这几个月以来,我们已经见证了大型语言模型(LLM)在生成高质量文本和解决众多语言任务方面出色的能力。然而,LLM 又面临这样一个困境,即产生的输出很大程度上与人类偏好并不一致。如果没有适当的对齐,语言模型可能输出不安全的内容。此外,对齐 LLM 还有助于改善下游任务。
有研究者提出基于人类反馈的强化学习 (RLHF),通过使用人类偏好来解决对齐问题。
一般来讲,RLHF 依赖于 PPO、A2C 等在线 RL 方法,但这些方法计算成本高昂且容易遭受打击;虽然离线 RL 可以避免在线 RL 的缺陷,然而,离线学习的质量过分依赖离线数据集的属性。因此,精心策划的数据集对离线强化学习来说非常重要。
本文,来自 Google DeepMind 的研究者提出了一种简单的算法使 LLM 与人类偏好对齐,他们将该方法命名为 ReST(Reinforced Self-Training)。不同于 RLHF 使用人类反馈改进语言模型,ReST 通过生成和使用离线数据进行训练,从而使得 LLM 与人类偏好保持一致。
给定一个初始 LLM 策略,ReST 能够根据该策略生成数据集,然后该数据集基于离线 RL 算法被反过来提高 LLM 策略。ReST 比典型的在线 RLHF 方法更有效,因为训练数据集是离线生成的,这允许数据重用。
研究团队表示,虽然 ReST 可用于所有生成任务,但本文的重点是机器翻译。结果表明,ReST 可以极大地提高翻译质量。

论文地址:https://arxiv.org/pdf/2308.08998.pdf
有研究者评论道:「DeepMind 展示了自然语言生成的迭代自我改进。他们将『人』从人类反馈强化学习 (RLHF) 循环中剔除,提出 ReST。」
下面那我们看具体实现方法。
方法介绍
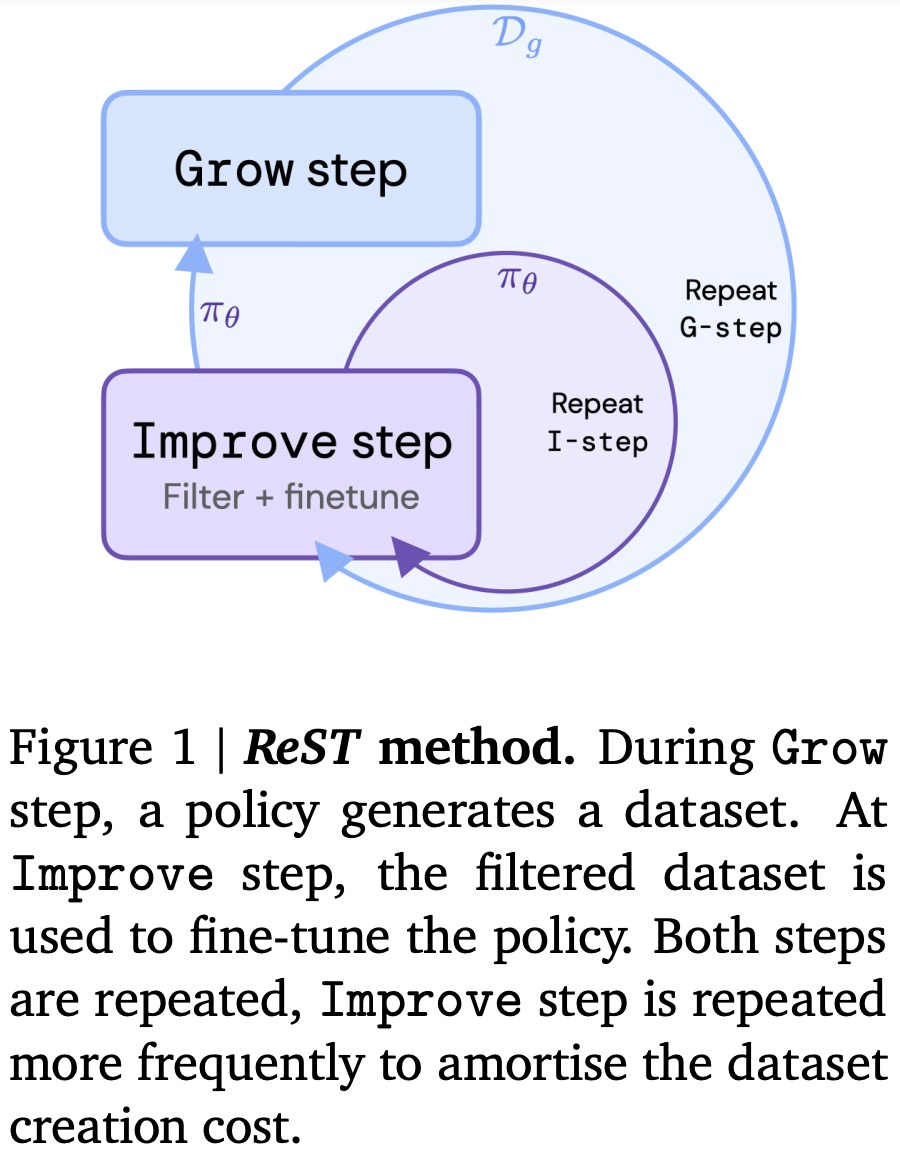
该研究提出了一种称为强化自训练(Reinforced Self-Training,ReST)的 RLHF 算法,ReST 可将语言模型的输出与人类偏好保持一致。人类对序列的偏好是使用学得的奖励函数来建模的。ReST 算法将典型 RL pipeline 的数据集增长(Grow)和策略改进(Improve)解耦成两个单独的离线阶段。
如下图 1 所示,ReST 方法包括两个循环:内循环(Improve step)和外循环(Grow step)。并且与在线或离线 RL 的典型 RLHF 方法相比,ReST 具有以下优势:
- 与在线 RL 相比,ReST 由于在 Improve step 中利用了 Grow step 的输出,因此计算负担大大减少;
- 策略的质量不在受原始数据集质量的限制(如离线 RL),因为新的训练数据是从 Grow step 中经过采样得到的;
- 检查数据质量并判断对齐变得更加容易,因为 Improve step 和 Grow step 这两个过程是解耦的;
- ReST 简单、稳定,并且只有少量的超参数需要调优。
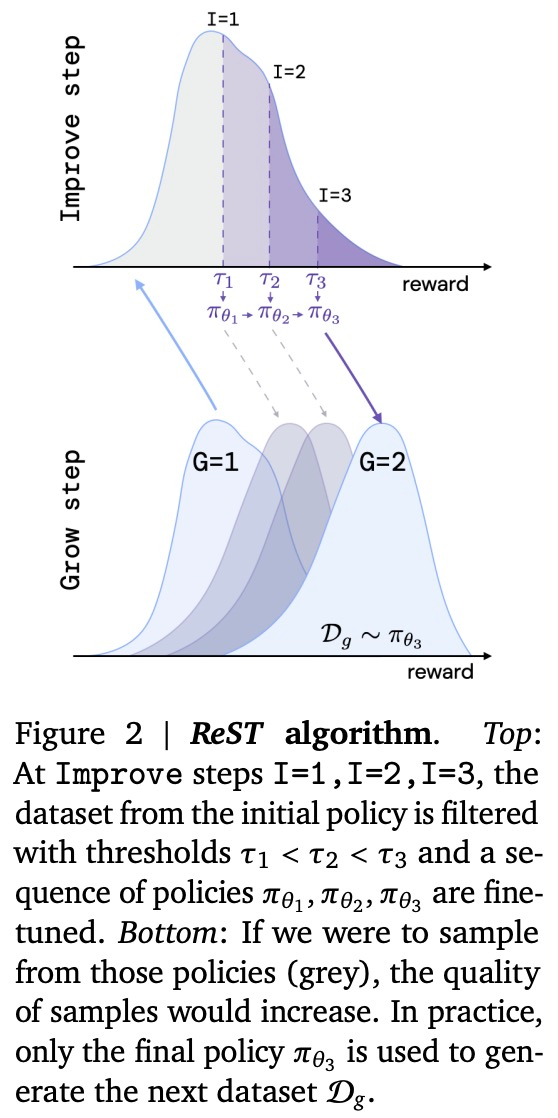
该研究首先训练一个初始模型 ,在给定序列对数据集 D 的情况下,使用如下等式 (1) 中的 NLL 损失将输入序列𝒙映射到输出序列𝒚。
,在给定序列对数据集 D 的情况下,使用如下等式 (1) 中的 NLL 损失将输入序列𝒙映射到输出序列𝒚。

接下来,Grow 步骤会创建一个新的数据集 D_𝑔,使用模型中的样本来扩充初始训练数据集:

其中,条件输入是从原始数据集 中重新采样的,就像自训练一样;但在可以访问 𝑝(𝒙) 的情况下也可以直接从中采样,即
中重新采样的,就像自训练一样;但在可以访问 𝑝(𝒙) 的情况下也可以直接从中采样,即 。例如,在文生图模型中,文本输入的分布可以从语言模型 𝑝(𝒙) 中采样。
。例如,在文生图模型中,文本输入的分布可以从语言模型 𝑝(𝒙) 中采样。
然后,Improve 步骤使用 D_𝑔 来微调策略𝜋_𝜃。值得注意的是,该研究将原始数据集保留在训练中,以确保策略不会发散。
整个 ReST 算法如下图算法 1 所示,其中包含多个数据集增长和策略改进步骤:

实验
研究者在机器翻译任务上进行了实验,测试基准包括 IWSLT 2014 、 WMT 2020 、 Web Domain 。
图 3 绘制了带有多个 Improve steps 的平均奖励:可以看到,随着 Improve steps 增加,翻译模型在所有三个数据集上的性能都得到了提高。

增加 Grow step(G)能否提高奖励模型的得分?带着这一问题,研究者进行了另一项实验。结果如图 4 所示,带有一个 Grow step 的方法在 IWSLT 2014 和 Web Domain 数据集上有所提高,当 Grow step 为 2 时,模型将得分从 77.8 提高到 80.5,提高了 5.3。

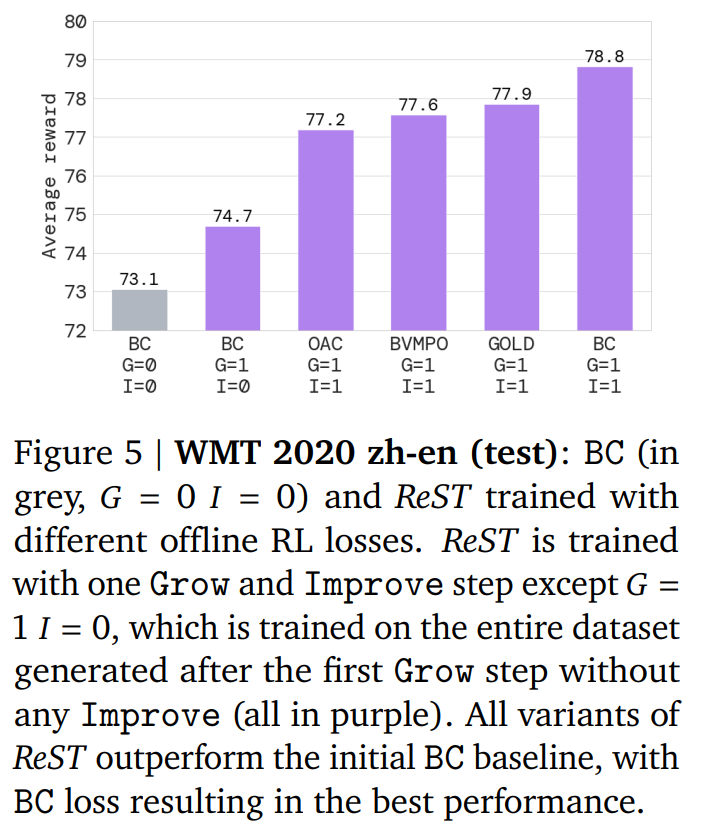
ReST 是否优于监督训练?结果如图 5 所示,即使在第一个 grow step 之后,ReST 的不同变体(紫色)也显着优于监督学习(灰色)。
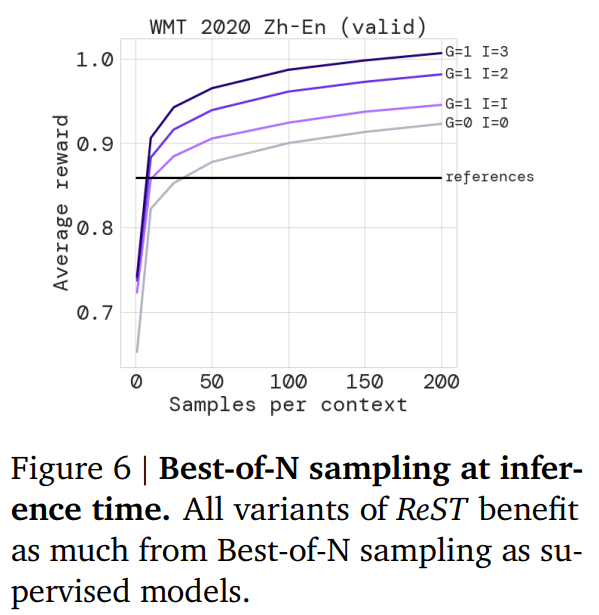
ReST 可以在推理时使用 Best-of-N 采样进一步改进吗?图 6 展示了 BC( behavioral cloning )和 ReST 变体之间的 Best-of-N 抽样结果。ReST 的性能随着 𝑁 和 Improve step 数量的增加而提高。得出 ReST 仍然可以从 Best-of-N 采样中受益。
ReST 与在线 RL 相比如何?该研究将 ReST 与 PPO 进行了比较,PPO 是一种广泛用于 RLHF 的在线 RL 算法。结果总结在表 1 中。

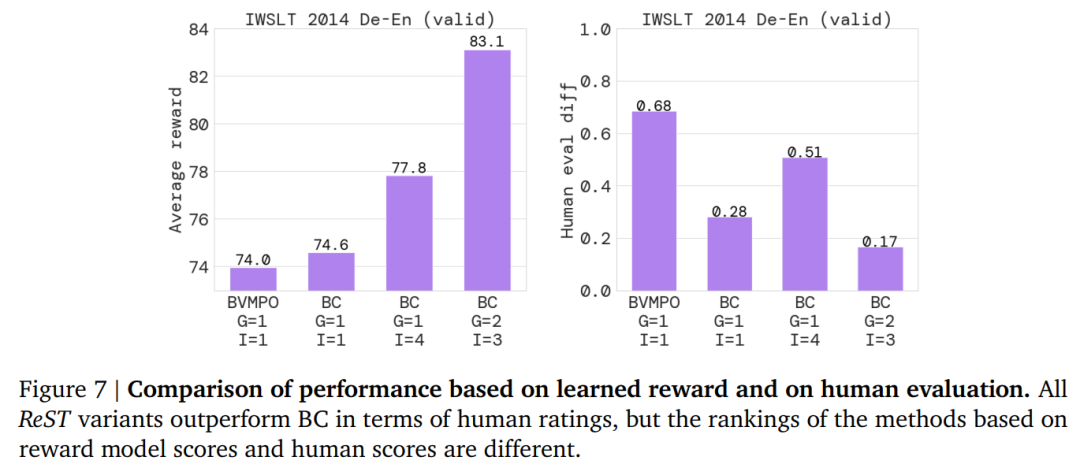
下图表明,所有 ReST 变体在人类评分方面优于 BC 方法: