,请红军重新发起攻击
7.演练过程记录
收集、汇总记录演练过程中的每个操作,含时间点、执行人、操作等,如下:
 图片
图片
六、演练总结

七、未来展望
实时数仓业务侧的混沌演练,从0到1,在经过一系列的探索实践后,通过主备链路比对方式,演练期间对于异常波动的指标,可以快速识别感知,从演练结果上,取得了不错的成效,但也存在一定的局限性,如:
- 演练期间,通过人工注入的异常数据,如无法快速清除,可能影响到备用链路使用。
- 对于没有备链路的实时指标波动,需要制定更精细化的可行方案,找寻指标健康波动范围。
这些都需要团队进一步去探索、解决,同时在演练的过程中,我们将不断积累、丰富演练case、完善演练库,后续计划通过引入工具(平台)、建立演练协助机制、定期定时演练等手段,使混沌演练更加自动化、规范化、常态化,提高实时数仓整体数据稳定。