












作者 | 尹中浩
“中浩,xxx接口报错了你看一下咋回事”
“稍等一下哈,我看一下。Xxx组的xxx接口报错了,我们这边直接抛错了”
“具体啥问题啊,你看下日志,我去找xxx组的人问一下,现在阻塞流程了啊”
“呃。。。对这个接口的请求日志好难找啊,这个接口请求很频繁,不知道报错的是哪一条。。”
“中浩,xxx接口太慢了,你看下是什么原因导致的”
“这个接口我们掉了很多外部接口啊,不知道具体是哪个接口太慢了”
不知道身在项目的小伙伴对上面这样的对话熟不熟悉。在项目初期,每次收到QA这样的询问,作为开发的我都觉得很头大。(因为有些日志我是真的找不到)基于业务的复杂,项目中接入了大量的外部接口。服务与服务链路之间的调用关系也变得错综复杂。此时,在我们遇上问题排查的时候,追溯到了某个接口之后线索就断了,非常难再往下定位问题。
此时我们自然而然地就会想:难道就没有一种方法能够把请求的整个调用链路记录下来,并通过某个唯一id标记,同时对每个节点都进行记录嘛?这样我们就能通过标记在请求链路上的这个唯一id来快速定位问题,从而大量节省我们排查问题和统计分析的时间。其实上述的只是我们在微服务中最常遇上的两个问题。随着微服务应用数量的极速增加,服务与服务链路之间的调用关系也变得错综复杂。此时,我们也会碰到其他各种难题。
- 系统出现问题后,由于服务链路过长或过于复杂,无法快速准确定位问题。客户端(如浏览器)或者移动端应用报出异常或者错误,也无法确定是哪个服务抛出的异常。
- 某个业务请求非常慢,且总是超时,无法确定系统哪个环节存在性能的问题。
- 修改成:如何快速发现问题并可以通过调用链结合业务日志快速定位错误信息?
- 如何判断故障影响范围,并将各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来,从而直观地审视故障的影响范围?
- 如何梳理服务依赖以及依赖的合理性?如何分析链路性能问题以及实时容量规划?通过分析链路耗时、服务间的依赖关系,就可以得到用户的行为路径,汇总分析出具体出问题的场景。
这个时候,链路追踪能够帮助我们解决这些实际问题。

图片来源:《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 -- Google Technical Report dapper-2010-1, April 2010
假设现在有一个如上图所示的请求,我们应该怎样对这个请求进行记录呢?
链路追踪的重要概念:
现在市面上绝大部分的链路追踪系统都是以谷歌公开论文中提到的Dapper为基础构建而成,所以我们先来一起看看调用链监控中的几个重要概念。
Trace
在之前的描述中我们已经想到,能不能通过一个唯一id来标记我们的请求,从而将整个请求从头到尾串联起来。在链路追踪中,trace是请求在分布式系统中的整个链路视图。我们可以把trace看作一棵二叉树,从中我们能直观地看到请求经过所有服务的路径。从请求到服务器开始,到服务器返回响应数据结束,跟踪每次RPC调用的耗时,并使用唯一标识trace id。在整个请求的调用链中,请求会一直携带 trace id 往下游服务传递,且在整个调用链中始终保持不变,所以在日志中可以通过 trace id 查询到整个请求期间系统记录下来的所有日志。
Span
在建立了一个完整的标识之后,我们还希望对每个节点都进行记录。不然我们只知道一个请求调用了那些服务,但是却不清楚各个服务之间的上下游以及调用关系。span 是代表整个链路中不同服务内部的视图。如果我们将trace看作 一棵树的话,那么span就是这棵树上的不同节点。
每个 span 都记录着 parent id 和 trace id,表明其所属父节点和调用链,其中没有 parent id 的 span 称为 root span,root span 的 id 就是 trace id。请求到达每个服务后,服务都会为请求生成span id,而随请求一起从上游传过来的上游服务的 span id 会被记录成parent-span id。
当前服务生成的 span id 随着请求一起再传到下游服务时,这个span id 又会被下游服务当做 parent-span id记录。通过span的ID我们可以轻松了解服务的父服务是谁,再结合trace id就可以将一条完整的请求调用链串联起来。

图片来源:《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 -- Google Technical Report dapper-2010-1, April 2010
针对以上请求,整个调用的链路就如图所示非常清晰了。
Annotation
在上述遇到的问题中,我们除了希望得到整个请求的链路。还希望能够对其中的某个服务进行调优。这个时候我们就需要对单个服务,或者说是span,记录更多的信息。这个时候就需要Annotation的概念了.

图片来源:《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 -- Google Technical Report dapper-2010-1, April 2010
- Client Start:表示客户端发起请求;
- Server Received:表示服务端收到请求;
- Server Send:表示服务端完成处理,并将结果发送给客户端;
- Client Received:表示客户端获取到服务端返回的响应数据。
结合上图我们,我们可以利用Annotation里的信息来计算一次调用的耗时,只需将客户端结束的时间点减去客户端开始请求的时间点。如果要计算客户端发送网络耗时,即客户端接收请求的时间点减去客户端发送请求的时间点。
Zipkin实例
遵循以上三点链路追踪的核心思路,我们来看一看现在市面上主流的链路追踪款框架都是怎么实现的,这里我们以Zipkin为例。
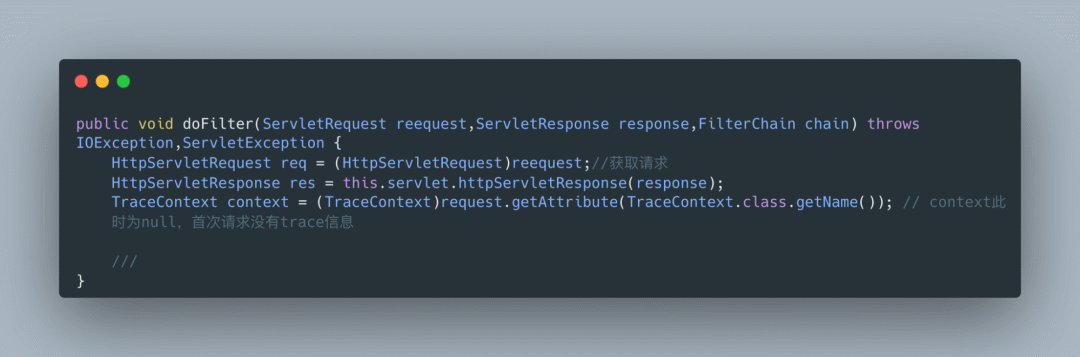
可以看到,我们的请求到达服务器之后被拦截下来:

在这个filter中,框架首先会查询我们请求(request)是否存在链路信息。图中可以看到,我们的初次请求是没有trace的内容的:
同时由于是首次请求,所以请求中也不会有parent-span的信息。在图中也已看到,这个时候框架会给请求生成一个span信息和trace信息:
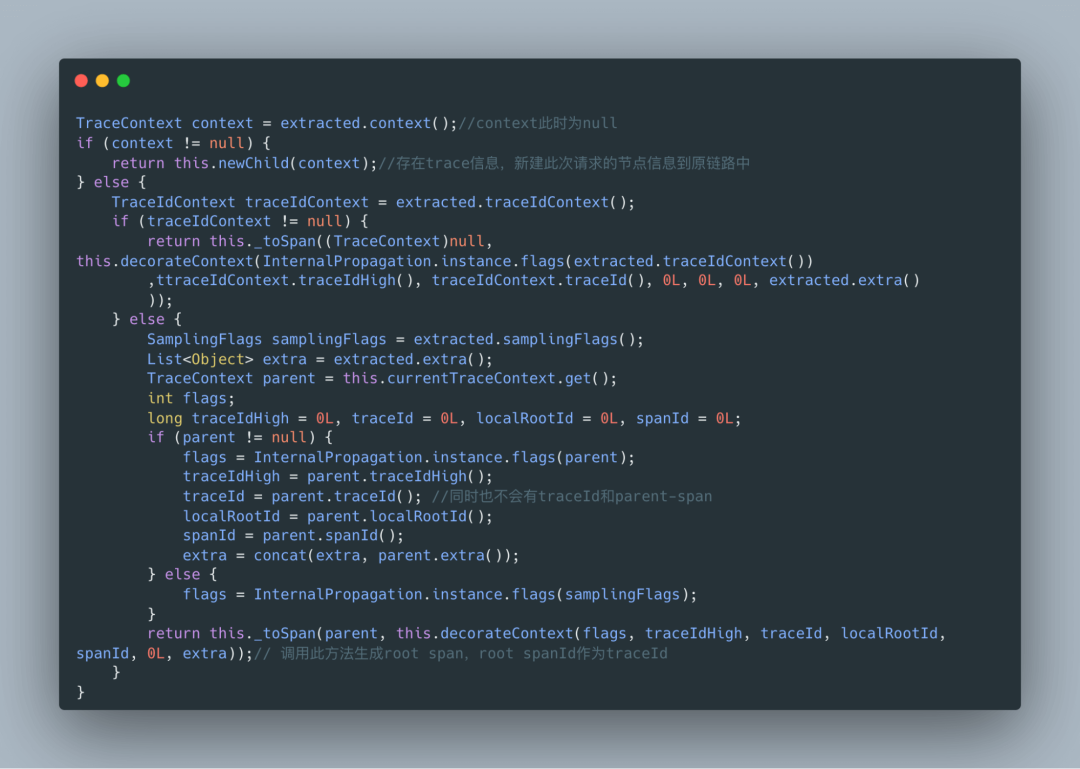
由于是初次请求,span id就作为链路的trace id:

最后框架将生成的span信息和trace信息,设置到我们请求的attribute当中并传递下去:

通过我们的代码,我们能够很清晰的看到zipkin是如何给我们的请求加上trace信息和span信息,并将其传递下去的。此时我们就能够通过trace中的trace id,快速地发现和定位问题。
小结
本文介绍链路追踪的关键概念和实现,让读者初步了解链路追踪的作用。实际上,链路追踪最大的价值在于“关联”。我们可以从数据层面关联应用日志(Logs)、关键事件(Events)、性能指标(Metrics)或诊断工具(Profiling),也可以从系统层面关联用户终端、网关、应用、中间件、容器与基础设施。通过链路追踪,我们可以构建一张轨迹拓扑大图。这张拓扑图覆盖的范围越广,链路追踪就能发挥的价值就越大。全链路追踪是覆盖全部关联 IT 系统的最佳实践方案,能够完整记录用户行为在系统间的调用路径与状态。


























