不知道大家是否还记得年初火爆全网的反黑大剧《狂飙》中,最后几集因为导演删改剧情,演员嘴型和台词完全对不上的事吗?
后边有懂唇语的硬核剧迷,为了看到原版剧情,直接开始翻译。

来源:娱乐寡姐
Meta最近开源了一个AI语音-视频识别系统:MuAViC,让大家动一动手指头,就能看懂没有声音的人物讲了啥,还能精确识别嘈杂背景当中特定人物的语音。
Meta利用TED/TEDx的视频语音素材,制作了MuAViC中的数据集。其中包含了1200小时,9种语言的文本语音视频素材,还有英语与6种语言之间的双向翻译。
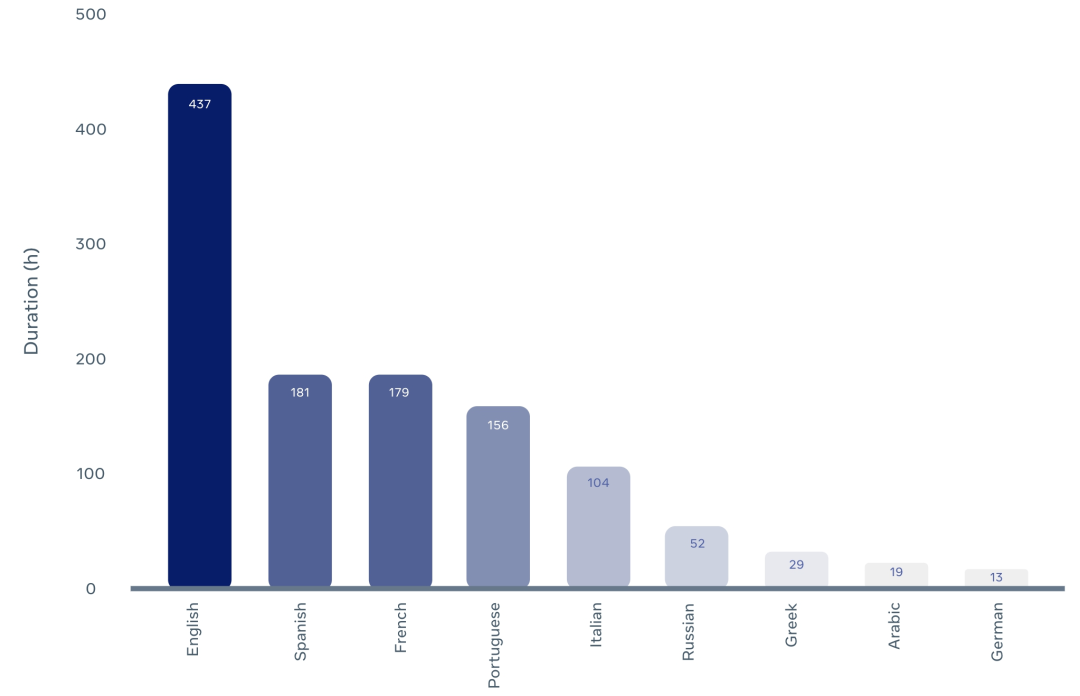
语音识别数据的详细内容:
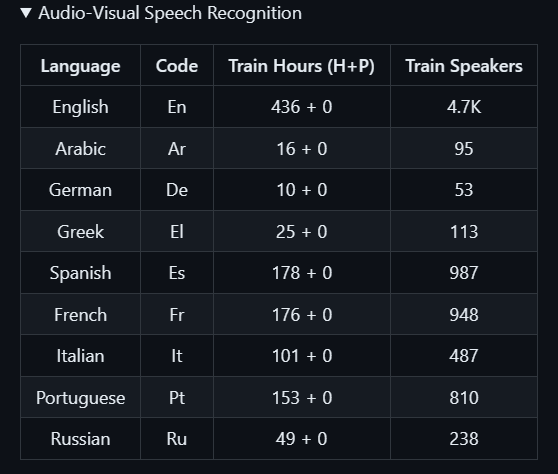
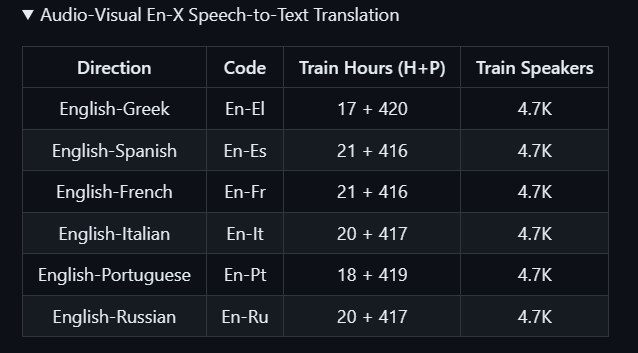
英语到6种语言翻译的素材具体包括:
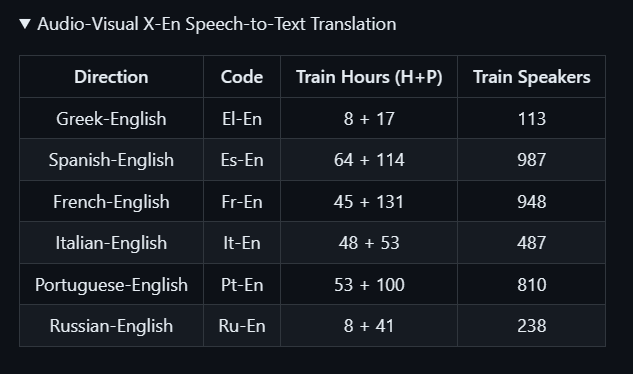
6种语言到英语的翻译素材具体包括:
论文
针对这个系统,Mate的研究人员也发布了论文介绍它与现有SOTA的对比。

https://arxiv.org/pdf/2303.00628.pdf
视听语料库的收集
英语语料收集
对于英语语料,研究人员重新使用了LRS3-TED中的视听数据,并按照原始数据进行了拆分。
通过匹配LRS3-TED中的转录和TED2020中的源句,研究人员从机器翻译语料库TED2020中找到了这些会谈的人工翻译。
然后将匹配的LRS3-TED示例与TED2020中相应的目标句子配对,以获得翻译标签。
研究人员对开发集和测试集示例采用精确文本匹配,以确保最佳准确性。
为了提高训练集的匹配召回率,研究人员开发了一种模糊文本匹配策略:如果句对双方包含相同数量的句段,他们首先用标点符号分割TED2020源句和目标句。
然后,通过去除标点符号和小写来规范TED2020和LRS3-TED文本。
最后,在两个语料库之间进行精确文本匹配。
对于TED2020中没有匹配的LRS3-TED训练集示例,研究人员从机器翻译模型M2M-100 418M中获取伪翻译标签,该模型采用默认的解码超参数法。
非英语语料的收集
对于非英语语料,研究人员重新使用了之前研究中的mTEDx收集的纯音频数据、转录和文本翻译。他们也按照mTEDx来进行数据拆分。
他们获取原始录音的视频轨迹,并将处理过的视频数据与音频数据对齐,形成视听数据,与LRS3-TED类似。
虽然mTEDx中的所有音频数据都已转录,但其中只有一个子集进行了翻译。
研究人员从M2M-100 418M中获取伪翻译标签,用于使用默认解码超参数的未翻译训练集示例。
实验
实验设置
对于视听语音识别(AVSR)和视听语音翻译(AVST),研究人员使用英语AV-HuBERT大型预训练模型,该模型结合LRS3-TED和 VoxCeleb2的英语部分进行训练。
研究人员按照AV-HuBERT论文中的方式来微调超参数,不同之处在于他们将双语模型微调为30K更新,将多语言 AVSR 模型微调为90K更新。研究人员分别冻结X-En AVST和En-X AVST模型的第一个4K和24K更新的预训练编码器。
AVSR测试
安静环境中
研究人员在纯音频("A")和视听("AV")模式下对 AVSR 模型进行了评估,前者在微调和推理中仅利用音频模式,而后者则同时利用音频和视觉模式。
如下表1所示,英语 AVSR 模型的测试误码率分别为 2.5 和 2.3。
对于非英语 AVSR,研究人员对预先训练好的英语AVHuBERT模型进行了微调,微调方式可以是对每种语言分别进行微调(8 种单语模型),也可以是对所有8种非英语语言联合进行微调(多语模型)。
其测试误码率见下表2。
研究人员发现,在视听模式下,研究人员的单语AVSR模型的WER平均降低了52%,优于同类ASR基线(Transformer,单语)。
 表1
表1
 表2
表2
 表3
表3
噪音环境中
表3的第一部分显示了研究人员的 AVSR 模型在高噪音环境下的测试误码率。
研究人员注意到,SOTA多语种ASR模型Whisper在这一具有挑战性的设置中表现糟糕,种语言的平均误码率为174.3。
相比之下,研究人员的单语言AVSR模型在纯音频模式下的平均误码率分别为70.2和66.7。
在视听模式下,研究人员模型的平均误码率大幅下降了32%,这表明它们有效地利用了视觉信息来减轻嘈杂环境的干扰。
在纯音频和视听模式下,研究人员的多语言AVSR模型在每种非英语语言(除El语外)上的表现都优于单语言模型。