














在开始正文之前,首先来介绍一下九章云极DataCanvas。

九章云极DataCanvas主要致力于人工智能基础软件的研发,为企业的AI建设提供平台产品和配套的解决方案,帮助企业完成数智化转型。目前在政府、金融、通信、制造、能源、交通、航空等多个领域都有着非常多的成功案例。
一、AIGC用于结构化数据合成
依赖于大模型的参数量的增长,自去年11 月份ChatGPT发布以来,大语言模型涌现出了非常优秀的能力,包括对文本语义的理解、语义的搜索和语言组织的能力。并且开放给终端用户,为大众提供了更多AI发展的想象空间。

ChatGPT 在AIGC里面更多是以文本的内容生成为主,这两年我们实验室主要是在因果推断方面投入了大量的精力进行研究和落地。
因果推断主要指如何去科学地识别变量之间的因果关系,以及量化变量之间的因果影响。目前主流的研究方向一是潜在结果框架,二是结构因果模型。
AIGC目前主要是面向于非结构化内容生成,包括文本、图片、音频、视频等。如何将因果学习和AIGC连接起来是一个值得思考的问题。我们发现可以借助数据合成这一桥梁,让 AIGC 的能力拓展到结构化数据合成,从而实现因果推断和AIGC两个方向研究的相互助力。

Gartner 提出了合成数据的趋势报告,预计到2030 年,在 AI、机器学习领域,合成数据将会完全超越真实数据。图表中可以看到,未来合成数据将会呈指数级增长,成为一个大的发展方向。

对于企业来说,数据是智能化建设的生命线,企业获取高质量的数据往往存在比较大的挑战。比如部分业务场景受限于成本的约束,很多数据无法收集;在金融、医疗领域,出于隐私保护的要求,很多数据也是受限使用的;在计算机视觉中,正样本比较少,往往需要通过数据增强补充样本;新兴AI 用例产生时没有历史数据积累,这时如何进行场景的验证也是一大挑战。针对这些挑战,合成数据在企业的AI 能力建设当中,会发挥非常大的补充作用和优势。

合成数据主要有两类方法,一类是以数据驱动为主,包括对抗生成网络、VAE方法、贝叶斯网络、ML-base等;另外一类是以过程驱动,包括Agent-based modeling、离散事件模拟、数值模拟和蒙特卡罗方法等。其中Agent-based modeling非常适合作为桥梁,帮助我们完成AIGC向结构化数据的转化。

ABM是一种用来模拟具有自主意识的智能体的行动和相互作用的计算模型,评估智能体在系统当中的作用。它的任务主要有两种,一种是分析宏观发生的现象的原因;一种是推演,基于微观干预的手段预期表现的基础上,推演未来宏观方面的表现。ABM有不少别名,比如 IBM、MAS都属于ABM 的范式,只是在不同时间点和领域的不同名称。

ABM建模范式首先是对系统组件、操作、交互和环境的抽象,形成仿真系统,其中agent 智能体是核心组成单元。比如在金融行业agent仿真系统,对公对私客户都可以作为agent 的单元。第二个抽象是大环境,可以想象在金融环境的整体下,总的市场规模客户、人均收入水平,都可以视为环境内部实际要素。另外一个关键点是在个体之间有相应的连接和交互,譬如有个体和个体之间的交互,也有个体和环境之间的交互,也是 ABM 研究的关键步骤之一。

ABM很多优秀特性,这里只列出了最重要的三点。
首先是强大的仿真性,不管是社会、生态还是组织都是非常复杂的,ABM可以承载复杂的表达,曾有学者提出ABM可以仿真一座完整城市,它为整个数据基础和研究提供了非常好的可靠性空间。
第二ABM具有涌现属性,其主要目的是解释涌现现象的原因,比如抢购效应会加剧客户购买意愿,这就属于ABM的研究范式和目标场景。
第三个重要的特性就是解释性。在机器学习、因果学习中,很多专家都非常关注解释性,ABM 研究范式是从业务经验假设基础出发,所以解释性非常强。
综上来看,ABM适合作为AI 载体,实现 AIGC 对结构化数据生成的拓展。接下来将介绍我们已经做的一些尝试和探索。
二、结构化数据合成助力因果推断

回顾因果推断的常见任务,主要包括因果发现、因果量的识别、因果效应估计、反事实推断以及策略学习等方面。在企业宏观经济分析当中,有很多实际案例,比如电商领域异质化产品推荐,就是因果效应估计的一种常见场景。工业界落地比较有代表性的算法包括 Meta Learner 、DML ,以及 Causal Forest 等算法。另外一个比较大的研究方向是因果发现,主要思想是寻找发生结果的原因,目前该方向更偏向于因果定性的研究范式。合成数据可以应用在上面提到的所有任务当中,并且有更广泛的应用方向,后面将着重介绍几个在因果发现和因果效应估计方面增强验证上的示例。

在因果推断任务里比较大的一项挑战是反事实问题。干预策略实施后,我们仅能观测到实施状态下的结果,未干预状态下的潜在结果是无法观测的,无法观测到的潜在结果,通常称为反事实结果。比如商店给客户发优惠券的场景,假如给一位用户发了优惠券,我们只能知道他收到优惠券之后的反应,没有办法再去知道他没有收到优惠券的反应,这就是反事实不可观测问题,该问题为因果效应的度量带来了一定的影响。应对该问题,目前主要手段是随机实验AB-test;另外,在观测样本上,受限于没法看到反事实的真实值,因此对于因果效应的估计目标,潜在结果和现在真实结果之间的差值是没有办法获得的,导致我们通常用的MSE 指标没有办法应用在这种任务上,因此会采用AUUC指标去替代因果效应度量,但会有一定的局限性。
这里可以思考两个问题,第一个问题,是否可以获取反事实样本,第二个问题,如果可以获取反事实样本,我们可以做些什么。ABM 多智能体系统建模中,它的运行模式就是在不同参数组合下去进行仿真运行,运行过程当中就可以输出数据。比如外呼团队 ABM 系统,它可以输出类似于外呼记录、成交记录、TSR 属性、客户属性等等各种业务上的记录表,这些数据可以存储下来形成数据集,甚至可以按照数仓模式去构建完整的数据体系。另外,ABM在不同参数组合下运行时,本身是一种反事实运行模式,因此可以将反事实运行模式结果保存下来。

从图中可以看到,通过系统以及产出数据,首先,可以获取反事实数据;其次,可以从系统里面拿到完整的预置因果关系;再次,可以获取全部因子特征;最后,还可以获得时序类反事实数据,比如模拟业务运行一两年后的因果效应影响。
综上所述,ABM具有很多优质特性,最重要的三点就是反事实可获取、仿真性和特征完整性。同时它的可控制性也比较强,可以有一些宏观干预和微观干预,比如为所有用户提供折扣,或者为某些客户提供折扣。也可以支持在这个环境下去模拟A/B test的运行。因此,ABM可以提供非常优质的数据基础,为因果推断研究起到助力作用。

上图是我们目前在做的相关研究。这是一个 ABM 范式的金融系统,左图是系统整体的抽象,右图是运行状态。左边系统内将银行、储户、企业抽象成为智能体代理。环境主要包括银行数量、人口数量、企业数量以及监管管控策略。宏观监管参数包括最低准备金率、无风险收益率、杠杆率来限制银行经营指标。交互行为主要是储户和银行之间的存款与取款行为,以及企业和银行之间的贷款行为。
右图是系统的运行态,首先它可以在不同宏观参数情况下去运行和仿真模拟,ABM的一种研究范式是做涌现分析,比如最下边是我们验证的一组参数,在资本充足率要求比较低的情况下,很容易会涌现系统性金融风险,比如银行挤兑。当然,这属于负向的涌现分析,实际业务中更常见的是正向的涌现分析。
另外一种研究模式是校准,如何去通过找出相应因子或因子范围,能还原更真实的业务场景。并在这种参数情况下去进行干预和推演,形成本身的研究范式。可以看到,所有数据都可以存下来,可实现上面提到的反事实数据获取、特征完整性等特性。
下面来介绍一些数据合成与因果学习结合的应用场景。

第一个场景是因果发现方向。上图中左边部分是从系统里面获取预置因果关系,右边是结合了三种因果发现算法。我们能够直观感觉到这两者有一定差异。因此当前因果发现算法,还有一定提升空间。从数据中,我们观测到几点,首先,在业务上有些事情不会发生,它会一直处于一个状态即常量值,对于常量值目前没办法去学习其间的因果关系;其次,算法识别的因果关系,会出现一些因果关系的缺失或因果反向或错误因果关系等情况,如果采用单一算法去做因果发现的话,有一定局限性,因此建议采用多种因果发现算法相融合,才能最大限度地学到真实的因果关系。
应用多智能体建模数据合成的优势在于,首先成本可控,可以获取预置因果关系,同时也可以获取完整特征,不存在不可观测的特征。在应用领域上可以验证各种算法精度,可以论证算法融合的最佳模式,并在未来应用在真实场景上。综上,合成数据可以为因果发现提供非常好的研究数据基础。

第二个方向是因果效应估计方向研究。在没有反事实情况下,我们往往用一些替代方法去评价因果效应精度,比如A/B test。但实际业务,并不允许所有场景企业都会去做 A/B test,一方面原因是A/B test有一定的现实成本问题,某些场景甚至是伦理问题;另一方面,A/B test仅能评估群体效应,无法评估个体效应,具有较强的局限性。
通过ABM可以获取反事实样本,基于反事实样本的评价指标具有以下优势:
可以采用 MSE等常见指标来论证算法有效性。
可以突破性地去验证个体治疗效果。
可以论证 A/B test、AUUC、Qini等方法的有效性。
同时,在环境中也具有比较高的可控性,甚至可以去仿真模拟一些有偏无偏的数据场景。
我们在带有反事实的公开数据集上去做了一些验证,主要是评估AUUC 、Qini以及 RLoss三个指标的有效性。发现在连续型 outcome 场景下, RLoss指标有更高的稳定性。多智能体系统产生的反事实数据可以指导因果推断的研究,也可以助力场景落地。

在算法应用和研发当中,获取到这些智能体合成数据后,该如何去应用呢?以因果效应估计场景为例。图中第一行,是常见模式(没有考虑拆验证集),在训练阶段用 train data 做训练,在评估阶段用test data去做评估验证。没有反事实样本情况下,对于因果效应估计的评估方法只能才用AUUC、Qini、RLoss 等指标;第二行,是一个有反事实样本的例子,首先在评估阶段,可以加入反事实样本,评价指标可以扩展到MSE、RMSE等常用评价指标;第三行,甚至可以在训练阶段加入反事实样本,这对整个因果方法研发,提供了几乎完美的数据基础。ABM提供的数据资产,不仅在因果推断领域,在其他领域研究也同样具有适用性,包括深度学习、机器学习,还有譬如因果里面的IV方法。
三、如何利用因果推断帮助Agent-Based Modeling

利用因果推断去帮助 Agent-based modeling多智能体建模有着比较广泛的应用领域,这里列出了其中几个常见的场景。比如内部数据使用有限制,历史数据缺乏等情况,可以进行数据补充和增强;可以进行宏观涌现的原因分析,以银行或者保险外呼团队场景为例,希望分析譬如团队规模、小组人数、员工流失情况,对于整个业务部门指标的影响,进而形成对应薄弱环节的改进建议。这些都是 ABM 研究范式在业务场景落地的模式。

在任务目标上,分析任务和推演任务是ABM两大主要方向。从层次上来说,它既能涵盖微观,也能涵盖宏观。比如,外呼团队场景,微观层面包含了客户、外呼员,以及他们之间的交互行为(之间的通话)。宏观层面拆分,有多个 agent 组成小组存在,宏观层面也有相应的参数和指标,更注重解释涌现发生的原因。ABM既支持宏观分析,也支持微观分析。从宏观视角来看,进行一些干预,比如按照小组模式去整体采取不同名单分派策略,看一下外呼团队整体业绩效益;从微观视角来看,比如做一些差异化激励政策,推演团队整体业绩效益。
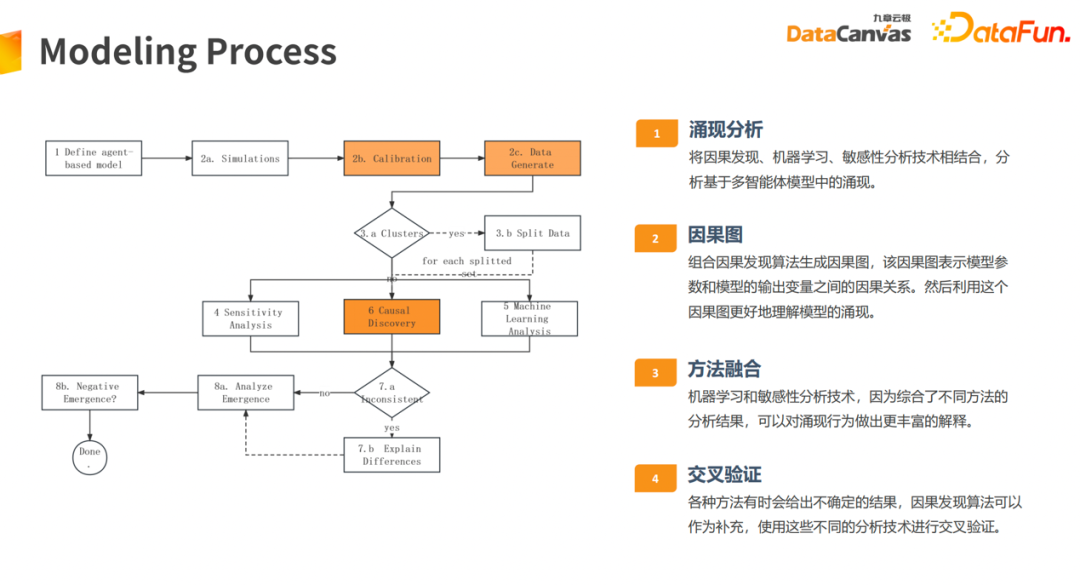
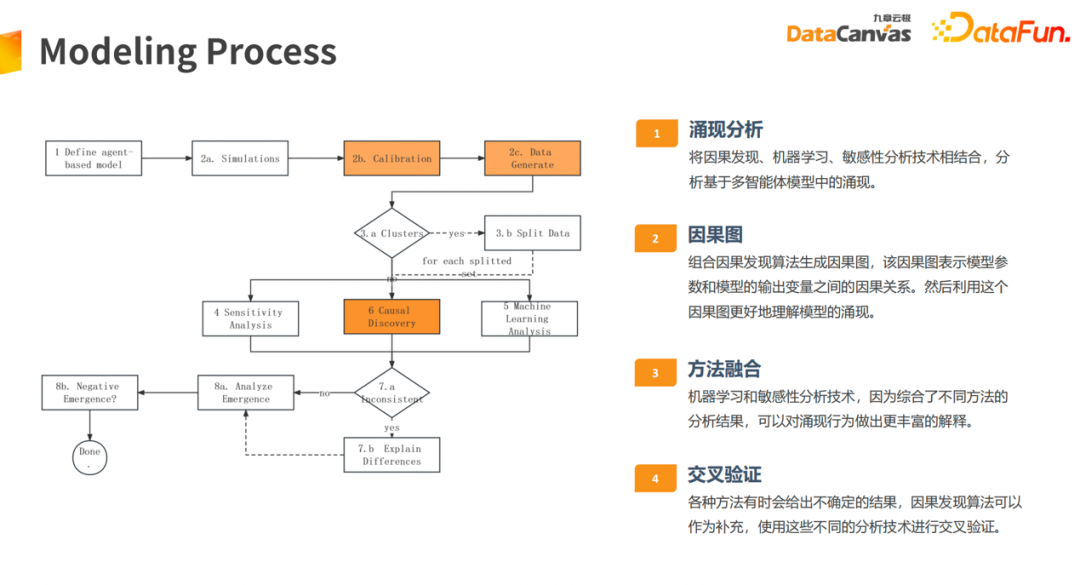
应用因果发现方法,助力ABM涌现分析任务。上图展示了ABM 建模流程,包含模型定义、仿真运行、校准和数据生成,以及相应参数分析和涌现分析。首先可以将因果图方法应用到参数分析上,并且可以融合敏感性分析、机器学习方法等,对参数和关注指标原因进行量化,以及相应解释。辅助用户进行更好的做校准,以及涌现分析相应解释。

应用因果效应估计,助力并加速ABM任务校准过程。校准过程在 ABM 整个运行参数空间也是非常庞大的。譬如100 个不同参数,它们当中有大量连续性参数,空间是非常恐怖的,而且每一次运行过程都非常耗时,寻求最优组合空间也是一个相当耗时的过程。如果应用因果效应估计,首先可以在已经运行过的参数空间空间之上,去训练因果效应估计模型,基于此基础之上,进行类似于进化方法,在里面去相应地调整一些变量,让目标指标更接近于校准参数指标。另外可以通过反事实方法,抽样一批新参数出来,基于模型基础上,对新抽样参数组合空间里面去做反事实推断,判断哪些参数组合更有效,之后再去做运行和校准过程。
目前我们团队更关注的是AIGC对结构化数据的生成和对因果推断的助力,当然因果推断其实也可以反过来助力 AIGC对结构化数据的生成。
四、YLearn介绍
最后分享一下YLearn因果学习软件。

YLearn倒过来是learn why,这正是它的初衷和含义。框架核心目标是提供简单易用的一站式因果推断框架。YLearn的模块覆盖了基本全部因果推断主流任务类型,包括因果发现、因果图、因果效应估计、策略学习、Interpreter以及反事实预测。其中因果效应估计包含了现在常见的主流算法,比如Meta Learner、Causal Tree, Causal Forest等等。同时也做了整体封装的统一接口,可以一站式地完成大部分因果建模任务。

这是一个因果效应估计的例子。对于给定的数据集,定义treatment 是哪个变量, outcome 是哪个变量,调用对应的 feed 方法,进行模型训练,就可以做因果效应评估。

第二个是因果图方向,比如左边代码,用户只需要加载数据集,通过 Causal Discovery 接口就可以进行因果发现。框架支持线性、非线性的多种因果发现算法。右边部分,提供了因果图的功能,包括因果图的定义、可视化,以及因果量识别方法。
下方案例主要是通过后门调整去识别 treatment x,以及outcome y的因果效应,结果可以输出后门变量。

最后介绍一下统一接口why。这个接口是对 YLearn 内部组件的统一封装,覆盖了因果推断相关的所有任务,仅需要通过一个why的实例,就可以去实现因果发现、因果效应估计、whatif反事实推断,interpreter因果解释等因果推断任务。
YLearn的核心目标就是帮助建模人员在一个工具内完成因果推断的全部任务,避免使用多个框架的切换。






























