同一天,Nature双发「脑机接口」重磅研究,足以改变整个人类!
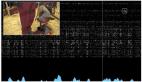
30岁那年,一次毁灭性的中风,让一位47岁加拿大女性几乎完全瘫痪,此后失语18年。
幸运地是,来自加州大学的团队开发了全新脑机接口(BCI),让Ann控制「数字化身」再次开始说话了。
「I think you are wonderful」,当这句话说出口时,对于Ann来说,足足跨越了十多年。

值得一提的是,这个数字化身中面部表情实现,采用了「最后生还者 2」同样的技术。
具体来讲,研究人员在Ann的大脑表层下,植入一系列电极。

当Ann试图说话时,BCI便会拦截大脑信号,将其转化为单词、语音。这里,AI不是去解码整个单词,而是解码音素。
加州大学的BCI实现了能够以每分钟78个单词的速度说话,远远超过Ann曾经带过的设备,即每分14个单词。

正如论文题目所示,研究关键实现了「语音解码」和「数字化身控制」,也正是与以往研究最大的不同。
全新的BCI技术通过面部表情,为数字化身Avatar制作动画,以模仿人类自然交流的细节。

论文地址:https://www.nature.com/articles/s41586-023-06443-4
这项突破性的研究于8月23日在Nature发表。这是首次,直接从大脑信号合成语音和面部动作,标志着脑机接口的一大飞跃。
另一篇登上Nature的研究,同样是关注将语音神经活动转化为文字的脑际接口。
研究结果称,瘫痪患者能够以每分62个字的速度进行交流,比之前的研究快3.4倍。

论文地址:https://www.nature.com/articles/s41586-023-06377-x
两项重磅研究,全都将语音大脑信号转成文本的速度大幅提升,甚至还让虚拟化身做人类「嘴替」。
创世的脑机接口,让人类离机械飞升不远了。

第一句话出口时,她幸福地笑了
三十而立,对于每个人来说,人生还有许多惊喜需要开启。
对于Ann来说,作为加拿大的一名高中数学老师,正在讲台上教书育人,桃李满天下。
然而,突如其来的一场中风,让她瞬间失去对身体所有肌肉的控制,甚至无法呼吸。
从此,她再也没有说出一句话。

脑中风最直接的后果,就是无法控制面部肌肉,导致面瘫,无法说话。
在接下来的5年里,Ann经常辗转难眠,害怕自己会在睡梦中死去。
经过多年的物理治疗,也看到了一些初步成果。
她能够做出有限的面部表情,以及一些头部和颈部运动,尽管如此,她依旧无法驱动面部说话的肌肉。
为此,她也接受了脑机接口的手术。
不过以往的BCI技术不够先进,只能让Ann进行艰难缓慢的交流,无法将她的大脑信号解码为流利的语言。
Ann轻轻移动头部,通过设备在电脑屏幕上缓慢地打字,「一夜之间,我的一切都被夺走了。」
2022年,Ann决定再次做出尝试,自愿成为加州大学研究团队的受试者。
添加一张脸,一个声音
对此,研究人员记录了Ann试图背诵单词时的大脑信号模式,以训练人工智能算法识别各种语音信号。
值得一提的是,训练的AI是来解码音素——语音的基本要素,而不是整个单词,使其速度和通用性提高了3倍。
为了做到这一点,研究小组在安的大脑表面植入了一个由253个电极组成薄如纸片的矩形电极。
然后,由一根电缆插入Ann头部固定的端口,将电极连接到一组计算机上。
这一系统,现在能以每分近80个单词的速度将Ann的尝试语音转录成文本,远远超过了她以前的BCI设备的速度。
通过Ann在2005年的婚礼录像,研究团队利用人工智能重建了一个人独特的语调和口音。
然后,他们利用一家致力于语音生成动画技术公司Speech Graphics开发的软件创建了一个个性化数字化身,能够实时模拟Ann的面部表情。
他能够与Ann试图说话时大脑发出的信号相匹配,并将这些信号转换成她的化身面部动作。
包括下巴张开和闭合、嘴唇撅起和抿紧、舌头上翘和下垂,以及快乐、悲伤和惊讶的面部动作。
现在,当Ann尝试说话时,数字化身就会无缝地制作动画,并说出她想要的话。

这里,著名的冒险游戏「最后生还者 2」「光环:无限」等在呈现生动多样的人物面部表情时,同样使用了Speech Graphics的面部捕捉技术。

Speech Graphics的首席技术官兼联合创始人Michael Berger表示:
创建一个可以实时说话、表情和表达的数字化身,并直接与受试者的大脑相连,显示了人工智能驱动面部的潜力远远超出了视频游戏。
仅恢复说话本身就令人印象深刻,而面部交流是人类的固有特性,它让患者再次拥有了这个非凡的能力。
加州大学的这项研究工作不仅仅是BCI技术突破,更是无数特殊人士的希望。
这项技术突破让个人实现独立,自我表达触手可及,为Ann和无数因瘫痪而失去语言能力的人,带去了前所未知的希望。
对于Ann如今13个月大的女儿来说,BCI突破让她听到了,从诞生起,从未聆听过的母亲的声音。

据介绍,他们开发的下一个BCI版本,是无线的,省去了连接到物理系统的麻烦。
加州大学这项实验领导者Edward Chang已经用了十多年的时间推进脑机接口技术。
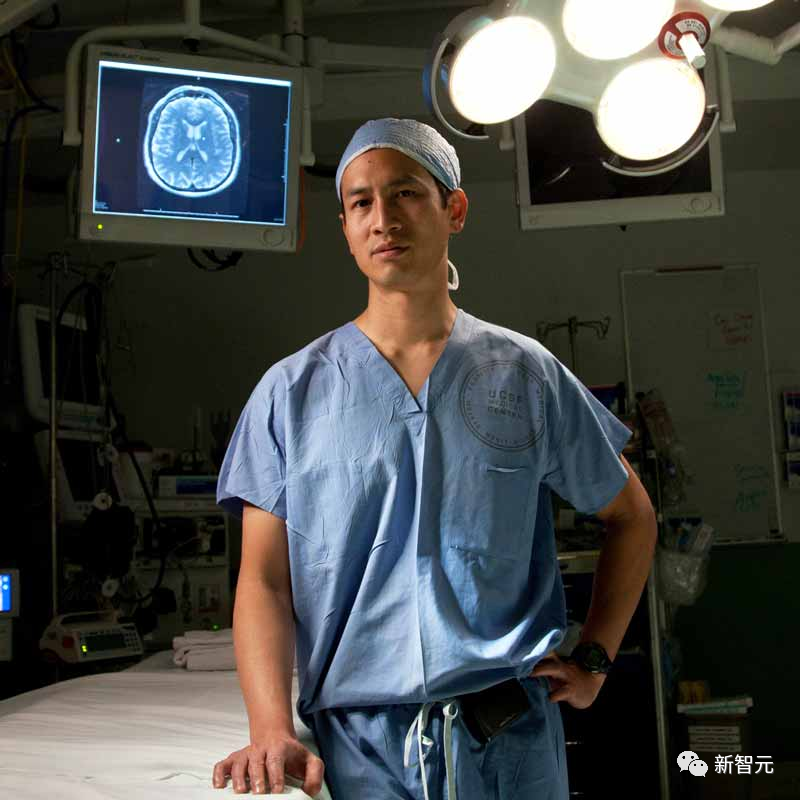
2021年,他和他的研究团队开发了一种「语言神经科技辅具」(speech neuroprosthesis),让一名严重瘫痪的男子能够用完整的句子进行交流。
这项技术,能捕捉大脑指向声道的信号,并将其转化为文字显示在屏幕上,标志着首次证明了语音-大脑信号可以被解码为完整的单词。
那么,加州大学让Ann「开口说话」的背后技术具体是如何实现的呢?
技术实现
在这项研究中,由加州大学旧金山分校神经外科主任Edward Chang博士领导的研究团队将253针电极阵列植入了Ann的大脑语言控制区。

这些探头监测并捕获了神经信号,并通过头骨中的电缆端口将它们传输到一组处理器中,在这个计算堆栈( computing stack)中有一个机器学习AI。
几周来,Ann与团队合作训练系统的人工智能算法,以识别她的大脑中1000多个单词的神经信号模式。
这需要一遍又一遍地重复1,024个单词的会话词汇中的不同短语,直到计算机识别出与所有基本语音相关的大脑活动模式。
研究人员没有训练AI识别整个单词,而是创建了一个系统,可以从音素的较小组件中解码单词。音素以与字母形成书面单词相同的方式形成口语。例如,「Hello」包含四个音素:「HH」、「AH」、「L」和「OW」。
使用这种方法,计算机只需要学习39个音素,就可以破译英语中的任何单词。这既提高了系统的准确性,又使速度提高了三倍。
但这只是研究的一个小序曲,重头戏在AI对Ann意图的解码和映射。

电极被放置在大脑区域,研究小组发现这些区域对语言至关重要
研究团队通过深度学习模型,将检测到的神经信号映射到语音单元、语音特征,以输出文本、合成语音和驱动虚拟人物。
刚刚提到,研究人员与Speech Graphics公司合作制作了患者的虚拟形象。
SG的技术根据对音频输入的分析,「逆向设计」出面部必要的肌肉骨骼动作,然后将这些数据实时输入游戏引擎,制作成一个无延迟的形象。
由于病人的精神信号可以直接映射到化身上,因此她也可以表达情感、甚至进行非语言交流。
多模态语音解码系统概述
研究人员设计了一个语音解码系统,帮助因严重瘫痪和无法发声的Ann重新与他人进行沟通交流。

Ann与团队合作训练AI算法,以识别与音素相关的大脑信号(音素是形成口语的语音亚单元)
研究人员在Ann的大脑皮层上植入了一个有253个通道的高密度ECoG阵列,特别是覆盖了与语言有关的大脑皮层区域,包括SMC和颞上回。

简单来说,这些区域与研究人员的面部、嘴唇、舌头和下巴的动作有关 (1a-c)。
通过该阵列,研究人员可以检测到这些区域在Ann想要说话时的电信号。
研究人员注意到当Ann尝试移动她的嘴唇、舌头和下巴时,阵列可以捕获到不同的激活信号 (1d)。

为了研究如何从大脑信号中解码语言,研究人员让Ann在看到屏幕上的句子后尝试无声地说出这个句子,即做出发音的动作。
研究人员从Ann头部的253个ECoG电极捕获到的信号中,提取了两种主要的大脑活动信号:高伽玛活动(70-150赫兹)和低频信号(0.3-17赫兹)。
随后便使用了深度学习模型去学习如何从这些大脑信号中预测发音、语音和口腔动作,最终将这些预测转化为文本、合成语音和虚拟化身的动作。
文本解码:
研究团队希望从大脑中解码文本,特别是在患有发音困难的人尝试说话的情况下。
但他们早期的努力遭遇了解码速度慢和词汇量小的限制。
本研究中,他们使用了电话解码(phone decoding)的方法,这使他们能够从大词汇量中解码任意短语,并实现接近自然说话的速度。
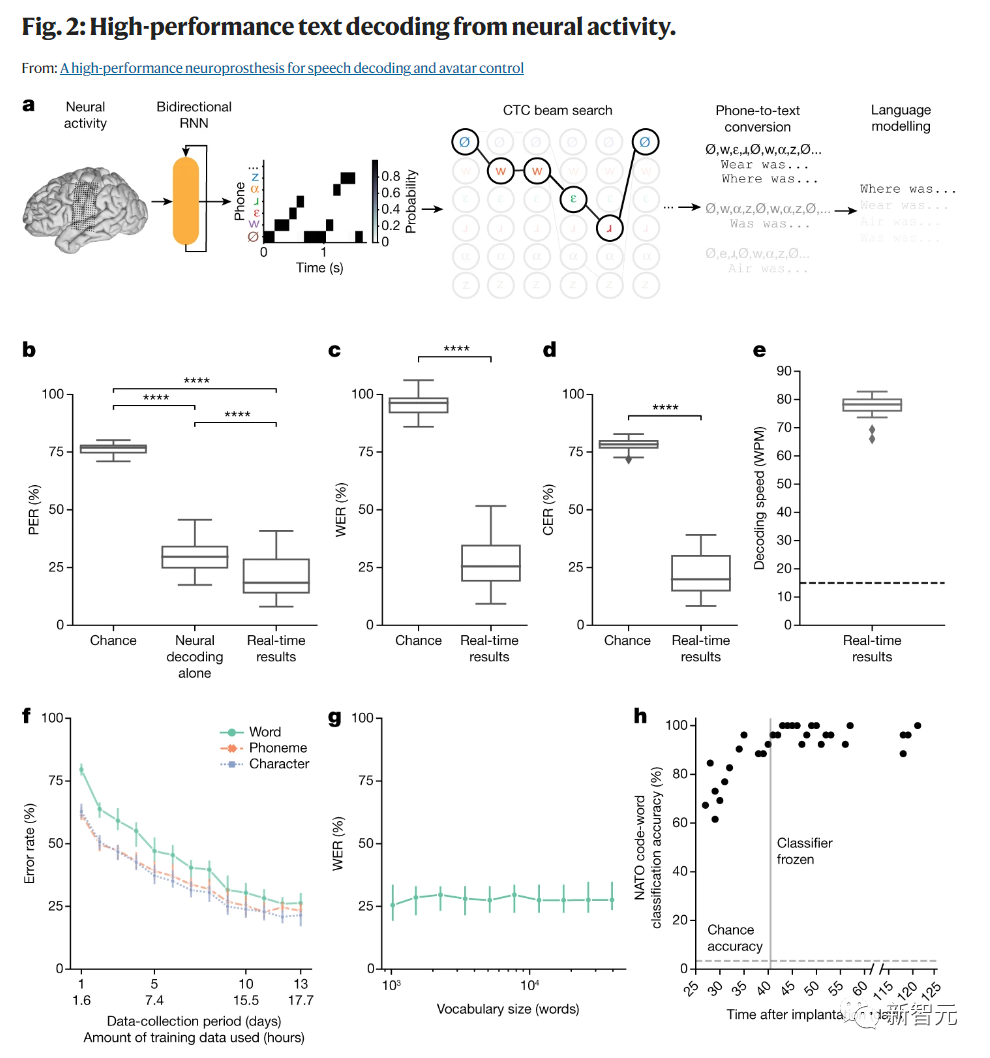
为了评估实时性能,当Ann尝试默读249个句子时,研究团队解码了文本。这些句子是从一个包含1024个单词的句子集中随机选择的,并且在模型训练时并未使用过。为了解码,他们从ECoG信号中提取了特征,并使用了双向循环神经网络(RNN)进行处理。
他们使用了几个标准指标来评估解码性能,包括单词错误率(WER)、电话错误率(PER)、字符错误率(CER)和每分钟单词数(WPM)。
研究团队观察到,当解码速度为78.3 WPM时,这已经超过了Ann使用其辅助设备的通常通信速度,并且接近自然说话的速度。
为了评估信号的稳定性,他们进行了一个单独的任务,要求Ann默读NATO的26个代码词或尝试进行四种手势动作。结果显示,神经网络的分类器性能非常好,平均准确率高达96.8%。
最后,为了评估在没有任何单词之间暂停的情况下对预定义句子集的模型性能,他们对两个不同的句子集进行了模拟解码,结果显示对于这些经常被用户使用的有限、预定义的句子,解码速度非常快且准确性非常高。
语音合成
文本解码的另一种方法是直接从记录的神经活动中合成语音,这可以为无法说话的人提供一条更自然、更有表现力的交流途径。
以前对言语功能完好的人进行的研究表明,在发声或模仿说话时,可以通过神经活动合成可理解的语音,但这种方法尚未在瘫痪者身上得到验证。
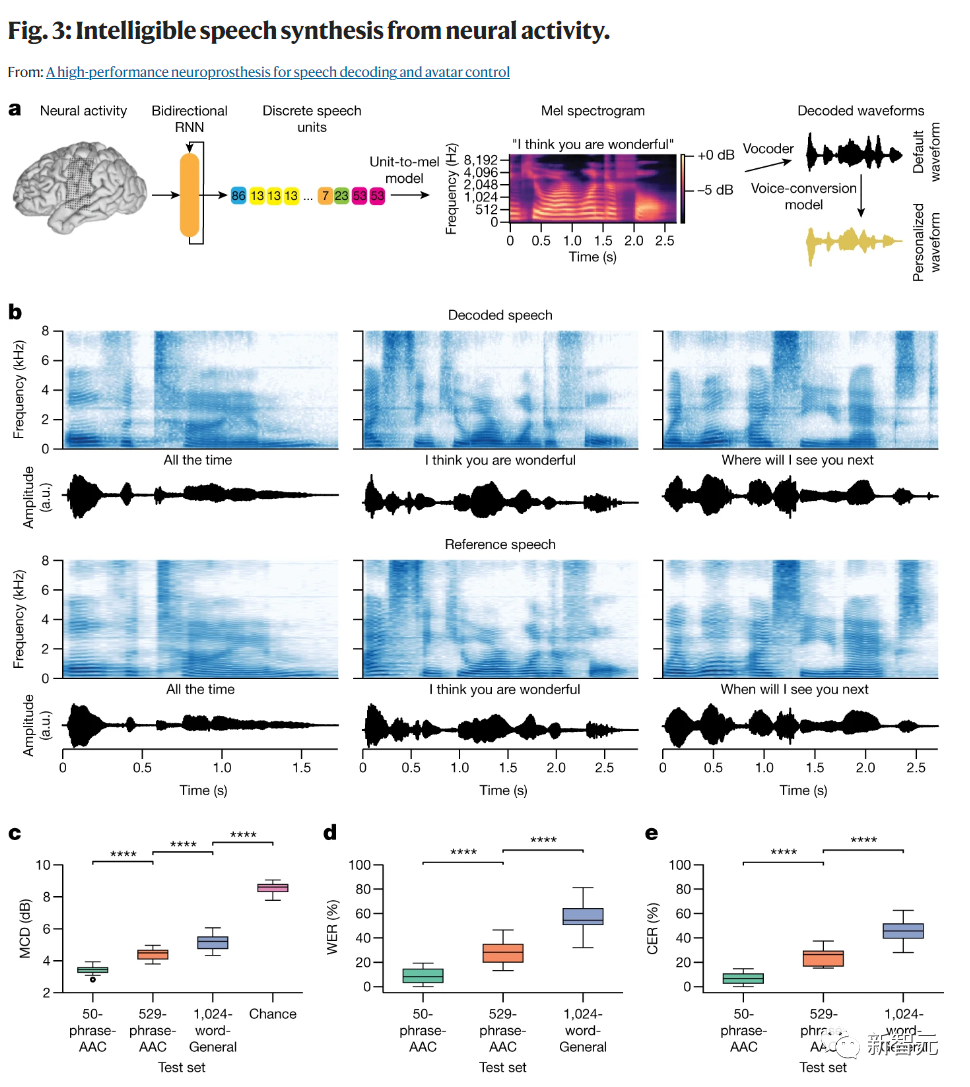
研究人员将在音频-视觉任务条件下试图默读时的神经活动直接转化为可听见的语音进行了实时语音合成(图3a)。
为了合成语音,研究人员将神经活动的时间窗口传递到一个双向循环神经网络(RNN)中。
在测试之前,研究人员训练RNN预测每个时间步骤的100个离散语音单元的概率。
为了创建训练的参考语音单元序列,研究人员使用了HuBERT,这是一个自监督的语音表示学习模型,它将连续的语音波形编码为捕获潜在音位和发音表示的离散语音单元的时间序列。
在训练过程中,研究人员使用了CTC损失函数,使RNN能够在没有参与者的静默言语尝试和参考波形之间的对齐的情况下,学习从ECoG特征到这些参考波形中派生的语音单元之间的映射。
在预测了单元概率后,将每个时间步的最可能单元传入一个预先训练的单元到语音模型中,该模型首先生成一个梅尔频谱图,然后会实时将该梅尔频谱图合成为听得见的语音波形。
在离线情况下,研究人员使用了一个在参与者受伤之前的短时间段内训练的语音转换模型,将解码的语音处理成参与者自己的个性化合成声音。
面部头像解码
研究人员开发了一种面部化身BCI界面,用于将神经活动解码成发音的语音手势,并在视听任务条件下呈现出动态的虚拟面部(图4a)。
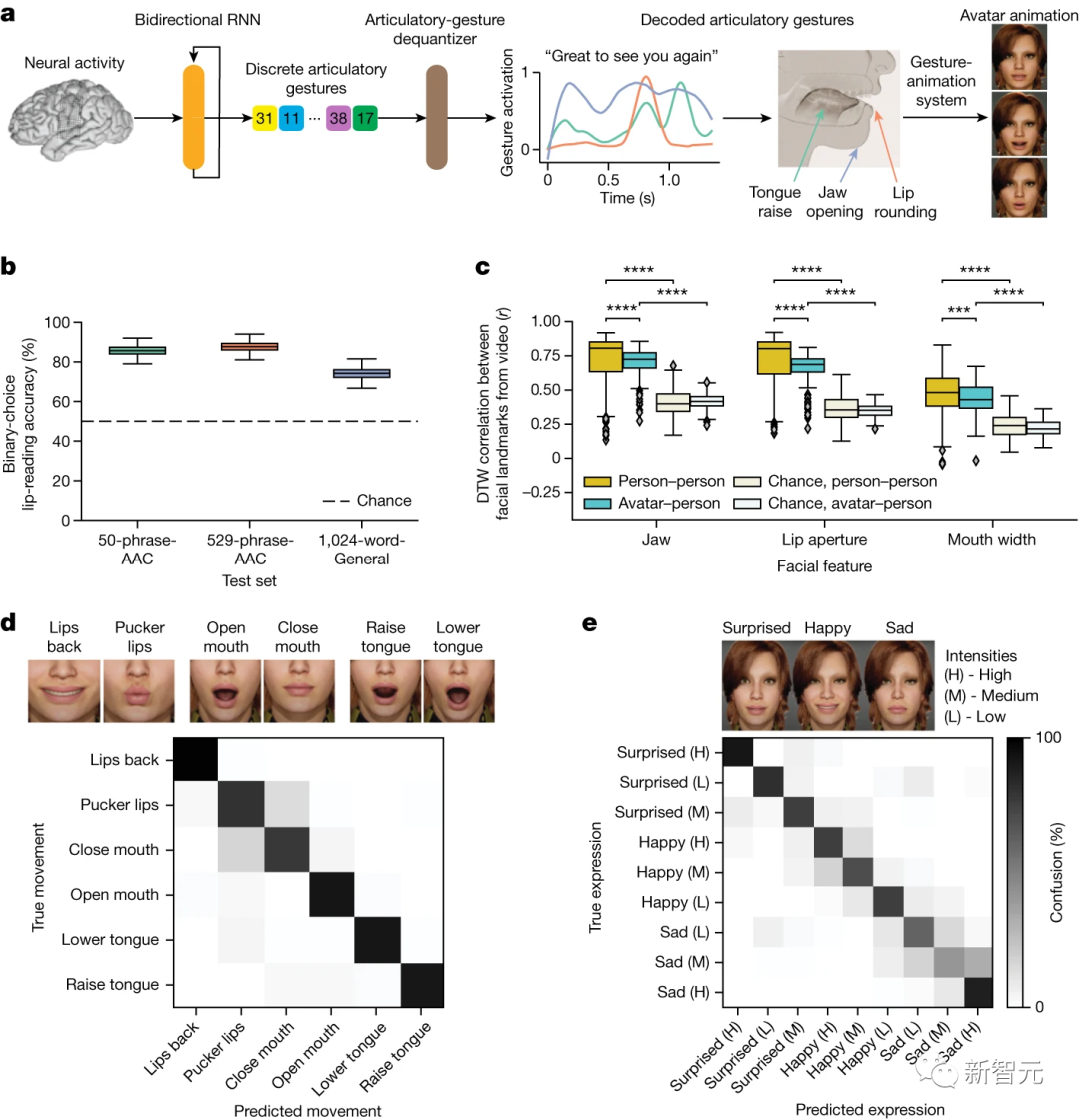
研究人员为了实现合成面部头像的动态动画,采用了一个被设计来将语音信号转化为面部动作动画的头像动画系统(Speech Graphics)。
研究者采用了两种办法来为头像制作动画:直接方法和声学方法。直接方法是从神经活动中直接推测发音动作,不通过任何语音中介。
声学方法则用于实时音视频合成,它确保解码的语音音频和头像的动作之间达成低延迟同步。
除了伴随合成语音的发音动作外,完整的头像脑机接口还应该能够显示与语音无关的口面动作和表达情感的动作。
为此,研究者收集了参与者在执行额外两项任务时的神经数据,一是发音动作任务,二是情感表达任务。
结果显示,参与者可以控制头像BCI来显示发音动作和强烈的情感表达,这揭示了多模态通信脑机接口恢复表达有意义的口面动作的潜力。
发音表征驱动解码
在健康的说话者中,SMC(包括前中央回和后中央回)的神经表征编码了口面肌肉的发音动作。
将电极阵列植入到参与者的SMC中心时,研究人员推测:即使在瘫痪后,发音的神经表示仍然存在,并且推动了语音解码的性能。
为了评估这一点,研究者拟合了一个线性的时间感受场编码模型,根据在1024字通用文本任务条件下,文本解码器计算的音素概率来预测每个电极的HGA。
对于每一个被激活的电极,研究者计算了每个音素的最大编码权重,从而得到了一个音位调谐空间。在这个空间中,每个电极都有一个与其相关的音素编码权重向量。