一、背景和挑战
1、背景
首先来简单介绍一下货拉拉。

货拉拉于2013年成立于粤港澳大湾区,是一家从事同城跨城货运、企业版物流、搬家、零担及汽车销售的互联网物流商城。截至2022年12月,货拉拉业务范围已覆盖360座国内城市,月活司机达68万,月活用户数达950万,并处于一个快速增长的阶段。
接下来对货拉拉当前的大数据体系做一个简要介绍。

自下而上来看,首先是基础层和数据接入层,主要提供的是数据计算、存储以及集群管理。往上是数据研发和数据仓库,主要提供数据研发能力。接着是具备业务属性的应用层和服务层。整个体系,自下而上相互支撑,最终实现支撑业务和赋能业务。

上图展示了整个数据流的典型场景,分为数据采集、数据存储和计算,以及数据服务几个阶段。
数据采集分为实时采集和离线采集。实时采集的数据主要来源于用户埋点数据,从用户端采集之后,流入实时链路进行计算。离线采集主要来源于业务订单数据,按照小时和天采集到大数据存储桶以供使用。
数据存储和计算阶段,将数据进行ETL处理,再推送到上层应用进行分析。
2、Doris业务介绍
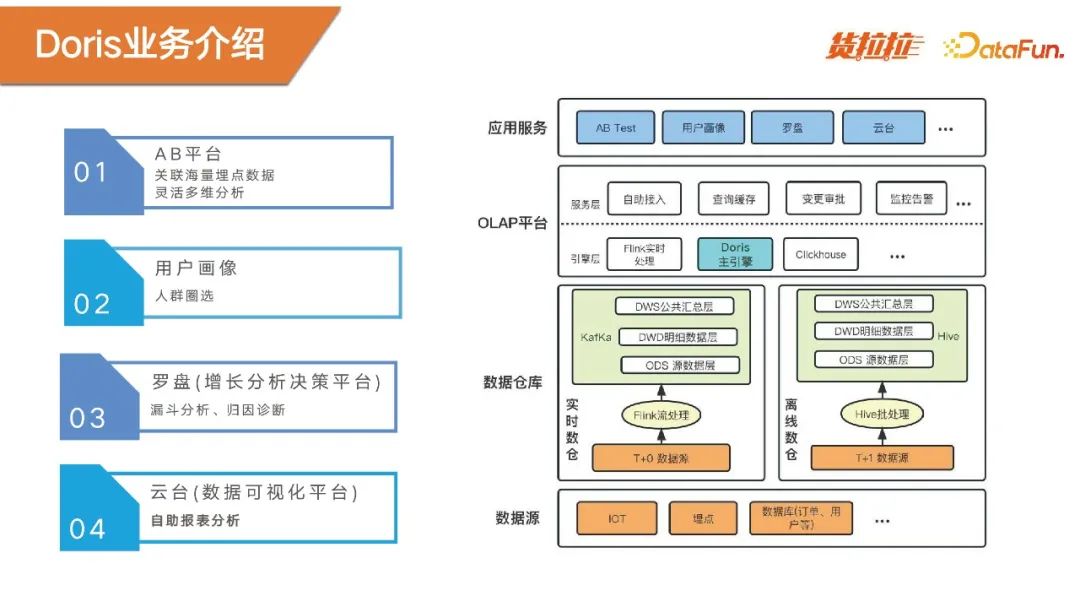
我们从2022年初开始使用Doris,在这一年半的时间里,Doris还是相对稳定的,同时提供了高性能的查询。上图右侧是Doris的整体架构图。Doris的数据源来自IOT、埋点和数据库,通过实时数仓和离线数仓两个方式写入。以Doris作为主引擎构建了大数据OLAP平台,服务于上层应用。
目前赋能的业务包括,ABtest,主要是关联海量埋点数据,进行灵活的多维度分析;用户画像,主要是做人群圈选;罗盘,是增长分析决策平台,提供漏斗分析和归因诊断的功能;云台,是数据可视化平台,提供自助报表分析的能力。
3、稳定性挑战
稳定性方面,当前面临着两大挑战。
首先,业务对Doris服务稳定性要求高。Doris已经接入公司多个核心业务,已经成为大数据的核心基础组件,因此对稳定性的要求是非常高的。
另外,开源软件基本能力和生产需求的差距大。Doris内核能力较为完善,但外围平台能力不足,例如监控告警、运维管控。Doris内核演进速度快,相应的Issue也较多,稳定性问题可能会接踵而来。
Doris稳定性保障的目标为:
- 少出事,核心链路数据,全年准确率达到99.45%以上;
- 快发现,核心链路问题主动发现的时间小于5分钟;
- 快恢复,P0核心链路恢复时间小于5分钟,P1级(埋点相关指标,容忍度较高)链路恢复时间小于10分钟。
二、稳定性能力保障
接下来将通过我们遇到的一些稳定性相关案例,来梳理一下Doris的稳定性保障能力。
1、案例

稳定性案例分为查询、导数、数据质量、版本升级、以及业务变更这五类问题。
案例一:查询性能问题

场景是云台查询Doris间歇性报错。我们定位的原因是用户提交了大量的查询,以及一些大查询,导致fragment的rpc处理线程池满。目前的处理办法是加大缓存容量,增加缓存命中率。另外,将查询时间下调,同时增加大查询的拦截能力。
案例二:导数性能问题

在一个准实时场景下,5分钟调度任务因多个任务执行超时,导致报表数据更新延迟并跌0。原因是业务方提交了其他任务存在严重乱序,导致集群的整体写入吞吐变得很慢,影响了准实时场景。我们的解决方法是,将Doris任务及导入参数进行了优化。同时,加强了Doris变更规范管控与审批流程,并正在实现业务多租户的隔离。
案例三:数据质量问题

业务使用Sparkload导入Unique模型表,查询结果不稳定,导入的数据和查询的结果不一样。原因为Unique模型表使用Sparkload导数时存在异常。目前是采取规避的方法去解决,首先是将Unique模型改为Duplicate模型重建表,并进行任务的重写;另外,将Unique模型使用注意事项加入准入规范及最佳实践进行宣讲。
案例四:版本升级问题

从1.1升级到1.2,在任务高峰期内存出现OOM被kill,导致任务报错。原因是升级后的bitmap向量化没有进行谓词下推,也就是过滤条件没有提前执行,导致内存上涨。目前的解决办法是业务对SQL谓词下推进行了优化,如and和or的条件合并。后续会考虑集群HA方案。
案例五:业务变更问题

业务侧自行对Doris表新增字段,导致分区无法查询。原因定位为触发了Doris版本1.0的bug,导致部分segment损害,无法修复。针对这一问题,我们沉淀了一个通过Sparkload快速恢复数据的应急预案。并对用户宣导,遵守使用规范、任务上线规范和发布变更规范,避免类似问题的再次发生。
2、稳定性建设思路

针对上述案例,我们从少出事、快发现、快恢复三个维度,总结了一些稳定性相关的能力。例如发现能力、容量规划、自动化能力等等。接下来将对其中部分能力进行具体的介绍。
3、发现能力

当前Doris监控告警系统以Zabbix作为底座,对Doris服务进行监控和告警。

发现能力主要包含三个维度:
- 表级监控,主要是监控表容量和状态;
- 任务监控,针对导数任务状态进行监控;
- 组件监控,针对服务指标(如查询、导数)、进程和机器指标进行监控。
我们对指标也进行了分级,一级指标表示服务不可用,用于发现和定位问题;二级指标和三级指标用于日常定位问题和分析问题。

上图是指标监控的画面。
4、容量规划

(1)容量梳理

容量梳理包含业务需求、数据量、硬件资源和集群规模几大部分。
通过业务需求,确定当前的场景是实时还是离线,数据写入速度,分区情况,以及查询、存储的要求等等。同时根据当前的业务需求需要的数据量,拟定当前的硬件资源,以及集群规模。生产环境集群资源配置,FE(云盘)和BE(本地) CPU和内存比是1:4的机型这种机型使用。这种在当前环境有较高的资源利用率。在需要较高的吞吐情况下,使用本地IO高吞吐的磁盘。
(2)容量监控

通过对机器级别的一些指标,例如磁盘容量、CPU、内存,以及服务指标,例如任务队列,分为一级指标和二级指标,设定一些阈值,评估当前集群是否处于一个健康水位,从而判断集群是否需要扩容。
5、高可用能力

(1)服务高可用
服务高可用,主要依赖Doris自身的能力,FE用三台部署高可用架构。BE数据用三台副本,四台及以上的节点,避免一台宕机导致服务数据不可写。另外,引入负载均衡绑定后端,实现连接数的均衡,以及读写高可用。
(2)链路高可用
分为离线/准实时链路和实时导数链路。离线/准实时链路,支持异常重试和电话告警,数据支持幂等操作。实时导数链路,和离线一样,通过自研的调度平台进行调度。
6、自动化能力

通过大数据自动化运维平台构建了大数据自动化能力,底座基于Conductor和Ansible进行开发。目前已集成了Doris部署、扩容、升级等工作流编排能力。提高了Doris组件服务运维的稳定性,提升了运维人效。
7、其他保障能力
查询拦截能力:设置用户级别拦截规则,根据实际数据量级、查询规模设置拦截规则。制定了快速对异常query进行kill的能力,防止对集群整体产生更大的影响。
故障快恢复能力:包括分区数据的快速恢复能力,以及tablet状态恢复能力。
业务隔离:根据业务重要程度、数据类型属于实时还是离线,进行集群隔离、多租户。
用户权限管控:通过使用Doris自带的RBAC(Role-Based Access Control)能力,对用户/角色赋予相关权限。
三、稳定性流程规范
稳定性流程规范最重要的作用是提升系统能力下限,在稳定性保障中是非常重要的一环。我们围绕着Doris流程的三个阶段制定了相应的规范:
- Doris业务准入规范:快速评估业务需求,判断Doris是否适合该业务场景。
- Doris使用规范:提供Doris的最佳使用实践,规避已知风险,避免重复犯错。
- Doris业务变更规范:进行发布流程管控,减少因发布造成的故障和影响。
接下来将具体展开介绍这三个规范。
1、Doris业务准入规范

当我们接收到一个新的需求时,首先要进行需求评估,判断是否适合Doris。我们会按照业务稳定性要求、导数、存储等多个维度进行综合考量。导数部分,通过Flink和streamload的方式将数据写入Doris,为了提升性能,会将数据累计到150M做批次导入,写入延迟通常在秒级。对写入延迟比较高的场景,要求在毫秒级的,不太适用。目前的版本是存算一体的架构,存储成本相对较高,对于大容量的业务,出于成本的考虑也并不适用。数据量比较小的场景,推荐直接使用MySQL。查询QPS方面,对于端上的查询QPS要求几千或者上万,不推荐使用Doris。对于风控的业务,对查询的响应要求非常高,也不适合Doris,会推荐使用HBase。
后续参加需求准入的评审,主要评估业务的价值,综合评价投入产出比。
2、Doris使用规范

在业务接入Doris之前,我们会提供一个测试集群,并提供Doris使用规范,和一些反例。从建表、增删改查等多个方面引导用户更好地使用Doris。
使用不规范案例,例如在建表环节,分桶设置很小,随着业务的不断积累,单个table达到30G,后续执行compaction就会很慢,尤其是base compaction会非常慢。会影响到集群的吞吐和稳定性。在数据写入方面,用Flink实时写入,强制要求使用平台提供的API。曾经有业务使用自己的jar包,没有控制并发写入的量,使集群吞吐变慢。严格保证用户的写入没有乱序。用户通过insert into的方式写入,Doris的insert into 语句是异步的,还需要异步地等待版本发布之后数据才可见。删除阶段,在业务的高峰期不推荐频繁使用删除操作,这样会导致集群的base compaction操作很频繁,导致集群吞吐变慢。对于查询,严禁不带任何参数的全表查询,容易打爆CPU和内存。同时也对大查询根据规则进行拦截。
在明确了使用规范,并对业务部分进行宣讲后,大大提升了Doris的稳定性。
3、Doris业务变更规范

Doris变更规范,主要涉及的操作包括:Doris集群本身的变更,比如集群配置的修改、集群重启、集群版本升级等;还有一些业务侧的变更,比如新建表、新添加导出链路、表和字段的修改等等。
变更规范主要包括四大部分:
首先是业务变更的时间窗口,通常会选择在业务低峰期进行变更。当然紧急的变更需求也可以走紧急变更流程。
第二是发布内容和发布通知,对发布背景和执行操作要进行清楚地描述,同时要充分地通知到业务方和执行方,保证次日Oncall。
第三是由方向负责人和组负责人进行审核,遵循Doris使用规范。
最后,验收阶段,分为服务功能性验收和服务稳定性验收,针对异常能够做到快速回滚。
四、总结与规划
1、总结

首先要明确稳定性目标,并将目标量化,确定一些指标项。对于日常的案例,包括稳定性冒烟、稳定性故障,要做到对每次冒烟和故障都有记录,并且定期总结和复盘,找到与稳定性目标之间的差距,用于持续构建保障性能力。制定流程规范,并严格遵守规范,不断向稳定性目标靠近。
稳定性的建设是持续的、成体系的,而非靠运气。稳定性目标的实现需要业务方的支持,而非单点的突破,比如流程规范、HA能力等等都需要业务方的支持和遵守。
2、规划

在稳定性方面,我们正在探索多集群HA,这样一个集群出现问题时可以快速回滚到备用集群。对于大的集群,做多租户隔离,防止业务之间相互影响。出于成本,还会考虑冷热存储。
易用方面,继续提升OLAP平台化的能力。
高效方面,紧跟Doris社区,尝试更多的应用场景,比如2.0版本提供的高并发点差的能力,以及文本搜索代替ES和联邦查询的能力。