













CV大佬朱俊彦的新论文,让动画师感觉危了。
只需要一句话,模型就能将其生成一个风格一致,画质细腻的动画。
以梵高星之夜为参考,创作一个山前小溪流过的画面。

又或以阿夫列莫夫的风格,创作一个瀑布从山间飞跃而下的景观。

近日,来自CMU和Snap机构的研究人员,构建了一个根据文本描述创建电影画面的全自动方法——Text2Cinemagraph。
 图片
图片
论文地址:https://arxiv.org/pdf/2307.03190.pdf
另外,研究人员展示了2个扩展功能,为现有绘画制作动画,以及使用文本控制运动方向。
不如,我们先看一波演示吧。
演示来袭
上面梵高星之夜的小溪流向,动动嘴就能控制。
比如,从左到右。

再从右到左。

同样风格下的,不同景观。

电影画质的,海上帆船。
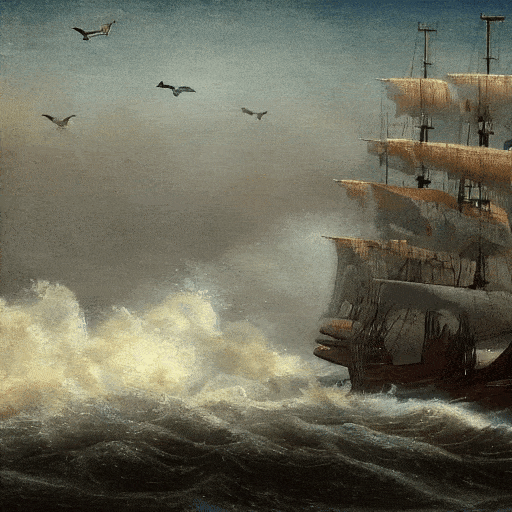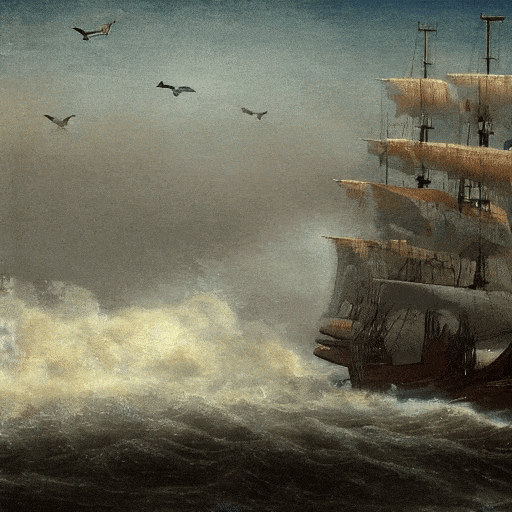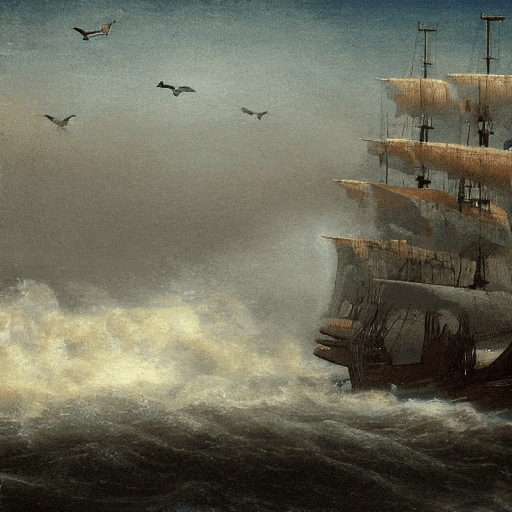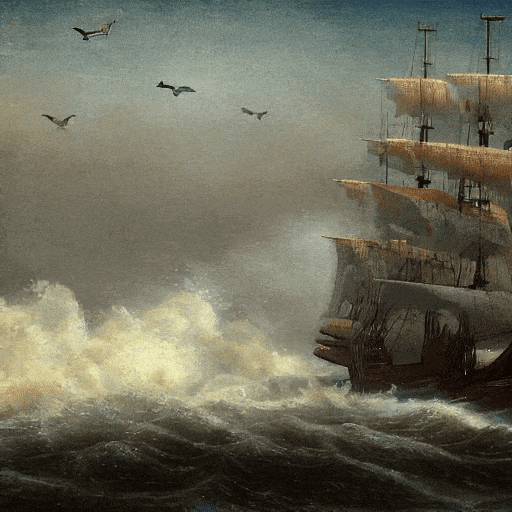
日落时,梵高绘画风格的,山丘之间落下的大瀑布,4K。

毕加索风格,一座小木屋,有一艘船漂浮在湖上。
超逼真的插图,灯塔被海怪袭击,触手包裹整个塔楼。

超现实和梦幻般的瀑布场景

Text2Cinemagraph项目
当前,现有的单图像动画方法,在艺术输入方面存在不足。
而最新的基于文本的视频方法经常会引入时间上的不一致性,难以保持某些区域的静态。
为了应对这些挑战,研究人员提出了从单个文本提示,合成孪生图像(image twin)的想法,即一对艺术图像及其像素对齐。
艺术图像描绘了文本提示中详细描述的风格和外观,而现实图像则大大简化了布局和运动分析。

利用现有的自然图像和视频数据集,Text2Cinemagraph可以准确地分割现实图像,并根据语义信息预测合理的运动。
然后,预测的运动可以转移到艺术图像中,以创建最终的电影动画。
具体来讲,给定一个文本提示 c,用Stable Diffusion生成孪生图像,一个艺术图像x在文本提示中描述的样式中,和一个现实的对应物 使用修改后的提示
使用修改后的提示 。孪生图像有相似的语义布局。
。孪生图像有相似的语义布局。
然后,研究人员从艺术图像生成过程中,获得的自注意力映射中提取运动区域的二进制掩码M。
使用掩码和逼真的图像,来预测光流 与流预测模型
与流预测模型 .
.
由于孪生图像有非常相似的语义布局,可以使用光流 与视频生成器
与视频生成器 让艺术图像动起来。
让艺术图像动起来。
值得一提的是,这项研究的所有实验都基于Stable Diffusion。

研究者比较了真实的光流效果。
与SLR-SFS、Holynski等人的研究单图像动画方法相比,Text2Cinemagraph所有帧平均的真实光流。
总体而言,最新方法能预测出更合理的运动,与目标区域更吻合。

另外,通过用户偏好调查显示,大多数参与者都赞成Text2Cinemagraph。

最后,研究人员还演示了两个扩展功能:为现有绘画制作动画和使用文本控制运动方向。
为现有绘画制作动画
如下是在俄罗斯博物馆展出的The Ninth Wave (1850)。

由Albert Bierstadt创作的布面油画Minnehaha Falls。
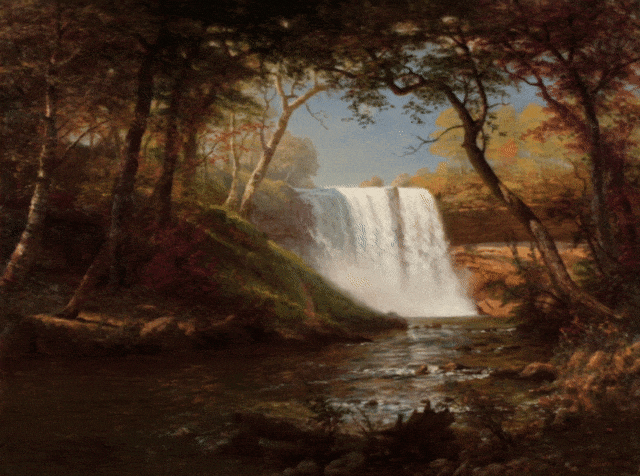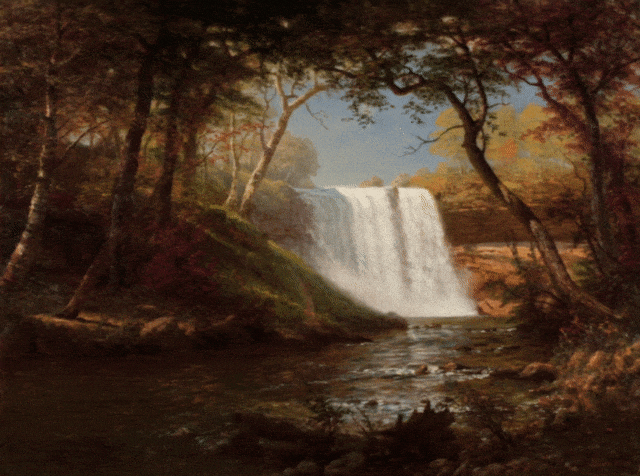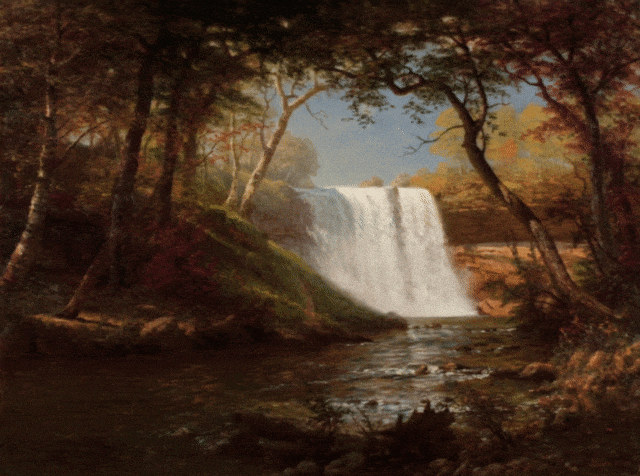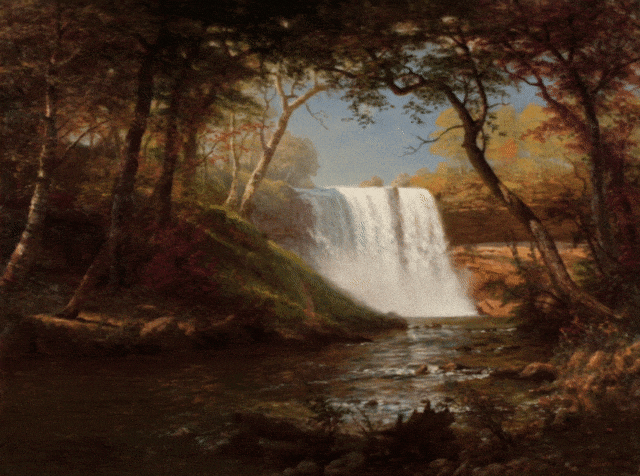
作者介绍
Jun-Yan Zhu(朱俊彦)

朱俊彦现任CMU计算机学院机器人研究所的助理教授,是计算机图形学领域现代机器学习应用的开拓者。
在加入CMU之前,他曾是Adobe Research的研究科学家。
他曾在MIT CSAIL做博士后,与William T. Freeman、Josh Tenenbaum和Antonio Torralba一起工作。
他还在加州大学伯克利分校获得博士学位,在Alexei A.Efros的指导下。并在清华大学获得学士学位,与Zhuowen Tu,Shi-Min Hu和Eric Chang一起工作。


















