译者 | 李睿
审校 | 重楼
多年来,在试图使可观察性计划取得成功的过程中,许多企业犯了一些常见的错误。然而,这些企业的失误中最关键和最根本的问题是对技术和工具本身的不可抗拒的迷恋。
这应该让人感到不意外。许多“让我们添加可观察性平台X”的项目在开始时通常都是大张旗鼓,但其方向感非常模糊,并且成功的标准也非常混乱。对于有效的可观察性可以做些什么来帮助开发人员更好地工作,许多供应商和预言者对于这一愿景的宣传却令人怀疑地缺失了。开发人员需要问问自己:有多少次发现自己会把目光从集成开发环境(IDE)中的代码上移开,发现可以从执行数据中学到什么?
不要误解,开发人员要相信可观察性在软件开发中可以发挥重要作用。OpenTelemetry发挥了巨大的作用,可以清楚地看到它如何帮助开发人员编写更好的代码,引入新的范例,并加快开发周期。它可以启发开发人员提出他们甚至还没有考虑到的问题。然而,无论人们在网上看到什么,其重点似乎仍然是可观察性本身,如何启用它,以及如何开始。尽管有着炫酷图形的仪表板非常棒,但许多开发团队都不知道该从哪里入手。
本文将讨论一个更有趣的话题:对于使用可观察性的开发者来说,成功是什么样子的?开发团队如何期望使用丰富的代码运行时数据更好地编码和发布?更重要的是,现在有哪些可观察性可以告诉开发人员关于代码的事情,以及它如何帮助开发人员改进?可以通过具体的代码示例来了解如何利用可观察性作为编码实践。
超越监控:缩短开发过程中的反馈循环
可观察性最大的希望在于提供真实和客观的反馈,不受单元测试的一些偏差和偏见的影响。想象一下,当开发人员还在处理代码更改时,就会收到有关任何回归或问题的警报。或者,始终了解代码的哪些部分在生产中实际使用,并根据集成测试结果轻松识别需要注意的薄弱环节。
这可能是开发人员可观察性的真正潜力,而不是作为“监视”解决方案的传统角色。监视器和警报至关重要,但不幸的是,它们的重点始终是报告已经发生的问题。也许是因为该技术主要由DevOps/SRE/IT团队使用,他们主要关心生产的稳定性。
本文作者表示,有一次在发布一个产品的阶段,他和团队中的其他开发人员感觉他们的作用更像是消防队而不是开发团队,他开玩笑地将匆忙修复漏洞称为BDD——不是行为驱动设计,而是漏洞驱动开发。然而,这种描述并非完全不准确。开发人员没有积极主动地改进代码,而是极其被动地追逐一个又一个问题,这很快就变得不可持续。
例举更实际的例子
为了说明开发人员如何利用可观察性来改进的开发周期,在此例举一个现实场景的更实际的例子:团队中的高级开发人员Bob被要求向Spring PetClinic示例添加一些功能。跟踪宠物的疫苗接种记录似乎非常重要,Bob被要求与外部数据源集成以实现这一目标。对于最初的最小可行产品(MVP),Bob为此创建一个功能分支,并继续实现一些新的功能。
在阅读了许多关于如何从Java应用程序中收集可观察性数据的教程之后,Bob在后台运行了几个OSS和免费工具来帮助他完成任务。这篇文章并不会详细介绍如何设置整个堆栈(因为它也有广泛的文档记录)。但是,可以依docker_compose文件的形式找到整个堆栈。
Bob的基本可观测性堆栈:
- 用于跟踪的OpenTelemetry;他还在本地运行了一个OTEL收集器容器,将数据路由到各种工具。
- 用于显示跟踪的Jaeger。
- 用于采集指标的Micrometer。
- 用于保存矩阵的Prometheus和用于可视化它们的开源版本Grafana。
需要注意的是,要开始使用OTEL收集代码数据,Bob不需要进行任何代码更改。在本地运行时,他可以安全地使用OTEL代理。在他的例子中,他只是在IDE的运行配置中引用代理,以便在本地运行/调试时可以引用代理。他还添加了一个docker-compose.override文件,用于使用docker/Podman启动应用程序(这也不需要更改源docker-compose文件)。
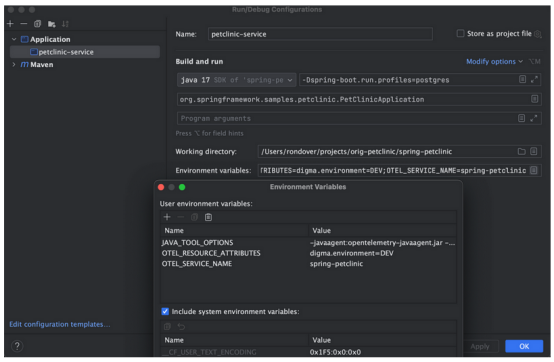
在一切就绪并运行之后,Bob创建了一个新的功能分支,并开始开发新功能。
疫苗API外观组件
非常幸运的是,有人已经编写了一个Spring组件来与另一个模块的模拟API进行通信。Bob的工作很简单:将组件注入PetController,并在添加宠物时使用它检索数据。该组件非常简单,使用OKHttp库实现一个基本的REST调用,以获取JSON形式的数据。
Java
@WithSpan
public VaccinnationRecord[] AllVaccines() throws JSONException, IOException {
var vaccineListString = MakeHttpCall(VACCINES_RECORDS_URL);
JSONArray jArr = new JSONArray(vaccineListString);
var vaccinnationRecords =
new ArrayList<VaccinnationRecord>();
for (int i = 0; i < jArr.length(); i++) {
VaccinnationRecord record = parseVaccinationRecord(jArr.getJSONObject(i));
vaccinnationRecords.add(record);
}
return vaccinnationRecords.toArray(VaccinnationRecord[]::new);
}
@WithSpan
public VaccinnationRecord VaccineRecord(int vaccinationRecordId) throws JSONException, IOException {
var idUrl = VACCINES_RECORDS_URL + "/" + vaccinationRecordId;
var vaccineListString = MakeHttpCall(idUrl);
JSONObject vaccineJson = new JSONObject(vaccineListString);
return parseVaccinationRecord(vaccineJson);
} 更新宠物模型
接下来,为了保存疫苗接种数据,而不是每次都检索它,必须更新模型和数据库结构。这涉及到很多样板文件,但为了保存每只宠物的疫苗接种信息,这是必要的措施。Bob适时地添加了一个新表,对类中的关系进行建模,还更新了DDL脚本。
Java
@Entity
@Table(name = "pet_vaccines")
public class PetVaccine extends BaseEntity {
@Column(name = "vaccine_date")
@DateTimeFormat(pattern = "yyyy-MM-dd")
private LocalDate date;
/**
* Creates a new instance of Visit for the current date
*/
public PetVaccine() {
}
public LocalDate getDate() {
return this.date;
}
public void setDate(LocalDate date) {
this.date = date;
}
}添加用于检索和更新新的宠物接种日期字段的域服务
遵循最佳实践,Bob创建了一个简单的域服务,该服务将被注入PetController中。新服务编排域逻辑,以便从外部API检索新宠物的疫苗记录,并用最新日期更新模型。不幸的是,这也是Bob犯了几个错误的地方,其中一些错误与facade抽象的泄漏有关,这掩盖了成本昂贵的HTTP调用。Bob也没有注意到很多逻辑是多余的。
Java
@Component
public class PetVaccinationStatusService {
@Autowired
private PetVaccinationService adapter;
public void UpdateVaccinationStatus(Pet[] pets){
for (Pet pet: pets){
try {
var vaccinationRecords = this.adapter.AllVaccines();
for (VaccinnationRecord record : vaccinationRecords){
var recordInfo = this.adapter.VaccineRecord(record.recordId());
if (recordInfo.petId()==pet.getId()){
PetVaccine petVaccine = new PetVaccine();
petVaccine.setDate(recordInfo.vaccineDate());
pet.addVaccine(petVaccine);
}
}
} catch (JSONException |IOException e) {
//Fail silently
Span.current().recordException(e);
}
}
}
}更新视图模板
最后,Bob添加了一个新字段,用于指示宠物疫苗是否过期。
HTML
..
<table class="table table-striped" th:object="${owner}">
<tr>
<th>Name</th>
<td><b th:text="*{firstName + ' ' + lastName}"></b></td>
</tr>
<tr>
<th>Address</th>
<td th:text="*{address}"></td>
</tr>
<tr>
<th>City</th>
<td th:text="*{city}"></td>
</tr>
<tr>
<th>Telephone</th>
<td th:text="*{telephone}"></td>
</tr>
<tr>
<th>Needs Vaccine</th>
<td th:text="*{isVaccineExpired()}"></td>
</tr>
</table>
...就是这样! 更改已准备就绪。Bob甚至编写了一些测试,他对快速的进展感到满意,并对本地测试时没有发生意外的代码充满信心,他转向收集的运行时数据,看看它能揭示他的更改。他决定扩展“完成”的定义,并花费额外的精力来检查与他的更改相关的数据。
使用可观察性
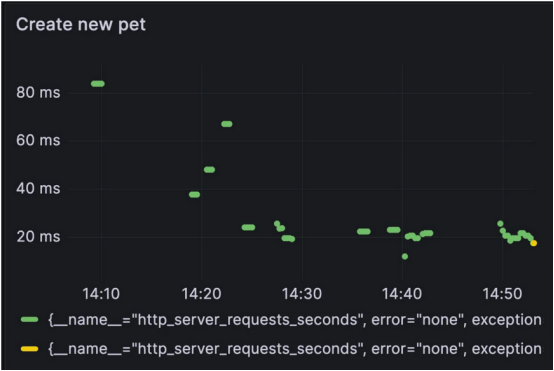
首先,参考某种基准是很重要的。有两个API操作受到了更改的影响,Bob希望了解更改之前和之后它们是如何执行的。作为可观察性设置的一部分,Bob还配置了Micrometer和Actuator,以提供有关API的有用指标。在这个案例中,这些可以通过执行器URL直接访问http://localhost:8082/actuator/metrics。然而,为了更好的可视化和更多的绘图选项,Bob将在他的堆栈中使用本地运行的Prometheus和Grafana OSS。
查看一些常见的Grafana仪表板,令人惊讶的是,没有用于跟踪API响应时间的默认图表。也许是因为大多数仪表板都与Ops相关,关注CPU/内存和堆栈大小,而不是日常开发人员的见解。幸运的是,使用Actuator度量很容易配置这样的仪表板。可以使用以下查询创建一个以创建新宠物的API为重点的图表:
HTTP
1 http_server_requests_seconds{uri="/owners/{ownerId}/pets/new", quantile="0.5", method="POST", outcome="REDIRECTION"} != 0
2然后可以在代码更改之前和之后检查图。
代码更改之前:
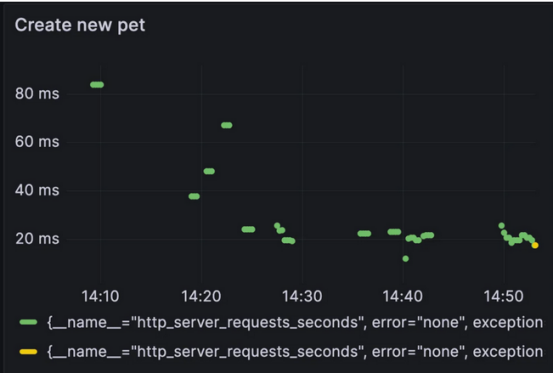
代码更改之后:
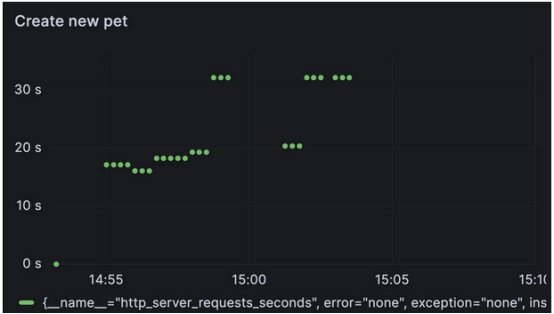
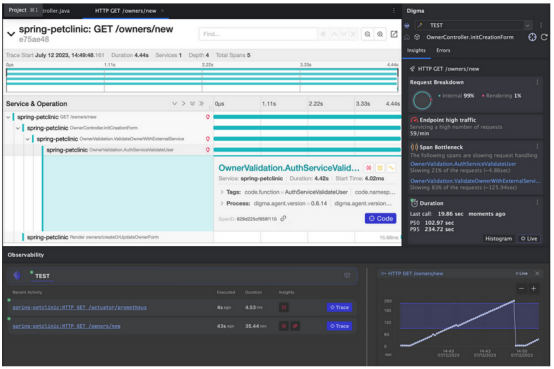
毫无疑问,这些更改导致了严重的性能问题。可以通过查看指标立即发现问题,但跟踪可以揭示更多关于根本原因和潜在问题的信息。现在是调用Jaeger的时候了,这是可观察性堆栈的另一个组件。Jaeger习惯于可视化捕获的跟踪,并为Bob提供了一个机会,让他在忙于添加更多逻辑和功能的同时,调查他的代码在做什么:
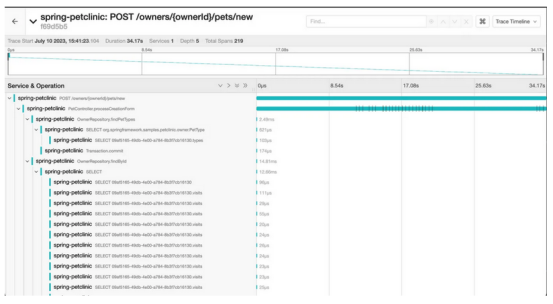
因此,在不添加单个断点的情况下,已经可以在这个请求中了解到许多关于这一代码的内容。到目前为止,Bob还完全没有注意到这些信息。虽然他在尝试新请求时确实注意到了一些延迟,但他并没有太在意。也许外部API太慢了?既然他已经访问了跟踪,他就可以重新审视引入的代码了。
精选丰富的语句
第一个突出的问题是作为findById存储库方法的一部分触发的许多SQL语句。Spring Data会自动检测到这一点,并提供一些关于正在发生的事情的场景。更仔细地检查查询会发现一个熟悉的Hibernate陷阱:
看起来访问关系是通过通常称为N+1选择的方式为每个宠物获取的。有趣的是,这个问题似乎是PetClinic应用程序特有的,而且似乎早于Bob的更改。实际上,虽然这会导致一些放缓,但它并不像其他一些问题那样重要,这一点在Bob进一步检查跟踪时变得明显。
HTTP请求聊天
性能回归的真正原因似乎与Bob的误解有关,可能是由于VaccineServiceFacade方法的命名不明确。他似乎不太清楚,每次调用VaccineRecord函数时在后台执行API调用。使用更好的命名约定可以缓解这种抽象漏洞,强调这实际上是长时间同步操作的执行。

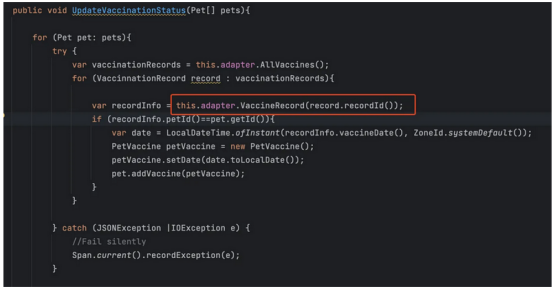
隐藏的错误
HTTP请求中还发生了其他事情。当向下滚动请求列表时,Bob注意到其中一些请求以错误结束,然后在尝试序列化不存在的响应时出现异常。基于HTTP错误代码的根本原因与速率限制或节流或外部API有关。这个问题可以通过优化调用的数量来暂时解决,但是随着越来越多的用户开始同时使用这个组件,这个问题可能会重新出现。此外,这段代码中的异常处理肯定是错误的,也许需要一种重试机制。
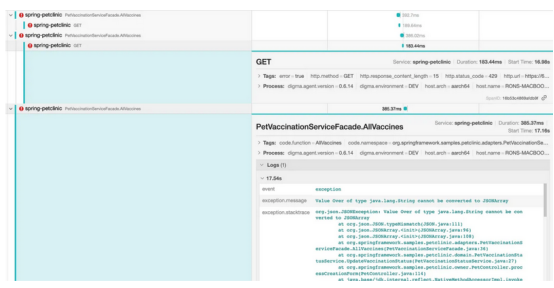
就在Bob开始纠正通过检查可观测性工件发现的许多问题之前,他决定快速查看他修改的另一个API。在这种情况下,性能似乎没有显著下降,但是检查跟踪仍然发现至少有一个问题需要修复。
将会出现哪些问题?
数据中还可以识别出其他问题,但是回顾一下场景,考虑一下如果Bob在合并更改之前没有对其进行分析,会发生什么情况:代码最终被部署。有些问题在CR或后期测试阶段被发现,导致更多的更改、额外的延迟和痛苦的合并,因为在此期间会出现更多的更改。其他问题也会转移到生产中,导致进一步的问题:延迟发布、匆忙修复、增加团队的焦虑和沮丧等等。毫无疑问,可以发现缩短反馈循环有很多好处。
胜利了吗?不完全是
在这个有点幼稚的例子中,能够演示如何简单地打开OTEL并通过一些OSS工具流式传输数据,有可能为Bob和其他开发人员提供额外的保护。然而,现实情况是,Bob的团队很可能无法以可持续的方式继续应用此类反馈。之所以会出现这种情况,有几个关键原因:
(1)不连续的人工过程:整个实验依赖于Bob的奉献精神、纪律和意志来仔细检查他的代码。随着释放压力的增加,他这么做的可能性越来越小。特别是如果在相当多的情况下,他将花费时间调查数据而没有提出任何重要的提示。与测试类似,除非它是连续的和自动的,否则它可能不会大规模地发生。
(2)专家需求:如上所述,这个例子在强调一些明确的场景时有些动作。在现实中,如果没有统计学、回归甚至基本的机器学习知识,以这种方式处理数据以理解代码更改的影响是非常困难的。以研究的第一个图为例,即“之前”状态。这些值之间的差异是否代表侥幸、某种上升成本或其他什么?
(3)场景切换和工具过载——切换场景很难。为了使这种编程范例能够工作,它必须是工程团队可以拥有的解决方案。它不可能是开发人员需要掌握并知道如何正确阅读的一堆指示板和工具。而需要的认知努力减少得越多,这些信息就越有可能被使用。

未来是持续的反馈
持续反馈是一种新的开发实践,旨在弥合已经确定的差距:拥有大量易于收集的关于代码运行时的数据,但需要人工工作、专业知识和时间来处理成实际和可操作的提示。有三个要素可以使其发挥作用:持续管道(反向持续集成管道)、集成工具和自动化数据分析的机器学习/数据科学。
注:本文作者表示,作为Digma的构建者,这是他创建的一个免费的持续反馈插件,因为这个无法解释的鸿沟阻止开发人员使用代码数据,这让他感到非常沮丧。他不止一次遇到“Bob”的情况,所有的信息都在公开的地方。它可以在调试/测试数据中找到,甚至可以在关于代码的生产数据中找到,只是没有人会或无法检查它。
这里设想的是流水线自动化,它可以发现Bob最终发现的所有不同的问题,并使其持续-只是正常开发周期的一部分。实际上,从等式中删除了整个OTEL配置、样板文件和工具。将“打开”所需的工作减少到一个简单的按钮切换。通过这种方式,整个项目现在只需要Bob做两件事——启用可观察性,并运行他的代码。这意味着更多的开发人员将能够开始探索代码运行时数据的潜力,而不仅仅是像Bob这样的顽固派。
启用了可观察性收集之后,以下是Bob在调试和本地运行时使用Digma插件时看到的IDE视图:
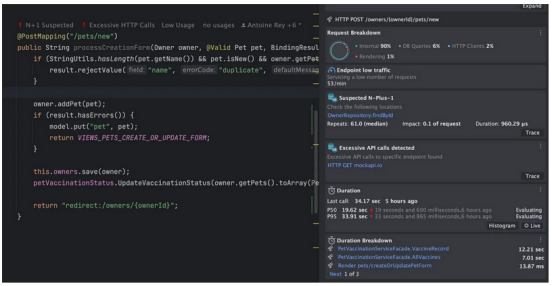
从视图中的会话反模式、N+1查询、检测速度变慢到隐藏错误,所有这些都成为了开发人员视图的一部分。当Bob继续编码、运行和调试时,它会不断地从收集的大量数据中解锁和破译。
通过这种方式,类似于测试,最终可以使可观察性透明——不需要有意识的努力。就像管道一样,可观察性的作用应该是融入背景。不管数据是如何收集的,也不管它是OTEL还是其他技术。更重要的是扭转了这个过程。Bob没有在与代码相关的指标和跟踪中搜索问题,而是从查看代码问题开始,这些代码问题本身包含到相关指标和跟踪的链接,以便进行进一步研究。
在考虑持续反馈时,最让人大开眼界的方法就是把它关掉。知道所有的问题仍然存在,除了完全看不见之外,这让人抓狂,这感觉就像在黑暗中编码。
许多开发人员评论说,与采用测试类似,转换部分是技术上的,部分是文化上的。谁知道如果用基于证据的指标来检验它们,会有什么编码恐怖事件出现,或者会有多少假设被推翻?也许有些人更喜欢在黑暗中编码?
在作者看来,它只会给代码库带来问题:技术债务提供更多的形式和方法。了解延迟代码更改的差距、影响和系统范围的后果,将有望帮助推动更改,并消除许多企业所遭受的一些前瞻性偏见。
还有更多的例子和细微差别可以作为未来博客文章的素材,这里几乎没有触及使用CI/Prod数据的主题,这可能会产生巨大的影响。
原文标题:Effective Coding With Java Observability,作者:Roni Dover