一、引言
最近的ChatGPT(全称:Chat Generative Pre-trained Transformer )在各类社交媒体上风头无二,其是由OpenAI开发的一个人工智能聊天机器人程序,于2022年11月推出。该程序使用基于GPT-3.5架构的大型语言模型并通过强化学习进行训练,发布至今,OpenAI估值已涨至290亿美元,上线两个月后,用户数量达到1亿。再往前看2016年,人工智能已经初现走向成熟的端倪,这一年随着AlphaGo 击败人类顶尖围棋选手李世石、柯洁,我们真正见证了人工智能(AI)的巨大潜力,并开始期望在许多应用中使用更复杂,最先进的AI技术,包括无人驾驶汽车,医疗保健。如今,人工智能技术正在几乎每个行业中展示其优势。
但是,当我们回顾AI的发展时,不可回避的是AI的发展经历了几次起伏。人工智能会不会再下滑呢?什么时候出现?由于什么因素?当前公众对AI的兴趣部分是由大数据的可用性驱动的:2016年AlphaGo总共使用了30万场游戏作为训练数据,以取得出色的成绩。随着AlphaGo的成功,人们自然希望像AlphaGo这样的大数据驱动的AI将成为在我们生活的各个方面。但是,人们都很快意识到现实世界中的情况有些令人失望:

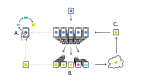
图 1:人工智能发展挑战
- 现实中,我们的数据质量是非常有限甚至是差的,比如聊天数据中有很多噪音。
- 数据标签的收集是比较困难的,很多场景中的数据是没有标签的。
- 数据是孤岛的,这也是最重要一点,每家应用的数据不一样,比如主营社交软件的公司用的是社交属性数据,主营电商的公司用的是电商交易数据,银行用的是信用数据,都是分散来应用的。现实中,如何进行跨组织间的数据合作,会有很大的挑战。
- 同时隐私保护政策变严格,这是重要的第二点,这些条例使得很多机构不能够把用户的数据收集起来、集中起来做分析,数据被条例保护在用户本地了。
数据是人工智能时代的石油,但是由于监管法规和商业机密等因素限制,“数据孤岛”现象越来越明显。同时随着政策法规的逐渐完善和公众隐私保护意识加强,如何在保护数据隐私的前提下实现行业协作和协同治理,如何破解“数据孤岛”和“数据隐私保护”的两难困境,成为了当下人工智能技术行业应用中亟待解决的问题。
二、联邦学习概述
2.1 “数据隐私保护”与“数据孤岛”困境
数据孤岛和数据隐私保护的两难困境:一是来自于人工智能技术本身的特点,需要海量数据作为基础;二是来自于世界范围内对数据隐私和安全的日益重视。
人工智能技术尤其是深度学习依赖于模型、 算法,更依辍于通过海量数据进行模型训练。从而不断改进,仅依靠某一机构所掌握的数据,无法实现技术的快速突破。理想状态是在数据之间建立广 泛连接,形成合力,创造更大价值。而现实情况是:有效数据往往难以获取或以“数据孤岛”的形式呈现。公司之间的数据共享需要用户的授权,而许多用户倾向于拒绝数据共享;即便一个公司内部,数据壁垒也不易打通;互联网巨头的存在,使得少数公司袭断大量数据。这些因素都会导致数据孤岛,难以创造出“1+1>2”的数据价值。
全球范围内对数据隐私和安全的重视带来了更大挑战,这个挑战导致大部分企业只拥用小数据,加剧了数据孤岛现象的产生。欧盟出台了首个关于数据隐私保护的法案《通用数据保护条例》 (General Data Protection Regulation, GDPR),明确了对数据隐私保护的若干规定。和以往的行业规范不同,这是一个真正可以执行的法律,并且条款非常清晰严格。例如,经营者要允许用户来表达数据“被遗忘”的愿望,即“我不希望你记住我过去的数据,并希望从现在起你不要利用我的数据来建模”。与此同时,违背GDPR的后果也非常严重,罚款可以高达被罚机构的全球营收的4%。Facebook 和Google已经成为基于这个法案的第1批被告。而中国在2017年起实施的《中华人民共和国网络安全法》和《中华人民共和国民法总则》中也指出:“网络运营者不得泄露、篡改、毁坏其收集的个人信息,并且与第三方进行数据交易时需确保拟定的合同明确约定拟交易数据的范围和数据保护义务”。这意味着对于用户数据的收集必须公开、透明,企业、机构之间在没有用户授权的情况下不能交换数据。
虽然有明确的法律法规并且在全球范围内达成了广泛共识,但由于技术等因素的限制,实际应用中,数据隐私保护仍然是难题。收集数据的一方往往不是使用数据的一方,例如A方收集数据,转移到B方清洗,再转移到C方建模,最后将模型卖给D方使用。这种数据在实体间转移、交换和交易的形式违反了相关法律法规,并可能受到严厉的惩罚。如何在保护数据隐私的前提下,从技术上解决数据孤岛的问题,在隐私安全和监管要求下,如何让AI系统更加高效、准确地共同使用各自的数据,能够在小数据(很少的样本和特征)和弱监督(有很少的标注)的条件下做更好的模型,人们提出联邦学习的解决方案,并且不断探索其在具休行业场景下的应用。
2.2 联邦学习定义
数学定义:
定义N个数据持有者{F1, F2, F3..., Fn},他们都希望通过整合各自的数据 {D1, D2, D3..., Dn}来训练机器学习模型。传统的方法是将所有数据放在一起使用 D=D1 U D2 U...U Dn来训练出一个模型 MSUM,而联邦系统是一个学习过程,在此过程中,所有数据持有者协作训练模型 MFED,并且对任意一个数据持有者 Fi 不会将其独享的数据 Di 暴露给其他人。除此之外,模型 MFED 的准确性定义为 VFED 其应该是非常接近于将数据集中放一起训练的模型 MSUM 的准确度 VSUM. 用公式定义,让 δ 为非负实数,如果
| VFED - VSUM |< δ
则称该联邦学习算法有 δ 的精度损失。

图 2.1:联邦学习模型组成
在Peter等在综述【1】中给出的上图定义中可以清晰看出,联邦学习指的是在满足隐私保护和数据安全的前提下设计一个机器学习框架,使得其中许多客户端(例如移动设备或整个组织)在中央服务器(例如服务提供商)的协调下共同训练模型,同时保持训练数据的去中心化及分散性,实现在不暴露数据的情况下分析和学习多个数据拥有者的数据。同时从定义中可以为其总结四大特征:
- 数据隔离:联邦学习的整套机制在合作过程中,数据不会传递到外部,数据保留在本地,避免数据泄露,满足用户隐私保护和数据安全的需求。
- 无损:通过联邦学习分散建模的效果和把数据合集中在一起建模的效果对比,几乎是无损的。
- 共同获益:能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长。
- 对等:在联邦学习的框架下,各参与者地位对等,能够实现公平合作,不存在一方主导另一方的情况。
2.3 联邦学习隐私性
隐私是联邦学习的基本属性之一,这需要安全模型和分析以提供有意义的隐私保证。在本节中,将简要介绍和比较联邦学习的不同隐私技术,并确定方法和潜力防止间接泄漏的挑战。
多方安全计算(Secure Multi-party Computation, SMC):
SMC安全模型自然涉及多方参与,并在定义良好的模拟框架中提供安全证明,保证完全零知识,即每一方除了自己的输入和输出外一无所知。零知识是非常可取的,但是这种所需的属性通常需要复杂的计算协议并且可能无法有效地实现。在某些情况下,如果提供安全保证,部分知识披露可能被认为是可以接受的。可以在较低的安全要求下用 SMC 构建安全模型以换取效率。
差分隐私计算(Differential Privacy):
使用差分隐私或 k-匿名算法来保护数据隐私 。差分隐私计算、k-匿名计算和演化计算的方法包括在数据中加入噪声,或者使用泛化方法来掩盖某些敏感属性,直到第三方无法区分个体,从而使数据无法被敌手恢复,进而起到保护用户隐私的作用。
同态加密计算(Homomorphic Encryption):
在机器学习过程中,还采用同态加密通过加密机制下的参数交换来保护用户数据隐私。与差分隐私保护不同,数据和模型本身不传输,也无法通过对方的数据进行猜测。因此,原始数据层面泄露的可能性很小。最近的工作采用同态加密来集中和训练云上的数据。在实践中,加法同态加密被广泛使用,并且需要进行多项式逼近来评估机器学习算法中的非线性函数,从而导致准确性和隐私之间的权衡。
2.4 联邦学习分类
在实际应用中,因为孤岛数据具有不同的分布特点,所以联邦学习也可分为:横向联邦学习、纵向联邦学习、联邦迁移学习3大类:

图 2.2:联邦学习分类
如果要对用户行为建立预测模型,需要有一部分的特征,即原始特征,叫作 X ,例如用户特征, 也必须要有标签数据,即期望获得的答案,叫作 Y。比如,在金融领域,标签 Y 是需要被预测的用户信用;在营销领域,标签 Y 是用户的购买愿望;在教育领域,则是学生掌握知识的程度等.用户特征 X 加标签 Y 构成了完整的训练数据 (X,Y)。但是,在现实中,往往会遇到这种情况:各个数据集的用户不完全相同,或用户特征不完全相同。具体而言,以包含2个数据拥有方的联邦学习为例,数据分布可以分为3种情况:
- 2个数据集的用户特征重叠部分较大,而用户重叠部分较小,如图2.2中(a)所示;
- 2个数据集的用户重叠部分较大,而用户特征重叠部分较小,如图2.2中(b)所示;
- 2个数据集的用户与用户特征重叠部分都比较小,如图2.2中(c)所示。
为了应对以上3种数据分布情况,我们把联邦学习分为横向联邦学习、纵向联邦学习与联邦迁移学习。
2.5 联邦学习步骤
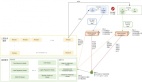
一般一个联邦学习模型主要有联邦学习系统架构和加密模型训练两大部分组成[2]。假设现有两个数据拥有方(组织A和组织B)希望联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,组织B还拥有模型需要预测的标签数据。出于数据隐私和安全考虑,组织A和组织B无法直接进行数据交换。此时,可使用联邦学习系统建立模型,系统架构由2部分构成,如图2.3所示:

图 2.3:联邦学习系统架构
整个进行的步骤可以分为:
(1)加密样本对齐:由于2家组织的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在组织A和组织B不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户,以便联合这些用户的特征进行建模。
(2)加密模型训练:在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训 练过程中数据的保密性,需要借助第三方协作者C进行加密训练。以线性回归模型为例,训练过程可分为以下4步(如图(b)所示):
- 协作者C把公钥分发给模型A和模型B,用以对训练过程中需要交换的数据进行加密。
- 对齐数据A和对齐数据B之间以加密形式交互用于计算梯度的中间结果。
- 对齐数据A和对齐数据B分别基于加密的梯度值进行计算,同时对齐数据B根据其标签数据计算损失,并把这些结果汇总给协作者C。协作者C通过汇总结果计算总梯度并将其解密。
- 协作者C将解密后的梯度分别回传给模型A和模型B;模型A和模型B根据梯度更新各自模型的参数。迭代上述步骤直至损失函数收敛,这样就完成整个训练过程。在样本对齐及模型训练过程中,组织A和组织B各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。
(3)效果激励:联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供数据多的机构会看到模型的效果也更好[3],这体现在对自己机构的贡献和对他人的贡献。这些模型会向各个机构反馈其在联邦机制上的效果,并继续激励更多机构加入这一数据联邦。
以上3个步骤的实施,既考虑了在多个机构间共同建模的隐私保护和效果,又考虑了如何奖励贡献数据多的机构,以一个共识机制来实现,所以,联邦学习是一个“闭环”的学习机制。
三、 总结展望
3.1 总结
联邦学习作为隐私增强计算与人工智能相结合的新型技术范式,成为了解决数据安全与开放共享矛盾的一个重要技术路径。联邦学习中,用户可以在自己的终端使用本地数据对模型进行训练,并将模型的加密参数进行上传汇总,将不同的模型更新进行融合,优化预测模型。
2022年是联邦学习的技术分水岭——从联邦学习到可信联邦学习。针对近两年来隐私计算和联邦学习发展和应用中面临的安全、效率等挑战,“可信联邦学习”被提出,这一范式将隐私保护、模型性能、算法效率作为核心,共同构成了更加安全可信的联邦学习。
3.2 落地展望
目前,联邦学习已经开始了在行业领域的落地探索,在不同的行业有多样化的应用场景和落地形态,未来在一些领域可能有以下广阔前景[4-10]:
在手机领域,近年来,移动设备配备了越来越先进的传感和计算能力。再加上深度学习 (Deep Learning,DL) 的进步,这为有意义的应用开辟了无数可能性,例如,用于智能车载和辅助驾驶。传统的基于云的机器学习 (Machine Learning,ML) 方法需要将数据集中在云服务器或数据中心。然而,这会导致与不可接受的延迟和通信效率低下相关的关键问题。为此,有人提出了移动边缘计算 (Mobile Edge Computing,MEC),以使产生数据的边缘设备变得更加智能。然而,传统的移动边缘网络 ML 支持技术仍然需要与外部各方共享个人数据,例如边缘服务器。最近,鉴于越来越严格的数据隐私立法和日益增长的隐私问题,联邦学习(FL)的概念被引入。在 FL 中,终端设备使用其本地数据来训练服务器所需的 ML 模型。然后终端设备将模型更新而不是原始数据发送到服务器进行聚合,这将进一步加速产生数据的终端设备变得更加智能;
在风控领域,多家金融机构联合建模的风控模型能更准确地识别信贷风险,联合反欺诈。多家银行建立的联邦反洗钱模型,能解决该领域样本少、数据质量低的问题。
在智慧零售领域,联邦学习能有效提升信息和资源匹配的效率。例如,银行拥有用户购买能力的特征,社交平台拥有用户个人偏好特征,电商平台则拥有产品特点的特征,传统的机器学习模型无法直接在异构数据上进行学习,联邦学习却能在保护三方数据隐私的基础上进行联合建模,为用户提供更精准的产品推荐等服务,从而打破数据壁垒,构建跨领域合作。
在医疗健康领域,联邦学习对于提升医疗行业协作水平更具有突出意义。在推进智慧医疗的过程中,病症、病理报告、检测结果等病人隐私数据常常分散在多家医院、诊所等跨区域、不同类型的医疗机构,联邦学习使机构间可以跨地域协作而数据不出本地,多方合作建立的预测模型能够更准确地预测痛症、基因疾病等疑难病。如果所有的医疗机构能建立一个联邦学习联盟,或许可以使人类的医疗卫生事业迈上一个全新的台阶。