爆火的大模型,正在重塑「通用机器人智能体」的研究。
前段时间,谷歌DeepMind推出了耗时7个月打造的项目RT-2,能数学推理、辨认明星,在网上爆火了一把。

除了谷歌,来自Meta、CMU的研究人员用了2年的时间,打造出史上最强的通用机器人智能体「RoboAgent」。
不同的是,RoboAgent,仅在7500个轨迹上完成了训练。

具体来说,RoboAgent在38个任务中,实现了12种不同的复杂技能,烘培、拾取物品、上茶、清洁厨房等等。
甚至,它的能力还能够泛化到100种未知的场景中。
可以说,上得了厅堂,下得了厨房。
有趣的是,不论你怎么干扰它,RoboAgent依旧设法去完成任务。

RoboAgent究竟还能做什么?
烘焙、上茶、擦桌子全能手
首先,RoboAgent可以很流畅地拉开或关上抽屉。
虽然在打开时险些碰倒了酸奶,但动作的衔接上基本没有卡顿,丝滑地完成了推拉的动作。

除了抽屉,RoboAgent还能轻松打开或关上微波炉的门。
但它没有像人类一样抓握把手,而是将自己卡进了把手与门之间的空隙中,再使力开合了微波炉的门。
同样地,面对瓶瓶罐罐上的盖子,RoboAgent也能精准拿捏,打开、盖上——绝不拖泥带水。
然而在厨房中,除了盖着的调料罐,也有一些需要拧开的罐子,比如料酒和老干妈等等....
好在,对于各种拾取和放置类任务,RoboAgent基本是不在话下的。
视频中,RoboAgent从抽屉里拿出东西、又或是把茶包放进杯子里,打开微波炉将碗放进去等。展示的便是RoboAgent能够理解泡茶、加热食物等任务中包含的一系列动作。
对以上九个动作进行排列组合,基本就可以覆盖在厨房中一系列任务。
例如为烘焙做准备、打扫厨房、上菜汤、泡茶、收纳餐具等。
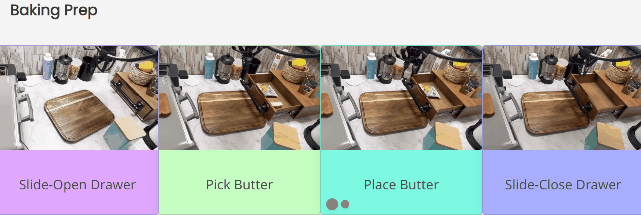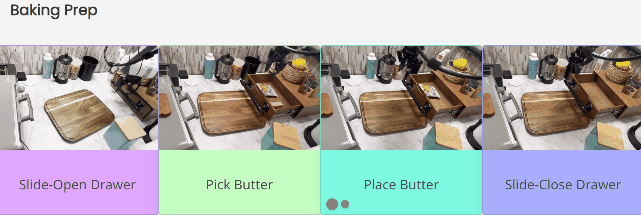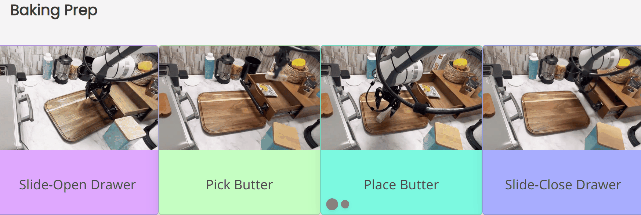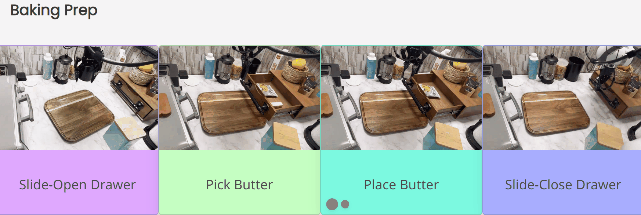
为烘焙做准备时,首先要拉开抽屉,然后找到放在里面的黄油。找到后把黄油放到案板上,最后关上抽屉。
看起来RoboAgent这一系列动作的前后逻辑顺序已经和真实的生活场景十分接近了。
但RoboAgent依旧不像人类一样灵活,先不提人类有两只手,可以一只手拿黄油,另一只手关抽屉。就算只用一只手,人类也可以拿着黄油的同时侧手把抽屉推回去。而RoboAgent只能先把黄油放下,然后才去关抽屉。
看起来没有那么灵活的样子。
打扫厨房时,RoboAgent也是四步走:
先关上抽屉,再关上微波炉。然后从旁边拿出一个毛巾,最后擦案板。
上菜汤时,RoboAgent先打开微波炉,然后从微波炉里拿出放在里面的碗。之后把碗放在桌子上,最后把微波炉关上。
但这里RoboAgent的表现就没有那么让人放心了。
只能说还好演示视频中的碗是空的,如果真让RoboAgent这样在现实中拿装了食物的碗盆,估计它刚拿起来食物就洒地到处都是了。
不过,RoboAgent对泡茶倒是得心应手:
先取开茶罐上的盖子,从里面拿出茶包,然后把茶包精准降落在杯子里,最后捡起盖子放回到罐子上。
但这离完美的一杯茶还差了一步:倒水。还是说RoboAgent是在请我们喝有茶香的空气吗?
纵观上述RoboAgent的表现,虽然大部分任务都能顺利完成,但只有一只手还是太不方便了。
希望Meta和CMU能多给RoboAgent安几只手,这样它就能同时干好几件事,大大提高效率。
耗时2年,打造「通用机器人智能体」
Meta和CMU的研究人员希望,RoboAgent能够成为一个真正的通用机器人智能体。
历时2年,他们在不断推进这一项目的前进。RoboAgent是多向研究的集合体,同时也是未来更多研究方向的起点。
在「通用机器人智能体」发展过程中,研究人员深受许多最近可泛化的机器人学习项目的启发。
当前,在迈向通用机器人智能体路上,需要解决两大难题。
一是,因果两难。
几十年来,拥有一个能够在不同环境中操纵任意物体的机器人一直是一个遥不可及的宏伟目标。部分原因是缺乏数据集来训练这种智能体,同时也缺乏能够生成此类数据的通用智能体。
二是,摆脱恶性循环。
为了摆脱这种恶性循环,研究重点是开发一种有效的范式。
它可以提供一个通用智能体,能够在实际的数据预算下获得多种技能,并将其推广到各种未知的情况中。

论文地址:https://robopen.github.io/media/roboagent.pdf
根据介绍,RoboAgent建立在以下模块化和可补偿的要素之上:
- RoboPen:
利用商品硬件构建的分布式机器人基础设施,能够长期不间断运行。
- RoboHive:
跨仿真和现实世界操作的机器人学习统一框架。
- RoboSet:一个高质量的数据集,代表不同场景中日常对象的多种技能。
- MT-ACT:
一种高效的语言条件多任务离线模仿学习框架。它通过在现有机器人经验的基础上创建一个多样化的语义增强集合来倍增离线数据集,并采用一种具有高效动作表示法的新型策略架构,以在数据预算范围内恢复高性能策略。

动作分块,全新架构MT-ACT
为了学习通用的操作策略,机器人必须接触丰富多样的经验,包括各种技能和环境变化。
然而,收集如此广泛的数据集的操作成本和现实挑战,限制了数据集的总体规模。
研究人员的目标是通过开发一种范式来解决这些限制,该范式可以在有限的数据预算下学习有效的多任务智能体。
如下图所示,Meta和CMU团队提出了MT-ACT,即多任务动作分块Transformer(Multi-Task Action Chunking Transformer)。

这一方法由2个阶段组成:
第一阶段:语义增强
RoboAgent通过创建RoboSet(MT-ACT)数据集的语义增强,从现有基础模型中注入世界先验。
由此产生的数据集,可在不增加人类/机器人成本的情况下,将机器人的经验与世界先验相乘。
然后,研究人员使用SAM分割目标对象,并将其语义增强为具有形状、颜色和纹理变化的不同对象。
第二阶段:高效的策略表示
生成的数据集是多模态的,包含丰富多样的技能、任务和场景。
研究人员将动作分块适应于多任务设置,开发出MT-ACT——一种新颖高效的策略表示,既能摄取高度多模态的数据集,又能在低数据预算设置中避免过度拟合。
如下,是MT-ACT策略的各个组成部分。
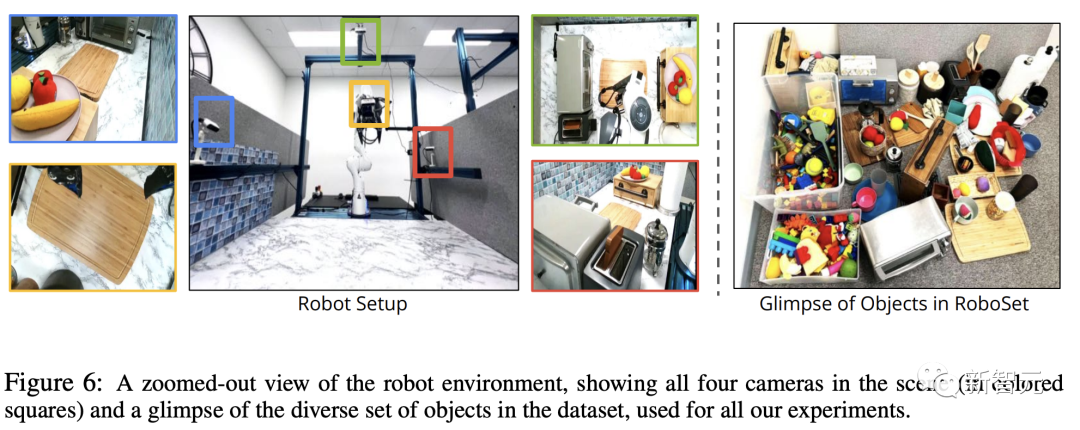
RoboSet数据集
研究的目标是建立一个数据高效的机器人学习范例,对此,研究人员将自己限制在一个冻结的、预先收集的小型但多样化的数据集上。
为了捕捉行为多样性,研究人员还在不同的厨房场景中,将不同的技能应用到不同的任务中。
在这个项目中,数据集 RoboSet(MT-ACT)由人类远程操作收集的7500 条轨迹组成。
该数据集包含 12 种技能,横跨多个任务和场景。
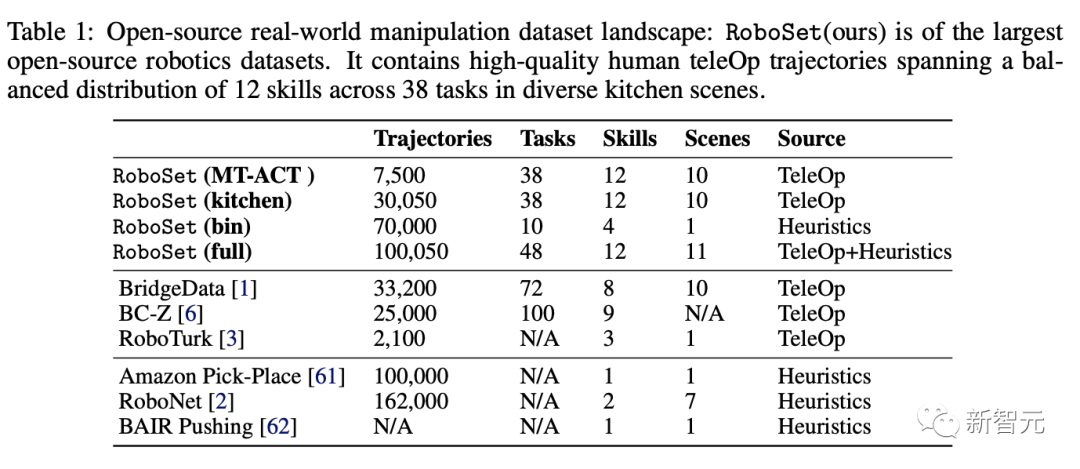
下图显示了,数据集中技能的分布情况。
虽然常用的「拾取-放置」技能在数据集中占40% ,但也包括丰富的接触技能,如擦拭、盖帽,以及涉及铰接物体的技能(翻转-打开、翻转-关闭)。
研究人员在4个不同的厨房场景实例中收集整个数据集,这些场景中包含各种日常物品。
此外,团队还将每个场景实例与不同变化的物体进行交换,从而让每个技能接触到多个目标物体和场景实例。
数据增强
由于收集的数据集无法满足对场景和物体多样性的需求,因此研究人员通过离线添加不同变化的场景来增加数据集,同时保留每个轨迹中的操纵行为。
基于最近在分割和局部重绘(inpainting)模型取得的进展,研究人员从互联网数据中提炼出真实世界的语义先验,以结构化的方式修改场景。

MT-ACT架构
MT-ACT的策略架构设计为一个有足够容量的Transformer的模型,可以处理多模态多任务机器人数据集。
为了捕捉多模态数据,研究人员沿用了之前的研究成果,加入了将动作序列编码为潜在风格嵌入式z的CVAE。
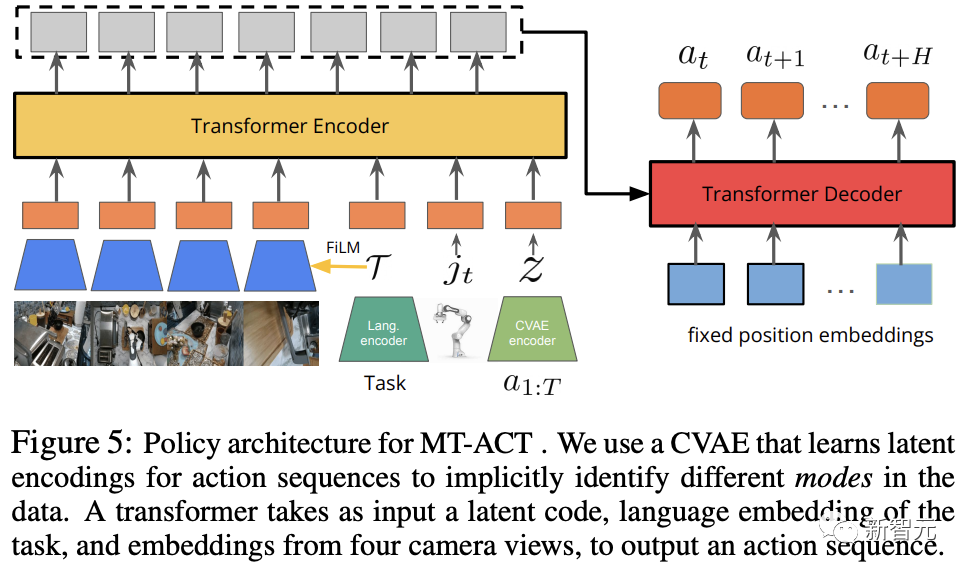
为了建立多任务数据模型,研究采用了预训练的语言编码器,该编码器可学习特定任务描述的嵌入 。
。
为了减少复合误差问题,在每个时间步预测未来H步的行动,并通过对特定时间步预测的重叠行动进行时间平滑来执行。
另外,为了提高对场景变化的稳健性,研究人员通过4个拍照角度为MT-ACT策略提供了工作空间的四个不同视图。
Transformer编码器以当前的时间步长 、机器人的当前关节姿态
、机器人的当前关节姿态 、CVAE 的风格嵌入z,以及语言嵌入T作为输入。
、CVAE 的风格嵌入z,以及语言嵌入T作为输入。
然后,再使用基于FiLM的调节方法,以确保图像token能够可靠地集中在语言指令上,从而在一个场景中可能存在多个任务时,MT-ACT策略不会对任务产生混淆。
编码后的token将进入具有固定位置嵌入的Transformer策略解码器,最终输出下一个动作块(H个动作)。
在执行时,研究人员会对当前时间步预测的所有重叠操作,取平均值(当H > 1时,行动块会重叠),并执行产生平均后的行动。
少量数据,赶超谷歌RT-1
MT-ACT策略在真实世界表现如何?
研究人员通过实验评估了提出的框架样本效率,以及智能体在不同场景中的通用性。
下图,将MT-ACT策略与常用的模仿学习架构进行了比较。
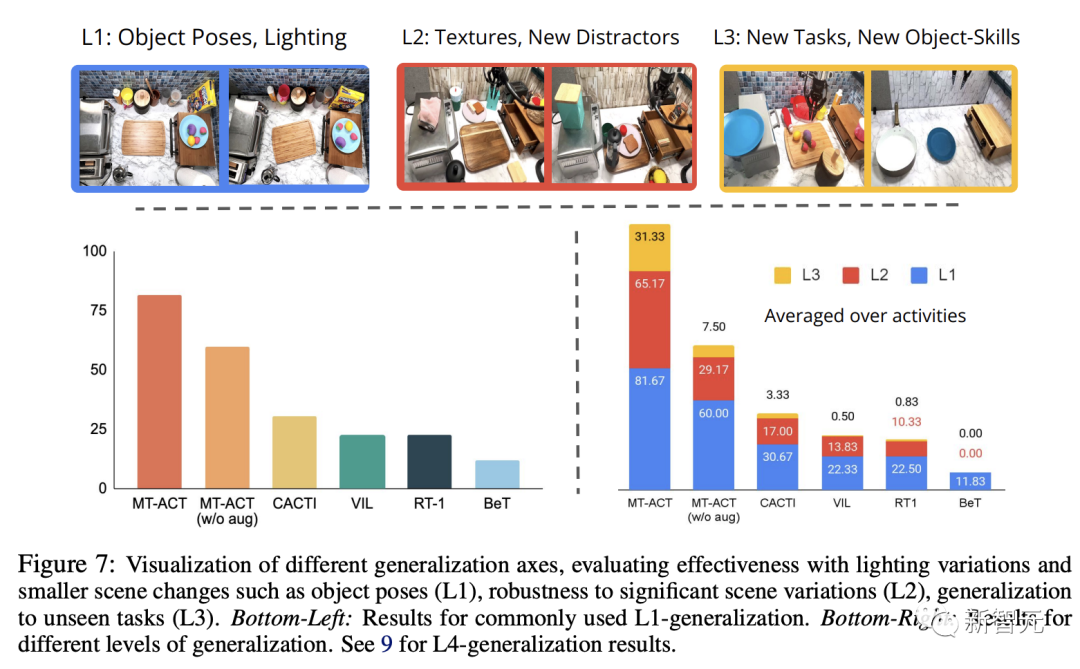
研究人员只绘制了L1泛化的结果,因为这是大多数其他模仿学习算法使用的标准设置。
从图中可以看出,所有只模拟下一步行为(而不是子轨迹)的方法都表现不佳。
在这些方法中,研究人员发现基于动作聚类的方法(BeT)在多任务设置中的表现要差得多。
此外,由于研究采用的是低数据机制,需要大量数据的类似RT1的方法在这种情况下表现不佳。
相比之下,MT-ACT策略使用动作检查对子轨迹进行建模,其表现明显优于所有基线方法。
图7(右下)显示了跨多个泛化级别(L1,l2和 L3)的所有方法的结果。
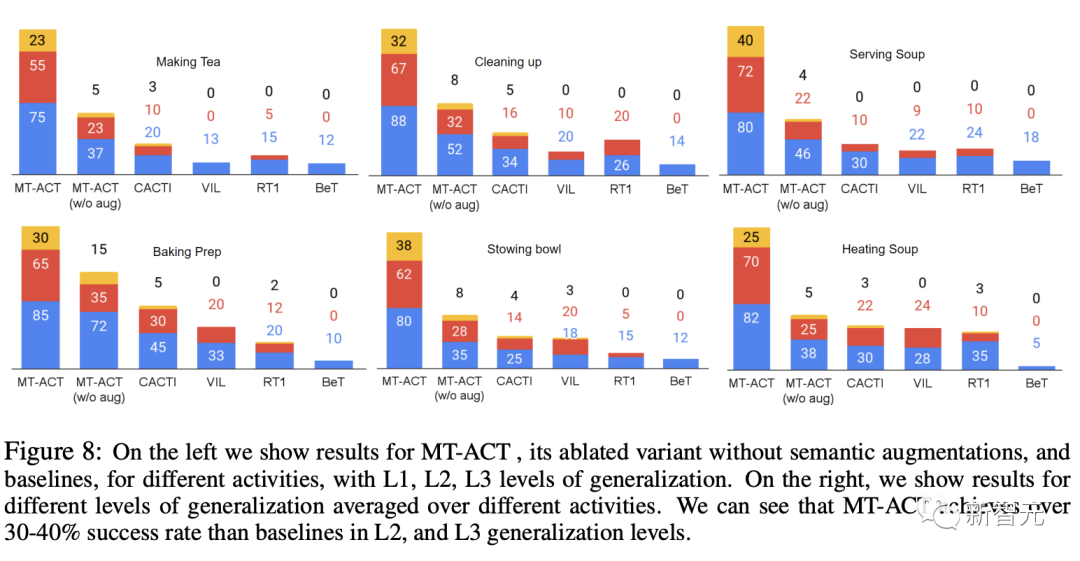
此外,研究人员还分别报告了每种活动的泛化结果。从图8中可以看到,每种语义增强方法都对每种活动的性能产生了积极影响。
最后,研究人员还利用不同的设计来对架构进行了研究,比如动作表示块的大小、可塑性、稳健性。