












依赖于注意力机制的大型语言模型(LLM)通常在训练时通常使用固定的上下文长度,模型可以处理的输入序列长度也就有了上限。因此,有很多研究探索了上下文「长度外推(length extrapolation)」方法。
上下文长度外推是指使用较短上下文长度训练过的 LLM,在较长语上下文长度上进行评估,而不针对长上下文做进一步训练。其中,大多数研究都侧重于修改注意力机制中的位置编码系统。
现在,来自 Abacus.AI 的研究团队对现有基于 LLaMA 或 LLaMA 2 模型的上下文长度外推方法进行了广泛的调查,并提出一种新的 truncation 策略。

- 论文地址:https://arxiv.org/abs/2308.10882
- 项目地址:https://github.com/abacusai/long-context
为了验证这种 truncation 策略的有效性,该研究发布了三个新的 13B 参数长上下文模型 ——Giraffe,包括两个基于 LLaMA-13B 训练而成的模型:上下文长度分别为 4k 和 16k;一个基于 LLaMA2-13B 训练而成的模型,上下文长度是 32k,该模型也是首个基于 LLaMA2 的 32k 上下文窗口开源 LLM。

Abacus.AI 的 CEO Bindu Reddy 在推特介绍道。
32k 的上下文窗口是什么概念呢?大概就是 24000 个词,也就是说开源模型 Giraffe 能够处理一篇 2 万字的长文。
图源:https://twitter.com/akshay_pachaar/status/1694326174158143619
方法简介
随着上下文长度的扩展,LLM 架构中的注意力机制会让内存使用量和计算量呈二次增加,因此长度外推方法至关重要。
该研究整理了当前一些有效的上下文长度外推方法,并对它们进行了全面的测试,以确定哪些方法最有效,包括线性缩放、xPos、随机位置编码等。并且,研究团队还提出了几种新方法,其中一种称为 truncation 的新方法在测试中非常有效。
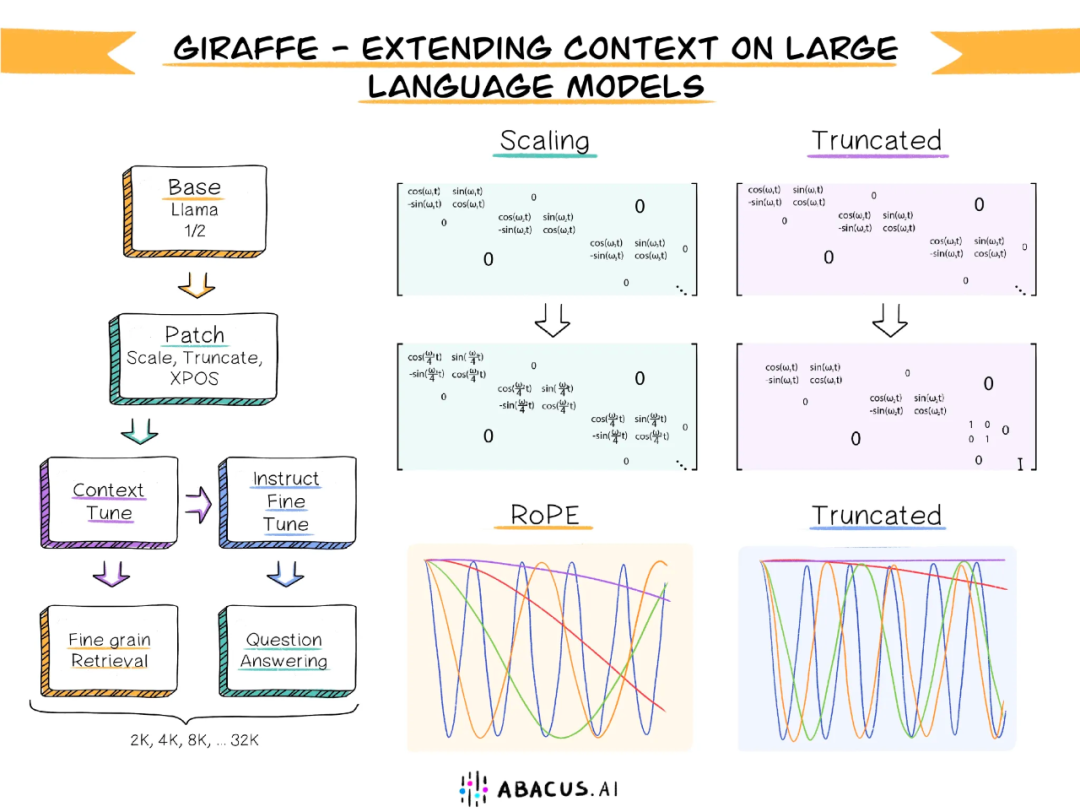
首先,评估 LLM 性能的难点之一是选择正确的评估方法,一个常用的指标是下一个 token 的困惑度,它能够衡量模型根据上下文预测下一个 token 的能力。然而,研究团队认为,通常只需根据整个可用上下文中的一小部分,生成合理连贯的文本分布,就能在该指标上获得良好的结果,因此不适用于长上下文。
为了分析模型在长上下文情况下的性能,该研究使用模型召回(recall)的准确率作为衡量指标,并发布了三个用于评估模型长上下文性能的数据集,分别是 LongChat-Lines、FreeFormQA 和 AlteredNumericQA。其中,LongChat-Lines 用于键 - 值检索任务;FreeFormQA 和 AlteredNumericQA 则是基于自然问题数据集的问答数据集。这三个数据集可以评估 LLM 在键 - 值检索任务和问题解答任务上的能力,模型关注的上下文长度越长,获得的准确率才会越高。

实验及结果
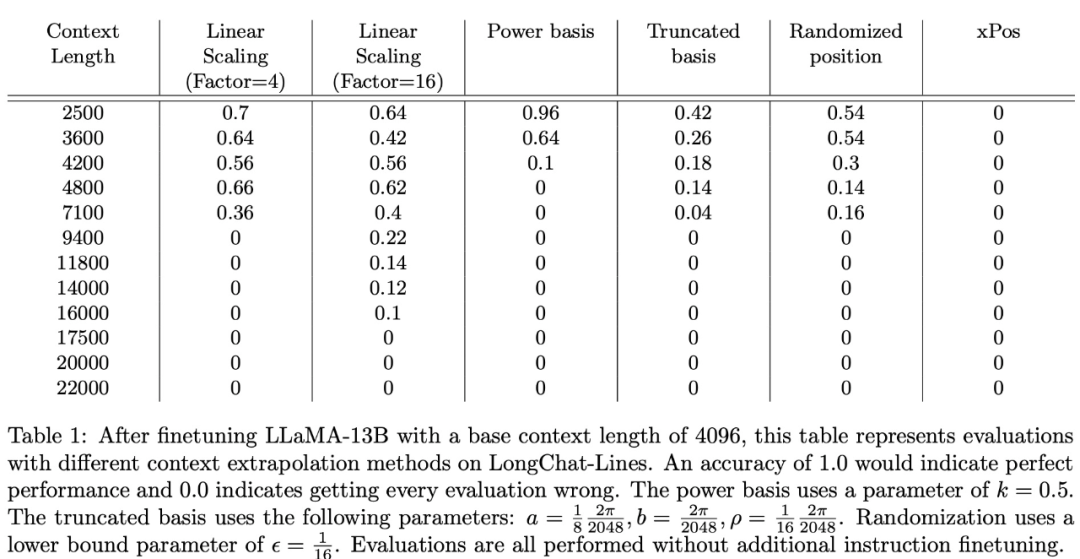
研究团队使用上述三个新数据集对几种上下文长度外推方法进行了评估实验。在 LongChat-Lines 上的实验结果如下表 1 所示:
在 FreeFormQA 和 AlteredNumericQA 数据集上的评估结果如下表 2 和表 3 所示:
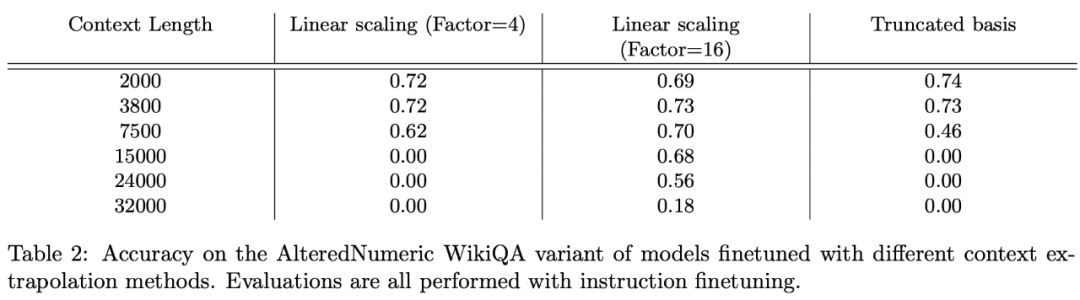

总体而言,线性缩放效果最好,truncation 显示出一些潜力,而 xPos 方法无法在微调中自适应。
感兴趣的读者可以阅读论文原文,了解更多研究内容。


























