译者 | 李睿
审校 | 重楼
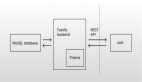
Prisma是一个流行的对象关系映射(ORM)工具,用于服务器端的JavaScript和TypeScript。其核心目的是简化和自动化数据在存储和应用程序代码之间的移动方式。Prisma支持广泛的数据存储,并为数据持久性提供了一个强大而灵活的抽象层。通过这个代码优先之旅,可以了解Prisma及其一些核心功能。

JavaScript的ORM层
对象关系映射(ORM)是由Java中的Hibernate框架首创的。对象-关系映射的最初目标是克服Java类和RDBMS表之间所谓的阻抗不匹配。从这个想法中产生了更广泛的应用程序通用持久层的概念。Prisma是Java ORM层的一个基于JavaScript的现代进化。
Prisma支持一系列SQL数据库,并已扩展到包括NoSQL数据存储MongoDB。无论数据存储的类型如何,它们的首要目标都是:为应用程序提供处理数据持久性的标准化框架。
域模型
以下将使用一个简单的域模型来查看数据模型中的几种关系:多对一、一对多和多对多 (在这里忽略一对一,因为与多对一非常相似) 。
Prisma使用模型定义(模式)作为应用程序和数据存储之间的枢纽。在构建应用程序时,将在这里采用的一种方法是从这个定义开始,然后从中构建代码。Prisma自动将模式应用于数据存储。
Prisma模型定义格式不难理解,可以使用图形工具Prismbuilder来创建一个模型。而模型将支持协作的想法开发应用程序,因此将有用户(User)、想法(Idea)和标签(Tag)模型。一个用户可以有多个想法(一对多),为一个想法提供一个用户,而所有者(Owner)则有多个想法(多对一)。想法和标签形成了多对多的关系。清单1显示了模型定义。
清单1.Prisma中的模型定义
datasource db {
provider = "sqlite"
url = "file:./dev.db"
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
name String
email String @unique
ideas Idea[]
}
model Idea {
id Int @id @default(autoincrement())
name String
description String
owner User @relation(fields: [ownerId], references: [id])
ownerId Int
tags Tag[]
}
model Tag {
id Int @id @default(autoincrement())
name String @unique
ideas Idea[]清单1包括一个数据源定义(一个简单的SQLite数据库,Prisma为了开发目的将其包含在内)和一个客户端定义,“生成器客户端”设置为Prisma-client-js。后者意味着Prisma将生成一个JavaScript客户端,应用程序可以使用它与定义创建的映射进行交互。
至于模型定义,需要注意每个模型都有一个id字段,并且正在使用Prisma @default(autoincrement())注释来获得一个自动递增的整数id。
为了创建从用户(User)到想法(Idea)的关系,采用数组括号引用Idea类型:Idea[]。这句话的意思是:给一些用户的想法。在关系的另一端,为想法(Idea)提供一个用户(User): owner User @relation(字段:[ownerId],引用:[id])。
除了关系和键ID字段之外,字段定义也很简单;字符串对应字符串,等等。
创建项目
在这里将使用一个简单的项目来使用Prisma的功能。第一步是创建一个新的Node.js项目并向其添加依赖项。之后,可以添加清单1中的定义,并使用它来处理Prisma内置SQLite数据库的数据持久性。
要启动应用程序,将创建一个新目录,初始化一个npm项目,并安装依赖项,如清单2所示。
清单2.创建应用程序
mkdir iw-prisma
cd iw-prisma
npm init -y
npm install express @prisma/client body-parser
mkdir prisma
touch prisma/schema.prisma现在,在prisma/schema上创建一个文件。并添加清单1中的定义。接下来,告诉Prisma为SQLite准备一个模式,如清单3所示。
清单3.设置数据库
npx prisma migrate dev --name init
npx prisma migrate deploy清单3告诉Prisma“迁移”数据库,这意味着将模式更改从Prisma定义应用到数据库本身。dev标志告诉Prisma使用开发概要文件,而--name为更改提供了一个任意名称。deploy标志告诉prisma应用更改。
使用数据
现在,允许在Express.js中使用RESTful端点创建用户。可以在清单4中看到服务器的代码,它位于inw -prisma/server.js文件中。清单4是普通的Express代码,但是由于有了Prisma,可以用最少的精力对数据库做很多工作。
清单4.Express代码
const express = require('express');
const bodyParser = require('body-parser');
const { PrismaClient } = require('@prisma/client');
const prisma = new PrismaClient();
const app = express();
app.use(bodyParser.json());
const port = 3000;
app.listen(port, () => {
console.log(`Server is listening on port ${port}`);
});
// Fetch all users
app.get('/users', async (req, res) => {
const users = await prisma.user.findMany();
res.json(users);
});
// Create a new user
app.post('/users', async (req, res) => {
const { name, email } = req.body;
const newUser = await prisma.user.create({ data: { name, email } });
res.status(201).json(newUser);
});目前,只有两个端点,/usersGET用于获取所有用户的列表,/userPOST用于添加它们。通过分别调用Prisma.user.findMany()和Prisma.uuser.create(),可以看到可以多么容易地使用Prisma客户端来处理这些用例。
不带任何参数的findMany()方法将返回数据库中的所有行。create()方法接受一个对象,该对象带有一个数据字段,其中包含新行的值(在本例中是名称和电子邮件—记住Prisma将自动创建一个唯一的ID)。
现在可以使用:node server.js运行服务器。
使用CURL进行测试
以下使用CURL测试端点,如清单5所示。
清单5.使用CURL尝试端点
$ curl http://localhost:3000/users
[]
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"George Harrison","email":"george.harrison@example.com"}' http://localhost:3000/users
{"id":2,"name":"John Doe","email":"john.doe@example.com"}{"id":3,"name":"John Lennon","email":"john.lennon@example.com"}{"id":4,"name":"George Harrison","email":"george.harrison@example.com"}
$ curl http://localhost:3000/users
[{"id":2,"name":"John Doe","email":"john.doe@example.com"},{"id":3,"name":"John Lennon","email":"john.lennon@example.com"},{"id":4,"name":"George Harrison","email":"george.harrison@example.com"}]清单5显示了获取所有用户并找到一个空集,然后添加用户,再获取填充的集。
接下来添加一个端点,它允许创建想法并将它们与用户关联起来,如清单6所示。
清单6. User ideas POST endpoint
app.post('/users/:userId/ideas', async (req, res) => {
const { userId } = req.params;
const { name, description } = req.body;
try {
const user = await prisma.user.findUnique({ where: { id: parseInt(userId) } });
if (!user) {
return res.status(404).json({ error: 'User not found' });
}
const idea = await prisma.idea.create({
data: {
name,
description,
owner: { connect: { id: user.id } },
},
});
res.json(idea);
} catch (error) {
console.error('Error adding idea:', error);
res.status(500).json({ error: 'An error occurred while adding the idea' });
}
});
app.get('/userideas/:id', async (req, res) => {
const { id } = req.params;
const user = await prisma.user.findUnique({
where: { id: parseInt(id) },
include: {
ideas: true,
},
});
if (!user) {
return res.status(404).json({ message: 'User not found' });
}
res.json(user);
});在清单6中有两个端点。第一个允许使用POST在/users/:userId/ideas添加一个想法。它需要做的第一件事是使用prism .user. findunique()通过ID恢复用户。这个方法用于根据传入的标准在数据库中查找单个实体。在本例中,希望用户具有来自请求的ID,因此使用:{where:{ID:prseInt(userId)}}。
一旦有了用户,就使用prisma.idea.create来创建一个新的想法。这就像创建用户时一样,但现在有了一个关系字段。Prisma可以创建新想法和用户之间的关联:owner:{connect:{id:user.id}}。
第二个端点是/userideas/:id的GET。这个端点的目的是获取用户ID并返回用户,包括他们的想法。可以看到与findUnique调用一起使用的where子句,以及include修饰符。这里使用修饰符来告诉Prisma包含相关的想法。如果没有这一点,就不会包含这些想法,因为Prisma默认使用延迟加载关联获取策略。
要测试新的端点,可以使用清单7中所示的CURL命令。
清单7.用于测试端点的CURL
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"New Idea", "description":"Idea description"}' http://localhost:3000/users/3/ideas
$ curl http://localhost:3000/userideas/3
{"id":3,"name":"John Lennon","email":"john.lennon@example.com","ideas":[{"id":1,"name":"New Idea","description":"Idea description","ownerId":3},{"id":2,"name":"New Idea","description":"Idea description","ownerId":3}]}能够添加想法并用它们恢复用户。
带标签的多对多
现在添加端点来处理多对多关系中的标签。在清单8中,处理标签的创建,并将标签(Tag)和想法(Ideas)关联起来。
清单8.添加和显示标签
// create a tag
app.post('/tags', async (req, res) => {
const { name } = req.body;
try {
const tag = await prisma.tag.create({
data: {
name,
},
});
res.json(tag);
} catch (error) {
console.error('Error adding tag:', error);
res.status(500).json({ error: 'An error occurred while adding the tag' });
}
});
// Associate a tag with an idea
app.post('/ideas/:ideaId/tags/:tagId', async (req, res) => {
const { ideaId, tagId } = req.params;
try {
const idea = await prisma.idea.findUnique({ where: { id: parseInt(ideaId) } });
if (!idea) {
return res.status(404).json({ error: 'Idea not found' });
}
const tag = await prisma.tag.findUnique({ where: { id: parseInt(tagId) } });
if (!tag) {
return res.status(404).json({ error: 'Tag not found' });
}
const updatedIdea = await prisma.idea.update({
where: { id: parseInt(ideaId) },
data: {
tags: {
connect: { id: tag.id },
},
},
});
res.json(updatedIdea);
} catch (error) {
console.error('Error associating tag with idea:', error);
res.status(500).json({ error: 'An error occurred while associating the tag with the idea' });
}
});在这里增加了两个端点。用于添加标签的POST端点与前面的示例很相似。在清单8中,还添加了POST端点,用于将想法与标签关联起来。
为了将一个想法(Idea)和一个标签(Tag)关联起来,利用了模型定义中的多对多映射。通过ID抓取想法和标签,并使用关联(Connect)字段将它们相互联系起来。现在,想法在它的标签集合中有标签ID,反之亦然。多对多关联允许最多两个一对多关系,每个实体指向另一个实体。在数据存储中,这需要创建一个“查找表”(或交叉引用表),但Prisma会处理这个问题,只需要与实体本身交互。
多对多特性的最后一步是允许通过标签找到想法,并在想法上找到标签。可以在清单9中看到模型的这一部分。(需要注意的是,为了简洁起见,删除了一些错误。)
清单9.通过想法找到标签,通过标签找到想法
// Display ideas with a given tag
app.get('/ideas/tag/:tagId', async (req, res) => {
const { tagId } = req.params;
try {
const tag = await prisma.tag.findUnique({
where: {
id: parseInt(tagId)
}
});
const ideas = await prisma.idea.findMany({
where: {
tags: {
some: {
id: tag.id
}
}
}
});
res.json(ideas);
} catch (error) {
console.error('Error retrieving ideas with tag:', error);
res.status(500).json({
error: 'An error occurred while retrieving the ideas with the tag'
});
}
});
// tags on an idea:
app.get('/ideatags/:ideaId', async (req, res) => {
const { ideaId } = req.params;
try {
const idea = await prisma.idea.findUnique({
where: {
id: parseInt(ideaId)
}
});
const tags = await prisma.tag.findMany({
where: {
ideas: {
some: {
id: idea.id
}
}
}
});
res.json(tags);
} catch (error) {
console.error('Error retrieving tags for idea:', error);
res.status(500).json({
error: 'An error occurred while retrieving the tags for the idea'
});
}
});这里有两个端点:/ideas/tag/:tagId和/ideatags/:ideaId。它们的工作原理非常相似,可以为给定的标签ID找到想法。从本质上来说,查询就像一对多关系中的查询一样,Prisma处理查找表的遍历。例如,为了找到一个想法的标签,可以使用tag.findMany 方法,其中有一个where子句查找具有相关ID的想法,如清单10所示。
清单10.测试标签概念的多对多关系
$ curl -X POST -H "Content-Type: application/json" -d '{"name":"Funny Stuff"}' http://localhost:3000/tags
$ curl -X POST http://localhost:3000/ideas/1/tags/2
{"idea":{"id":1,"name":"New Idea","description":"Idea description","ownerId":3},"tag":{"id":2,"name":"Funny Stuff"}}
$ curl localhost:3000/ideas/tag/2
[{"id":1,"name":"New Idea","description":"Idea description","ownerId":3}]
$ curl localhost:3000/ideatags/1
[{"id":1,"name":"New Tag"},{"id":2,"name":"Funny Stuff"}]结论
虽然在这里涉及一些CRUD和关系基础知识,但Prisma的能力远不止于此。它提供了级联操作(如级联删除)、获取策略(允许微调从数据库返回对象的方式)、事务、查询和筛选API等功能。Prisma还允许根据模型迁移数据库模式。此外,它通过在框架中抽象所有数据库客户机工作,使应用程序与数据库无关。
Prisma以定义和维护模型定义为代价,为用户提供了许多便利和功能。因此人们很容易理解这个用于JavaScript的ORM工具是开发人员一个热门选择的原因。
原文标题:Prisma.js:Code-first ORM in JavaScript,作者:Matthew Tyson