端到端自动驾驶是一种很有前途的模式,因为它避开了与模块化系统相关的缺点,比如较高的系统复杂性。自动驾驶超越了传统的交通模式,提前主动识别关键事件,确保乘客的安全,并提供舒适的交通环境,特别是在高度随机和可变的交通环境中。本文全面回顾了端到端自动驾驶技术。
首先阐述了自动驾驶任务的分类,包含端到端神经网络的使用,涵盖了从感知到控制的整个驾驶过程,同时解决了现实世界应用中遇到的关键挑战。分析了端到端自动驾驶的最新发展,并根据基本原理、方法和核心功能对研究进行了分类。这些类别包括感知输入、主要输出和辅助输出、从模仿到强化学习的学习方法以及模型评估技术。本文还调查了包括对可解释性和安全性方面的详细讨论。最后评估了最先进的技术,确定了挑战,并探索了未来的可能性。
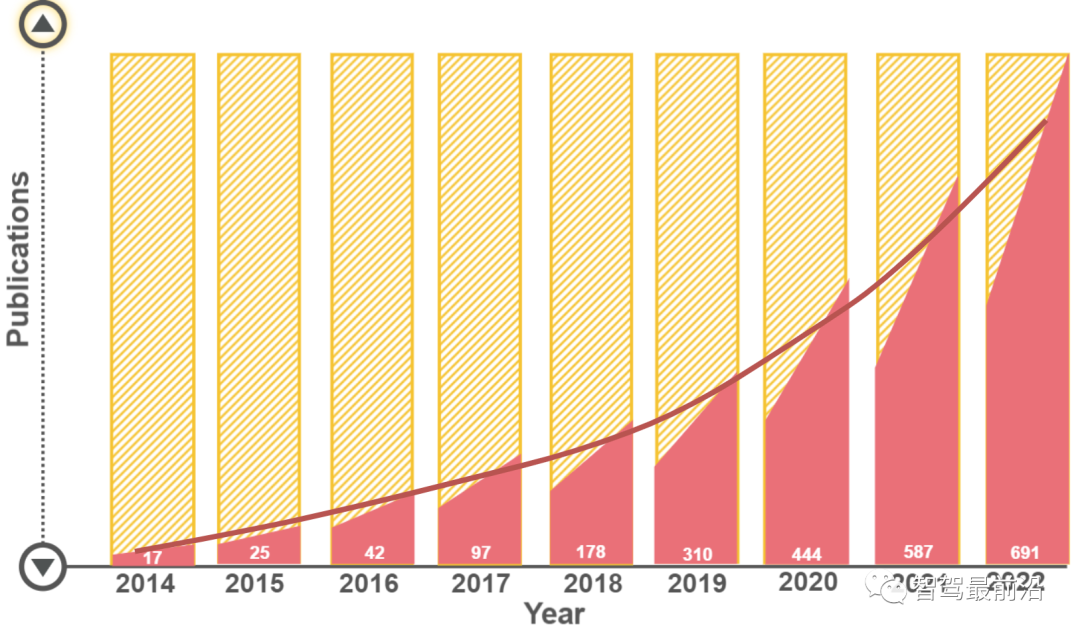
Fig. 1: The number of articles in the Web of Science databasecontaining the keywords ‘End-to-End’ and ‘Autonomous Driving’ from 2014 to 2022 illustrates the increasing trend in the research community.
总结来说本文的主要贡献如下:
- 这是第一篇专门探讨使用深度学习的端到端自动驾驶的综述论文。我们对基本原理、方法和功能进行了全面分析,深入研究了该领域的最新技术进步;
- 我们提出了一个详细的分类(图2),基于输入模式、输出模式和基本的学习方法。此外还对安全性和可解释性方面进行了全面检查,以识别和解决特定领域的挑战;
- 我们提出了一个基于开环和闭环评估的评估框架。此外还总结了一份公开可用的数据集和仿真的汇总列表。最后评估了最近的方法,并探索了有趣的未来可能性。
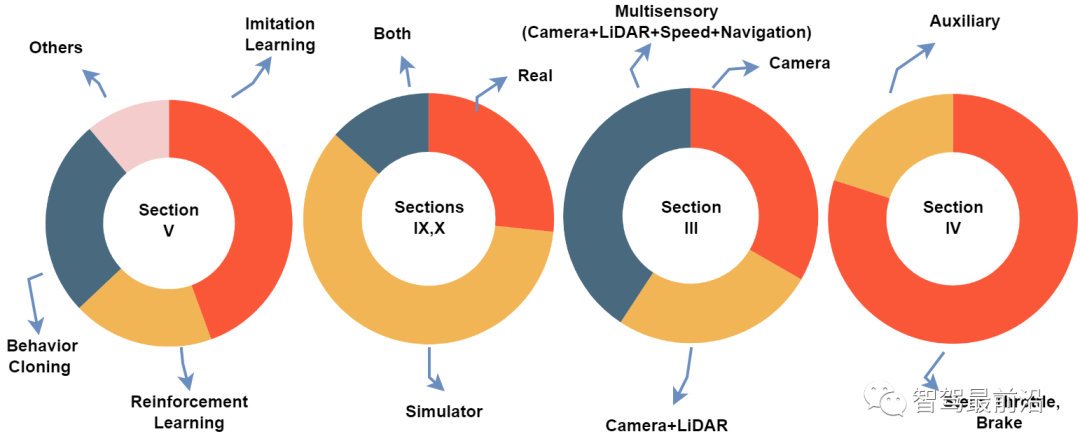
Fig. 2: The charts illustrate statistics of the papers included in this survey according to learning approaches (section V),environment being utilized for training (sections IX, X), input modality (section III), and output modality (section IV)
01 端到端系统体系结构
通常,模块化系统被称为中间范式,并被构建为离散组件的管道(图3),连接传感器输入和运动输出。模块化系统的核心过程包括感知、定位、建图、规划和车辆控制。模块化流水线首先将原始传感器数据输入到感知模块,用于障碍物检测,并通过定位模块进行定位。随后进行规划和预测,以确定车辆的最佳和安全行程。最后控制器生成安全操纵的命令。模块化系统的详细概述可在补充材料中找到。

Fig. 3: Comparison between End-to-End and modular pipelines. End-to-End is a single pipeline that generates the control signal directly from perception input, whereas a modular pipeline consists of various sub-modules, each with taskspecific functionalities.
另一方面,直接感知或端到端驱动直接从传感器输入输出自车运动。它优化了驾驶管道(图3),绕过了与感知和规划相关的子任务,允许像人类一样不断学习感知和行动。Pomerleau Alvinn首次尝试了端到端驾驶,该公司训练了一个三层传感器运动全连接网络来输出汽车的方向。端到端驾驶基于传感器输入输出自车运动,这种运动可以是各种形式的。然而,最突出的是相机、LiDAR、导航命令、和车辆动力学,如速度。这种感知信息被用作主干模型的输入,主干模型负责生成控制信号。自车运动可以包含不同类型的运动,如加速、转弯、转向和蹬踏。此外,许多模型还输出附加信息,例如安全机动的成本图、可解释的输出或其他辅助输出。
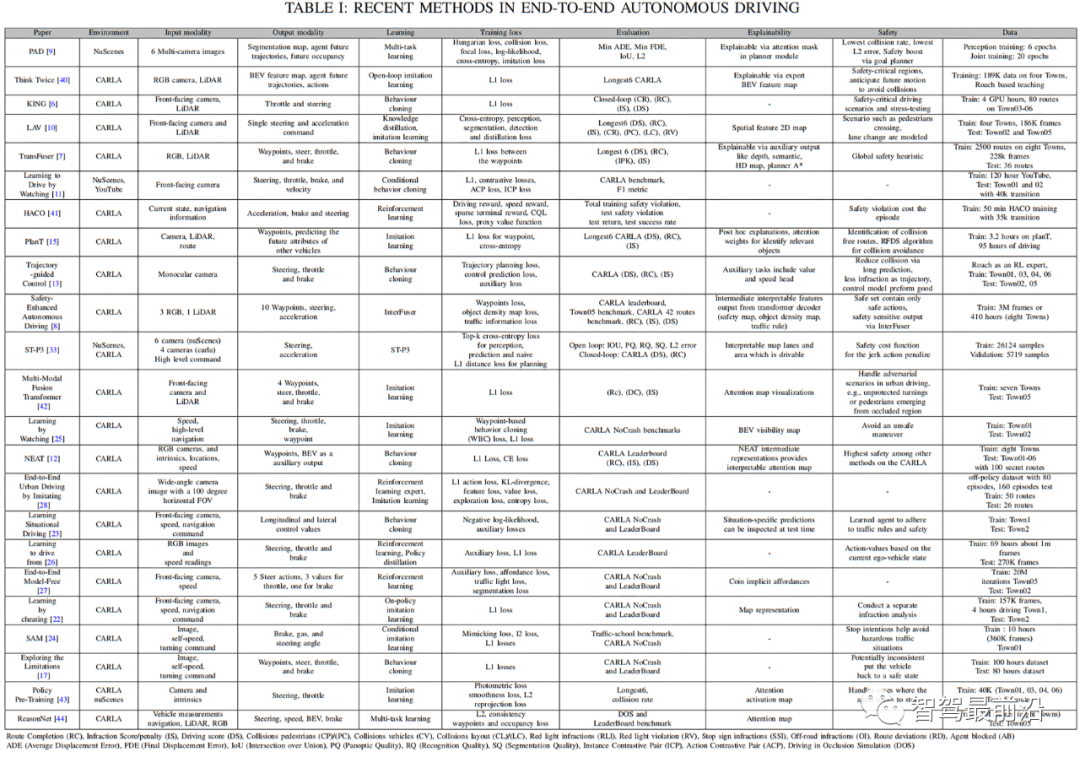
端到端驾驶有两种主要方法:要么通过强化学习(RL)探索和改进驾驶模型,要么使用模仿学习(IL)以监督的方式训练驾驶模型,以模仿人类驾驶行为。监督学习范式旨在从专家演示中学习驾驶风格,作为模型的训练示例。然而,扩展基于IL的自动驾驶系统具有挑战性,因为不可能覆盖学习阶段的每个实例。另一方面,RL的工作原理是通过与环境的互动,随着时间的推移最大化累积奖励,网络根据其行为做出驾驶决策以获得奖励或处罚。虽然RL模型训练是在线进行的,并且可以在训练过程中探索环境,但与模仿学习相比,它在利用数据方面的效果较差。表I总结了端到端驾驶的最新方法。
02 输入模态
1)相机:基于相机的方法在端到端驱动中显示出了有希望的结果。例如,Toromanoff等通过在城市环境中使用基于视觉的方法赢得 CARLA 2019自动驾驶挑战赛。使用单目和双目是图像到控制端到端驾驶的自然输入方式。
2)激光雷达:自动驾驶的另一个重要输入源是LiDAR传感器。LiDAR能够抵抗光照条件,并提供准确的距离估计。相比其他感知传感器,激光雷达数据最丰富,提供的空间信息最全面。它利用激光来检测距离并生成点云,点云是空间的3D表示,其中每个点都包含反射传感器激光束的表面的(x,y,z)坐标。在定位车辆时,生成里程测量结果至关重要。许多技术利用LiDAR在鸟瞰图 (BEV)、高清 (HD)地图和SLAM中进行特征映射。这些定位技术可以分为基于配准的方法、基于特征的方法和基于学习的方法。
3)多模态:多模态在关键感知任务中优于单模态,并且特别适合自动驾驶应用,因为它结合了多传感器数据。根据何时组合多传感器信息,信息利用可分为三大类。在早期融合中,传感器数据先进行组合,然后再将其输入可学习的端到端系统。在中期融合中,信息融合是在一些预处理阶段或一些特征提取之后完成的。在后期融合中,输入被单独处理,它们的输出被融合并由另一层进一步处理。
4)语义表示:端到端模型也可以将语义表示作为输入。这种表示侧重于学习车辆及其环境的几何和语义信息。
它通常涉及将各种感知传感器的几何特征投影到图像空间,例如鸟瞰图和范围视图。虽然原始RGB图像包含所有可用信息,但事实证明,显式合并预定义的表示并将其用作附加输入可以增强模型的弹性。Chen等在学习的语义图上采用循环注意力机制来预测车辆控制。此外,一些研究利用语义分割作为导航目的的附加表示。
5)导航输入:端到端驾驶模型可以包含高级导航指令或专注于特定的导航子任务,例如车道维护和纵向控制。导航输入可以源自路径规划器或导航命令。路径是由全局规划器提供的全球定位系统(GPS)坐标中的一系列离散端点位置定义的。TCP模型接收相关的导航指令,例如留在车道上、左/右转和目标,以生成控制动作,如图4(c)所示。FlowDriveNet考虑了全局规划器的离散导航命令和导航目标的坐标。除了上述输入之外,端到端模型还包含车辆动力学,例如自车辆速度。图4(b)说明了NEAT如何利用速度特征来生成航路点。

Fig. 4: The input-output representation of various End-to-End models: (a) Considered RGB image and LiDAR BEV representations as inputs to the multi-modal fusion transformer [7] and predicts the differential ego-vehicle waypoints. (b) NEAT [12] inputs the image patch and velocity features to obtain a waypoint for each time-step used by PID controllers for driving. (c) TCP [13] takes input image i, navigation information g, current speed v, to generate the control actions guided by the trajectory branch and control branch. (d) LAV [10] uses an image-only input and predicts multi-modal future trajectories used for braking and handling traffic signs and obstacles. (e) UniAD [9] generates attention mask visualization which shows how much attention is paid to the goal lane as well as the critical agents that are yielding to the ego-vehicle. (f) ST-P3 [33] outputs the sub cost map from the prediction module (darker color indicates a smaller cost value). By incorporating the occupancy probability field and leveraging pre-existing knowledge, the cost function effectively balances safety considerations for the final trajectory.
03 输出模态
通常端到端自动驾驶系统输出控制命令、航迹点或轨迹。此外,它还可能产生额外的表示,例如成本图和辅助输出。图4说明了一些输出模式。
a) 航迹点:预测未来航迹点是一种更高级别的输出模式。几位作者使用自回归路点网络来预测差分路点。轨迹也可以表示坐标系中的航路点序列。使用模型预测控制(MPC)和比例积分微分(PID)将网络的输出航路点转换为低级转向和加速度。纵向控制器考虑连续时间步路点之间矢量的加权平均值的大小,而横向控制器考虑它们的方向。理想的航迹点取决于所需的速度、位置和旋转。横向距离和角度必须最小化,以最大化奖励(或最小化偏差)。利用航迹点作为输出的好处是它们不受车辆几何形状的影响。此外,控制器更容易分析航迹点以获取转向等控制命令。连续形式的航迹点可以转化为特定的轨迹。
b) 惩罚函数:为了车辆的安全操纵,许多轨迹和航迹点都是可能的。成本用于在可能性中选择最佳的一种。它根据最终用户定义的参数(例如安全性、行驶距离、舒适度等)为每个轨迹分配权重(正分或负分)。Zeng等采用神经运动规划器,使用成本量来预测未来的轨迹。Hu等采用了一种成本函数,该函数利用学习到的占用概率场(由分割图(图4(f))表示)和交通规则等先验知识来选择成本最小的轨迹。
c)直接控制和加速:大多数端到端模型在特定时间戳提供转向角和速度作为输出。输出控制需要根据车辆的动力学进行校准,确定适当的转弯转向角度以及在可测量距离处停止所需的制动。
d) 辅助输出:辅助输出可以为模型的运行和驾驶动作的确定提供附加信息。几种类型的辅助输出包括分割图、BEV图、车辆的未来占用率以及可解释的特征图。如图 4(e) 和 (f) 所示,这些输出为端到端管道提供了附加功能,并帮助模型学习更好的表示。辅助输出还有助于解释模型的行为,因为人们可以理解信息并推断模型决策背后的原因。
04 学习方法
以下是端到端驾驶的不同学习方式。
模仿学习
模仿学习(IL)基于从专家演示中学习的原则,通常由人类执行。这些演示训练系统模仿专家在各种场景(例如车辆控制)中的行为。大规模的专家驾驶数据集很容易获得,可以通过模仿学习利用这些数据集来训练按照类人标准执行的模型(见图 5)。Alvinn 是模仿学习在端到端自动驾驶车辆系统中的第一个应用,展示了以高达55英里/小时的速度驾驶汽车的能力。它经过训练,可以使用从人类驾驶员收集的实时训练数据来预测转向角。行为克隆(BC)、直接策略学习(DPL)和逆强化学习(IRL)是模仿学习在自动驾驶领域的延伸。
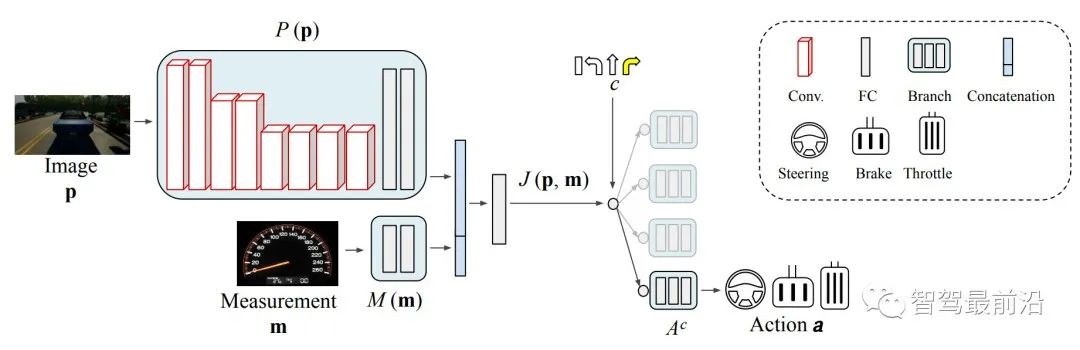
Fig. 5: Vehicle maneuvers, represented by a triplet of steering angle, throttle, and brake, depend on a high-level route navigation command (e.g., turn-left, turn-right, go-straight, continue), as well as perception data (e.g., RGB image) and vehicle state measurements (e.g., speed). These inputs guide the specific actions taken by the vehicle, enabling it to navigate the environment effectively through conditional imitation learning [32].
模仿学习的主要目标是训练一个策略,将每个给定状态映射到相应的动作(图 5),尽可能接近给定的专家策略,给定具有状态动作对的专家数据集:

1)行为克隆:行为克隆是监督模仿学习任务,其目标是将专家分布中的每个状态-动作组合视为独立同分布(IID)示例,并最大限度地减少训练策略的模仿损失:
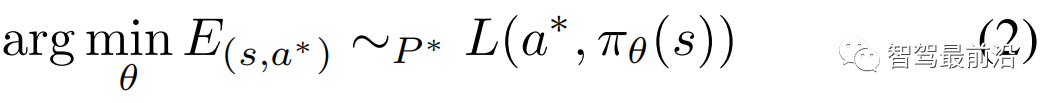
行为克隆假设专家的行为可以通过观察得到充分解释,因为它训练模型根据训练数据集直接从输入数据映射到输出数据(图6)。然而在现实场景中,有许多潜在变量影响和控制驾驶代理。因此有效地学习这些变量至关重要。

Fig. 6: Behavior cloning [23] is a perception-to-action driving model that learns behavior reflex for various driving scenarios. The agent acquires the ability to integrate expert policies in a context-dependent and task-optimized manner, allowing it to drive confidently
2)直接策略学习:与将传感器输入映射到控制命令的模仿学习相反,直接策略学习旨在直接学习将输入映射到驾驶行为的最优策略。它使智能体能够探索周围环境并发现新颖且高效的驾驶策略。相比之下,行为克隆受到训练数据集的限制,仅包含特定行为,在新场景上可能表现不佳。在线模仿学习算法DAGGER提供了针对级联错误的鲁棒性并提高了泛化性。然而,直接策略学习的主要缺点是在培训过程中持续需要专家的参与,这既昂贵又低效。
3)逆强化学习:逆强化学习(IRL)旨在通过奖励函数推断潜在的特定行为。基于特征的IRL教授高速公路场景中的不同驾驶方式。人类提供的示例用于学习不同的奖励函数以及与道路使用者交互的能力。最大熵(MaxEnt)逆强化学习是基于最大熵原理的基于特征的IRL的扩展。该范例有力地解决了奖励模糊性并处理次优化。主要缺点是 IRL 算法的运行成本昂贵。它们对计算的要求也很高,在训练过程中不稳定,并且可能需要更长的时间才能收敛到较小的数据集。需要更高效的计算方法来获得奖励函数。
强化学习
强化学习(RL)是解决分布转移问题的一种有前途的方法。它的目标是通过与环境交互来随着时间的推移最大化累积奖励,并且网络根据其行为做出驾驶决策以获得奖励或惩罚。IL无法处理与训练数据集显着不同的新情况。然而,强化学习对于这个问题很鲁邦,因为它在训练期间探索了所有相关场景。强化学习涵盖各种模型,包括基于价值的模型,例如深度Q网络(DQN),基于actor-critic的模型,例如深度确定性策略梯度(DDPG)和异步优势行动者批评家(A3C),最大熵模型,例如Soft Actor Critic(SAC),以及基于策略的优化方法,例如信任区域策略优化(TRPO)和近端策略优化(PPO)。
Liang展示了第一个有效的基于视觉的驱动管道的强化学习方法,其性能优于当时的模块化管道。他们的方法基于深度确定性策略梯度(DDPG),这是actor-critic算法的扩展版本。

最近,人机循环(HITL)方法在文献中引起了关注。这些方法的前提是专家论证为实现高回报政策提供了宝贵的指导。一些研究的重点是将人类专业知识融入到传统强化学习或IL 范式的训练过程中。EGPO就是一个这样的例子,它旨在开发一种专家指导的策略优化技术,其中专家策略监督学习代理。

Fig. 7: RL-based learning method for training the agent to drive optimally: (a) Illustrating the reinforcement learning expert [28] that maps the BEV to the low-level driving actions; the expert can also provide supervision to the imitation learning agent. (b) Human-in-the-loop learning [41] allows the agent to explore the environment, and in danger scenarios, the human expert takes over the control and provides the safe demonstration.
HACO允许智能体探索危险环境,同时确保训练安全。在这种方法中,人类专家可以干预并指导代理避免潜在的有害情况或不相关的行为(见图7(b))。一般来说,专家可以为模仿学习或强化学习提供高级别的监督。最初可以使用模仿学习来教授策略,然后使用强化学习来完善策略,这有助于减少强化学习所需的大量训练时间。
其他学习方法
明确设计具有部分组件的端到端系统的学习方法涵盖各种方法,包括多任务学习、面向目标的学习和SP-T3等特定技术。此外,像PPGeo这样的自监督学习框架利用未标记的驾驶视频来建模驾驶策略。这些方法旨在训练能够有效处理多个任务的模型,针对特定目标进行优化,并结合专门的技术来增强端到端系统的性能和功能。
05 学习从模拟器到真实的域适应
可以在虚拟引擎中构建大规模虚拟场景,从而更轻松地收集大量数据。然而,虚拟数据和现实世界数据之间仍然存在显着的领域差异,这给创建和实现虚拟数据集带来了挑战。通过利用领域适应原理,我们可以直接从模拟器中提取关键特征,并将从源领域学到的知识转移到由准确的现实世界数据组成的目标领域。
H-Divergence 框架通过对抗学习域分类器和检测器来解决视觉和实例级别的域差距。Zhang提出了一种模拟器-真实交互策略,利用源域和目标域之间的差异。作者创建了两个组件来协调全球和本地层面的差异,并确保它们之间的整体一致性。随后逼真的合成图像可用于训练端到端模型。
一些工作利用虚拟LiDAR数据。Sallab对来自CARLA的虚拟LiDAR点云进行学习,并利用CycleGAN将样式从虚拟域转移到真实的KITTI数据集。关于规划和决策差异,Pan提出了在具有现实框架的模拟环境中学习驾驶策略,然后再将其应用于现实世界。
06 安全性
确保端到端自动驾驶系统的安全是一项复杂的挑战。虽然这些系统具有高性能潜力,但为了维护整个管道的安全,一些考虑因素和方法至关重要。首先使用涵盖广泛场景(包括罕见和危急情况)的多样化、高质量数据来训练系统。[23]表明,针对关键场景的培训有助于系统学习稳健且安全的行为,并为其应对环境条件和潜在危险做好准备。这些场景包括十字路口处无保护的转弯、行人从遮挡区域出现、激进的变道以及其他安全启发法,如图 8(b) 和 (c) 所示。

Fig. 8: Demonstration of safe driving methods: (a) InterFuser [8] processes multisensorial information to detect adversarial events, which are then used by the controller to constrain driving actions within safe sets. (b) KING [6] improves collision avoidance using scenario generation. The image shows the ego vehicle (shown in red) maintaining a safe distance during a lane merge in the presence of an adversarial agent (shown in blue). (c) In the same context, the image illustrates the vehicle slowing down to avoid collision.
将安全约束和规则集成到端到端系统中是另一个重要方面。系统可以通过在学习或后处理系统输出期间纳入安全考虑因素来优先考虑安全行为。安全约束包括安全成本函数、避免不安全的操作和避免碰撞策略。Zeng等明确负责安全规划的成本量。为了避免不安全的操作,Zhang等消除不安全的航点,Shao等引入InterFuser(图8(a)),它仅约束安全集中的动作,并仅引导最安全的动作。上述约束确保系统在预定义的安全边界内运行。
实施额外的安全模块和测试机制(表 II、表 III)可增强系统的安全性。对系统行为的实时监控可以检测异常或安全操作偏差。Wu等提出了一种轨迹+控制模型,可以预测长范围内的安全轨迹。Hu等还采用目标规划器来确保安全。这些机制确保系统能够检测并响应异常或意外情况,从而降低发生事故或不安全行为的风险。
如表二所示,对抗打击方法被用于端到端驾驶测试,以评估输出控制信号的正确性。这些测试方法旨在识别漏洞并评估针对对手的稳健性。端到端测试表 (III) 确定给定场景内的正确控制决策。变质测试通过验证不同天气和照明条件下转向角度的一致性来解决预言机问题。它提供了一种可靠的方法来确保转向角保持稳定且不受这些因素的影响。差异测试通过比较同一场景的推理结果,揭示了不同 DNN 模型之间的不一致。如果模型产生不同的结果,则表明系统中存在意外行为和潜在问题。基于模型的预言机采用经过训练的概率模型来评估和预测真实场景中的潜在风险。通过监视环境,它可以识别系统可能无法充分处理的情况。


安全指标提供了评估自动驾驶系统性能的定量措施,并评估系统在安全方面的功能。碰撞时间 (TTC)、冲突指数 (CI)、碰撞潜在指数 (CPI)、反应时间 (TTR) 等一些指标可以提供各种方法的安全性能之间的额外客观比较并识别区域 需要改进的地方。安全指标对于监控和开发安全可靠的驾驶解决方案至关重要。表IV 提供了这些指标的详细描述。

07 可解释性
可解释性是指理解代理逻辑的能力,重点关注用户如何解释模型输入和输出之间的关系。它包含两个主要概念:可解释性,涉及解释的可理解性;完整性,涉及通过解释详尽地定义模型的行为。Cui等区分了对自动驾驶汽车的三种信心:透明度,指的是人预见和理解车辆操作的能力;技术能力,与了解车辆性能有关;情况管理,其中涉及用户可以随时重新获得车辆控制权的概念。根据哈斯皮尔等人的说法,当人类参与时,解释起着至关重要的作用,因为解释自动驾驶汽车行为的能力会显着影响消费者的信任,而这对于广泛接受这项技术至关重要。
关于模仿和强化学习方法正在进行大量研究,重点是提供模型行为解释的解释能力。为了描述事后解释方法,已经确定了两类(图 9):局部方法(VIII-A),它解释对特定动作实例的预测;全局方法(VIII-B),它解释 模型作为一个整体。

Fig. 9: Categorization of Explainability Approaches.
Local explanations
1)Post-hoc显着性方法:事后显着性技术试图解释像素的哪些部分对模型的输出影响最大。这些方法提供了一个显着性图,说明模型做出最重要决策的位置。
Post-hoc显着性方法主要关注驾驶架构的感知组件。这些局部预测被用作视觉注意力图,并使用线性组合与学习参数相结合来做出最终决策。虽然基于注意力的方法通常被认为可以提高神经网络的透明度,但应该注意的是,学习到的注意力权重可能与多个特征表现出弱相关性。在测量驾驶过程中的不同输入特征时,注意力权重可以提供准确的预测。总体而言,评估注意力机制的事后有效性具有挑战性,并且通常依赖于主观的人类评估。

Fig. 10: Explainability Methods: (a) PlanT [15] visualization showing the attention given to the agent in various scenarios. (b) Using InterFuser [8], failure cases can be visualized by integrating three RGB views and a predicted object density map. The orange boxes indicate objects that pose a collision risk to the ego-vehicle. The object density map offers predictions for the current traffic scene (t0) and future traffic scenes at 1-second (t1) and 2-second (t2) intervals.
2)反事实解释:显着性方法侧重于回答“哪里”的问题,识别对模型决策有影响的输入位置。相比之下,反事实解释通过寻找输入中改变模型预测的微小变化来解决“什么”问题。
由于输入空间由语义维度组成并且是可修改的,因此评估输入组件的因果关系很简单。Li等最近提出了一种用于识别风险对象的因果推理技术。语义输入提供了高级对象表示,使其比像素级表示更易于解释。
在端到端驱动中,转向、油门和制动驱动输出可以通过提供反事实解释的辅助输出来补充。Chitta等提出使用 A* 规划器的可解释的辅助输出。Shao等设计了一个系统,如图10(b)所示,它生成一个安全思维导图,在中间对象密度图的帮助下推断潜在的故障。
Global explanations
全局解释旨在通过描述模型所拥有的知识来提供对模型行为的整体理解。它们分为模型翻译(VIII-B1)和表示解释技术(VIII-B2),用于分析全局解释。
1)模型翻译:模型翻译的目标是将信息从原始模型转移到本质上可解释的不同模型。这涉及训练一个可解释的模型来模拟输入输出关系。最近的研究探索了将深度学习模型转化为决策树、基于规则的模型或因果模型。然而,这种方法的一个局限性是可解释的翻译模型与原始自动驾驶模型之间可能存在差异。
2)解释表示:解释表示旨在解释模型结构在不同尺度上捕获的信息。神经元的激活可以通过检查最大化其活动的输入模式来理解。例如,可以使用梯度上升或生成网络对输入进行采样。
08 评估
End-to-End系统的评估分为开环评估和闭环评估。使用真实世界的基准数据集(例如KITTI和 nuScenes)评估开环。它将系统的驾驶行为与专家的行为进行比较并测量偏差 MinADE、MinFDE、L2 误差和冲突率 [58] 等指标是表I中列出的一些评估指标。相比之下,闭环评估直接评估受控现实世界或受控现实世界中的系统。通过允许其独立驾驶并学习安全驾驶操作来模拟设置。
在端到端驾驶系统的开环评估中,系统的输入(例如相机图像或激光雷达数据)被提供给系统。所产生的输出(例如转向命令和车辆速度)将根据预定义的驾驶行为进行评估。开环评估中常用的评估指标包括衡量系统遵循期望轨迹或驾驶行为的能力,例如预测轨迹和实际轨迹之间的均方误差或系统保持在该轨迹内的时间百分比 所需轨迹的一定距离。其他评估指标也可用于评估系统在特定驾驶场景中的性能,例如系统导航交叉路口、处理障碍物或执行车道变换的能力。
最近的大多数端到端系统都是在闭环设置中进行评估的,例如LEADERBOARD和NOCRASH [79]。表V比较了 CARLA 公共排行榜上所有最先进的方法。CARLA 排行榜分析意环境中的自动驾驶系统。车辆的任务是完成一组指定的路线,其中包括意外穿越行人或突然变道等危险场景。排行榜衡量车辆在规定时间内在给定城镇路线上成功行驶的距离以及发生违规的次数。有几个指标可以让您全面了解驾驶系统,如下所述:
- 路线完成 (RC):测量车辆可以完成的距离的百分比;
- 违规分数/罚分(IS):是跟踪违规行为并汇总违规罚分的几何级数。车辆的起始分数为1.0,然后根据违规处罚进一步降低分数。它衡量客服人员开车不造成违规的频率;
- 驾驶分数(DS):是一个主要指标,计算为路线完成度与违规处罚的乘积。它衡量按每条路线的违规行为加权的路线完成率。
有评估违规行为的具体指标,每次违规发生时,每个指标都会应用惩罚系数。与行人的碰撞、与其他车辆的碰撞、与静态元素的碰撞、碰撞布局、红灯违规、停车标志违规和越野违规是使用的一些指标。
09 数据集和仿真
数据集
在端到端模型中,数据的质量和丰富性是模型训练的关键方面。训练数据不是使用不同的超参数,而是影响模型性能的最关键因素。输入模型的信息量决定了它产生的结果类型。我们根据传感器模式(包括摄像头、激光雷达、GNSS 和动力学)总结了自动驾驶数据集。数据集的内容包括城市驾驶、交通和不同的路况。天气条件也会影响模型的性能。一些数据集,例如 ApolloScape,捕获从晴天到下雪的所有天气条件。表六提供了详细信息。

仿真和工具集
端到端驾驶和学习管道的标准测试需要先进的软件模拟器来处理信息并为其各种功能得出结论。此类驾驶系统的试验成本高昂,而且在公共道路上进行测试受到严格限制。模拟环境有助于在道路测试之前训练特定的算法/模块。像Carla这样的模拟器可以根据实验要求灵活地模拟环境,包括天气条件、交通流量、道路代理等。模拟器在生成安全关键场景方面发挥着至关重要的作用,并有助于模型泛化以检测和预测 防止此类情况的发生。
表七比较了广泛使用的端到端驱动管道训练平台。MATLAB/Simulink用于各种设置;它包含高效的绘图函数,并且能够与其他软件(例如CarSim])进行联合仿真,从而简化了不同设置的创建。PreScan可以模拟现实世界的环境,包括天气条件,这是MATLAB和CarSim所缺乏的。它还支持MATLAB Simulink接口,使建模更加有效。Gazebo以其高通用性和与ROS的轻松连接而闻名。与CARLA和LGSVL模拟器相比,使用Gazebo创建模拟环境需要机械工作。CARLA和LGSVL提供高质量的模拟框架,需要GPU处理单元以适当的速度和帧速率运行。CARLA基于Unreal引擎构建,而LGSVL基于Unity游戏引擎。该API允许用户访问CARLA和LGSVL中的各种功能,从开发可定制的传感器到地图生成。LGSVL一般通过各种桥连接到驱动堆栈,而CARLA允许通过ROS和Autoware进行内置桥连接。

10 未来研究方向
- 1)学习鲁棒性:目前端到端自动驾驶的研究主要集中在强化学习和模仿学习方法。强化学习通过与模拟环境交互来训练智能体,而IL则向专家智能体学习,无需进行广泛的环境交互。然而IL中的分布变化和RL中的计算不稳定等挑战凸显了进一步改进的必要性。多任务学习也是一种令人印象深刻的方法,但需要在自动驾驶研究中进一步探索。
- 2)增强安全性:安全性是开发端到端自动驾驶系统的关键因素。确保车辆的行为安全并准确预测不确定行为是安全研究的关键方面。一个有效的系统应该能够处理各种驾驶情况,从而提供舒适可靠的交通。为了促进端到端方法的广泛采用,必须完善安全约束并提高其有效性。
- 3)提高模型可解释性:可解释性的缺乏对端到端驱动的发展提出了新的挑战。然而人们正在不断努力,通过设计和生成可解释的语义特征来解决这个问题。这些努力在性能和可解释性方面都显示出有希望的改进。尽管如此,设计新颖的方法来解释导致失败的模型操作并提供潜在的解决方案还需要进一步的进展。未来的研究还可以探索改进反馈机制的方法,让用户了解决策过程并增强对端到端驾驶系统可靠性的信心。
11 结论
在过去的几年里,由于与传统的模块化自动驾驶相比,端到端自动驾驶的设计简单,人们对它产生了浓厚的兴趣。在端到端驾驶研究呈指数级增长的推动下,我们首次对使用深度学习的端到端自动驾驶进行了全面调查。该调查论文不仅有助于理解端到端自动驾驶,而且可以作为该领域未来研究的指南。
我们开发了一种分类法,根据模式、学习和培训方法对研究进行分类。此外,我们还研究了利用领域适应方法来优化训练过程的潜力。此外,本文还介绍了一个包含开环和闭环评估的评估框架,可以对系统性能进行全面分析。为了促进该领域的进一步研究和开发,我们编制了公开可用的数据集和模拟器的汇总列表。本文还探讨了不同文章提出的有关安全性和可解释性的潜在解决方案。尽管端到端方法的性能令人印象深刻,但仍需要在安全性和可解释性方面继续探索和改进,以实现更广泛的技术接受。