我们正在目睹人工智能大厦的快速搭建,越来越多的算力奠定了大厦地基,大模型加快了大厦的建造速度,具身智能开始成为新的研究热门 —— 大厦的功能性将会得到完备。
具备自主操作行为的移动操作机器人(mobile manipulators)无疑是具身智能(embodied AI)的一个绝佳代表:它集机器人的多模态自主感知、自主决策、轨迹生成、鲁棒控制以及灵活本体于一身,为机器人以及具身智能领域的研究员、工程师提出了诸多令人兴奋的挑战点。比如:当我们想要让一台机器 “人” 进入家庭帮助我们做家务,它如何结合各种传感信息自主生成操作轨迹?如何在操作的过程中保证不损坏家具和自己?
针对移动操作机器人在真实场景操作过程中的自主性和安全性问题,Bytedance Research 团队提出了一种新的方法:MOMA-Force。该方法可帮助移动操作机器人自主、安全地完成多种存在接触约束的操作任务(例如开洗衣机门、推拉抽屉)。
 该研究工作在模仿学习的背景下解决了真实物理世界移动操作任务中由不确定性和高维运动学引起的挑战性问题,提出了一种有效的视力觉模仿学习方法以解决复杂的接触移动操作任务。在六个接触约束的移动操作任务上进行了系统的真实机器人实验:在真实家庭环境中,MOMA-Force 在任务成功率方面明显优于基线方法(平均成功率 73.3%,而最佳基线方法仅实现了 45.0%)。此外,与没有力学习的基线方法相比,平均绝对接触力、力矩以及他们的平均方差均大幅减小,表明机器人与物体之间的接触更安全、更稳定。
该研究工作在模仿学习的背景下解决了真实物理世界移动操作任务中由不确定性和高维运动学引起的挑战性问题,提出了一种有效的视力觉模仿学习方法以解决复杂的接触移动操作任务。在六个接触约束的移动操作任务上进行了系统的真实机器人实验:在真实家庭环境中,MOMA-Force 在任务成功率方面明显优于基线方法(平均成功率 73.3%,而最佳基线方法仅实现了 45.0%)。此外,与没有力学习的基线方法相比,平均绝对接触力、力矩以及他们的平均方差均大幅减小,表明机器人与物体之间的接触更安全、更稳定。

- 项目主页:https://visual-force-imitation.github.io/
- 论文地址:https://arxiv.org/abs/2308.03624
方法
训练神经网络能够以端到端的方式生成动作,但由于动作精度和对噪声响应的低鲁棒性,导致难以应用于真实物理世界。另一方面,基于经典控制的方法可以增强系统的鲁棒性,但需要进行大量繁琐的参数调校。为了解决这些挑战,MOMA-Force 融合了用于视觉感知的表示学习(Representation Learning)、复杂运动轨迹生成的模仿学习(Imitation Learning)以及阻抗全身控制(Admittance Whole Body Control),以实现系统的鲁棒性和可控性。
MOMA-Force 的流程原理可以简单描述为:
- 专家示教数据中的 RGB 观测图像通过视觉编码器(visual encoder)转换为表示向量 Ze。当机器人在实时运行过程中,末端操作器的 RGB 观测图像通过相同的视觉编码器转换为表示向量 Zt。
- 通过从专家数据 Ze 中检索匹配出与当前实际观测表示 Zt 最相似的表示索引 i,并抽取出索引 i 对应的专家运动行为(机器人末端位置姿态)、夹爪开闭行为、力和力矩来作为当前时刻机器人的局部行为目标。
- 通过感知末端操作器当前所受到的接触力的大小、目标力的大小以及目标末端位姿,通过导纳全身控制(Admittance Whole Body Control)生成机械臂关节和底盘轮速控制信号驱动机器人平稳、安全地跟踪目标轨迹点完成任务。
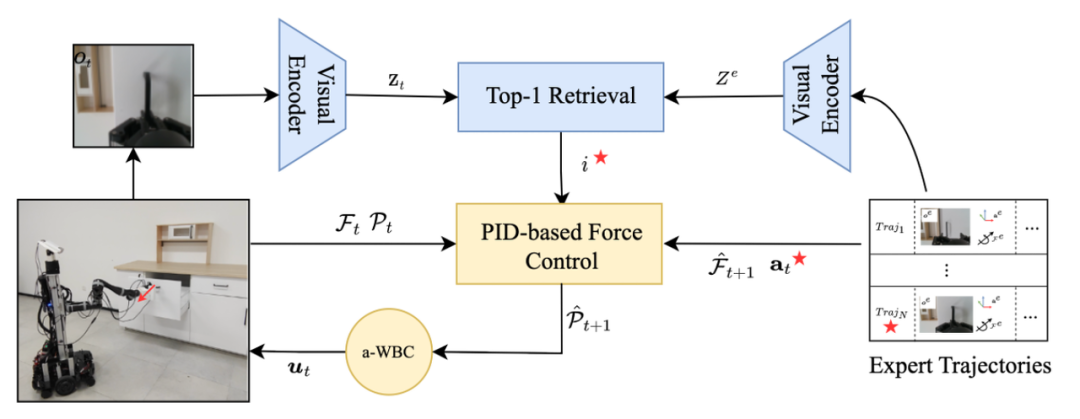
方法可以从两个部分进行拆解:
1. 目标行为的预测:实时视觉观测 -> 下个时刻机器人的状态预测
机器人的目标行为预测模块建立在最前沿的模仿学习方法上。它由两个阶段组成:离线的 RGB 视觉观测编码和在线编码运算。
- 在离线阶段,MOMA-Force 利用预训练的视觉编码器(ibot)将专家轨迹中每帧的 RGB 观测图像投影到深度嵌入中。该嵌入即 RGB 视觉观测的紧凑表示。
- 在在线阶段,MOMA-Force 利用同样的视觉编码器将每个时间点 t 所捕获的 RGB 观测图像也进行了编码,并通过计算与专家数据编码的相似度找出最相似的那一帧观测,这帧观测所对应的机器人在三维空间中末端位姿、夹爪的状态、六维力传感数据、任务完成状态等被匹配成为机器人当前的目标行为。
2. 导纳全身控制:实时力觉观测 -> 机械臂和底盘电机输出
由于机器人定位的精准度限制和目标行为预测的瑕疵,导纳全身控制用于为机器人系统形成基于力传感的闭环。在带有接触约束的任务中,小的姿态误差可能会导致大的接触力以及扭矩,甚至造成不可逆的机械损伤。因此,通过阻抗控制去弥补目标行为预测的不准确能够赋予移动操作机器人更加柔顺、安全的行为。
具体而言,MOMA-Force 通过导纳控制对预测出来的专家轨迹目标点位姿进行微调,微调之后的轨迹点通过基于最优控制的 QP 算法生成控制移动操作机器人整体构型空间(机械臂的 7 个关节和底盘轮子)的速度指令。
真机实验
实践出真知,有关 MOMA-Force 的能力边界需要一系列严格且科学的实验评测方式去进行验证。实验的设计紧密围绕机器人移动操作性能和机器人操作安全性两个方面展开,同时也对比了不同的预训练视觉编码器的效果。
Q:实验如何展开?
A:作者在六个带有接触约束的任务上进行了实验:例如拉抽屉、旋转水管、开洗衣机门、拉开柜门等。几乎所有的任务都要求机器人在操作过程中移动底盘并且保持与物体持续的合理的接触力。
作者为每个任务收集了 30 个专家演示:具体地说,对于每个时间点都记录了机器人末端相机的 RGB 观测图像、末端位姿、夹爪动作。所有操作任务都可以分为三个阶段:接近、抓取和接触操作。如果在任务执行过程中出现以下任一一种情况都会结束操作:1)完成任务;2)超时;3)力大于 40N 或过去 1 秒钟的平均力大于 30N。如果至少完成了一个任务轨迹长度的 80%,则认为这次实验成功。每种方法每个任务进行了 10 次实验。

Q:增加了力觉的模仿学习方法是否能够实实在在地提升任务成功率?
A:MOMA-Force 方法在跟其它基线方法的对比中实现了最佳的平均成功率。与单任务行为克隆 BC(Behavior Cloning)方法相比,MOMA-Force 将任务成功率从 20% 提升到了 73.3%。有力觉的 MOMA-Force 对比无力觉的 MOMA-Force 成功率是 73.3% 比 45%。

以下视频素材对比展示了 MOMA-Force 以及其它对照基线方法在真机上的表现效果:
行为克隆(BC):任务成功率较低

MOMA-Force 无力觉 :由于接触力过大导致操作中断

MOMA-Force

Q:从直觉上如何理解力觉模仿会带来对任务成功率的提升?
A:当机器人在执行一些任务时,通过预训练模型预测的机器人未来状态总是不完全准确的,加上机器人在移动过程中底盘定位误差,机器人动力学导致的状态误差等等都会使得末端夹爪的位置不准确,进而使得末端与操作物体(比如门把手)接触时存在较大的应力。由于机器人夹爪和物体是硬接触的,一点微小的位置姿态误差都会造成很大的接触应力,这样的接触应力超过一定阈值后可能会对机器人造成不可逆的机械损伤,这样就判定这种情况为失败。只有加入了力觉模仿学习的方案才能够使得机器人调整姿态释放掉末端的接触应力,也就大大避免了在操作过程中因为应力过大而失败的情况。
Q:MOMA-Force 相比 BC 以及没有力觉模仿的方案,力传感的数据是怎样的呢?
A:实验对比了 MOMA-Force 和其它几个基线方法。对于所有的方法,作者计算了在六个任务中所有成功的实验的平均绝对接触力、力矩和平均力、力矩方差,然后对任务进行平均(如图)。较小的力、力矩方差表示执行任务过程中更稳定的接触。MOMA-Force(红色柱子)在 x、y 和 z 轴上的平均绝对接触力和力矩都是最小的,且方差也是最小的。

Q:不同的预训练视觉编码器在真实机器人数据上表现的对比如何?
A:实验通过对比各种 SOTA 的预训练模型作为视觉编码器在 5 倍交叉验证的测试集上的均方误差(MSE)来比较不同的视觉预训练编码器的有效性,表格 II 展示了结果。MVP(Masked Visual Pretraining)是基于 masked auto-encoder 通过互联网视频数据进行的预训练的。CLIP 旨在通过对比学习(contrastive learning)将图像表示与文本对齐。同样由字节跳动提出的 iBOT 通过在线标记器(online tokenizer)在 masked auto-encoder 和对比学习之间取得了良好的平衡。由于 iBOT 以自蒸馏的方式进行掩膜图像建模,并通过对图像使用在线 tokenizer 进行 BERT 式预训练,让 CV 模型获得了通用广泛的特征表达能力。表格 II 显示 iBOT 的特征表示能力十分有效,在实验任务中取得了最佳的表现性能。