












随着各种语言、视觉、视频、音频等大模型的性能不断提升,多模态机器学习也开始兴起,通过整合多种模态的数据,研究人员们开始设计更复杂的计算机智能体,能够更好地理解、推理和学习现实世界。
在发展过程中,多模态机器学习的研究也带来了计算、理论上的挑战,在融合多模态、智能体自主性,以及多传感器融合等应用场景下,还存在异构数据源等新兴的数据模式发现方法。

最近,来自卡内基梅隆大学的研究人员发表了一篇关于多模态机器学习的全面总结,并在ICML 2023会议上举办了Tutorial,通过对应用领域和理论框架进行综述,对多模态机器学习的计算和理论基础进行概述。

论文链接:https://arxiv.org/pdf/2209.03430.pdf
演示文稿:https://drive.google.com/file/d/1qIYBuYrSW2-e95DL7LndfLFqGkIWFG21
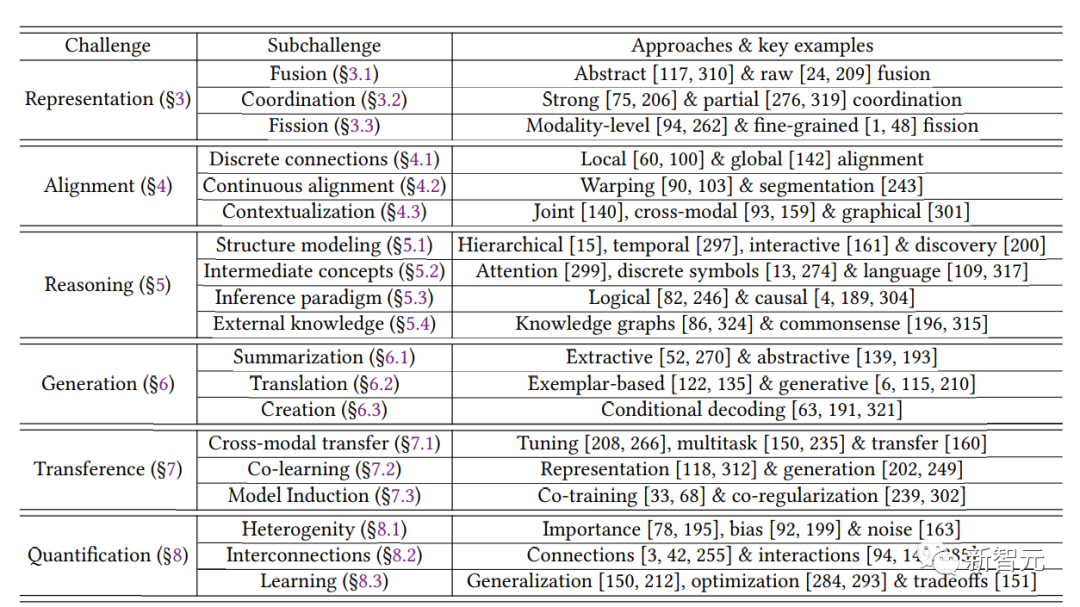
研究人员首先定义了驱动后续创新的模态异质性、连接和交互的三个关键原则,并提出了六个核心技术挑战的分类:表征、对齐、推理、生成、迁移和量化,文中涵盖多模态机器学习的研究历史以及近期趋势。

论文作者Paul Pu Liang是卡耐基梅隆大学机器学习系的博士生,导师为Louis-Philippe Morency和Ruslan Salakhutdinov,主要研究方向为多模态机器学习的基础,及其在社交智能AI、自然语言处理、医疗保健和教育上的应用。
挑战1:表征 Representation
如何学习能反映不同模态中单个元素之间跨模态交互的表征是一个问题,可以把这个挑战视为学习元素之间的局部表征,或使用整体特征的表征。
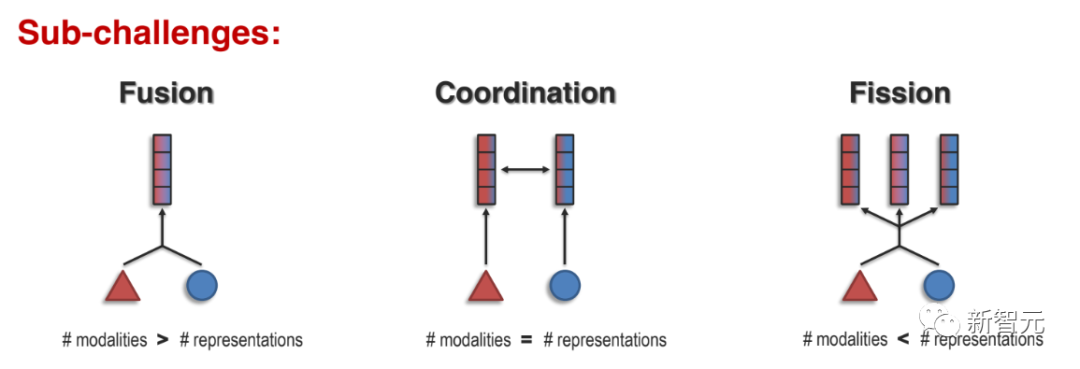
论文中主要介绍了三个子问题:
1. 表征融合(Representation Fusion)
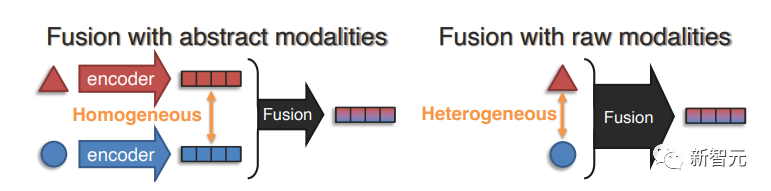
表征融合的目的是学习到一种联合表征,可以模拟不同模态中各个元素之间的跨模态交互,从而有效减少独立表征的数量。
研究人员将这些方法分为两类:
(1)抽象模态融合,先应用合适的单模态编码器来捕捉每个元素(或全部模态)的整体表征,然后使用表征融合的几个构件来学习联合表征,即融合发生在抽象表征层面。
(2)原始模态融合,在早期阶段进行表征融合,只需要进行简单的预处理,甚至可以直接输入原始模态数据本身。
2. 表征协调(Representation Coordination)
其目的是学习多模态语境化表征,这些表征通过相互关联而相互协调;与表征融合不同的是,协调保持了表征的数量不变,但改进了多模态语境化。
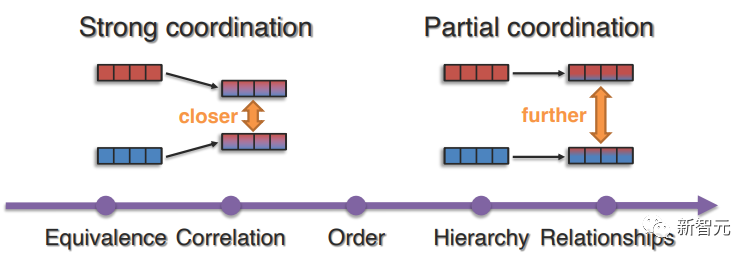
文中首先讨论了强制模态元素之间强等价性的强协调,然后再讨论部分协调,部分协调可以捕捉到更普遍的联系,如相关性、顺序、层次或超越相似性的关系。
3. 表征裂变(Representation Fission)
其目的是创建一套新的解耦表征(通常比输入表征集的数量要多),以反映内部多模态结构的知识,如数据聚类、独立的变化因素或特定模态信息。
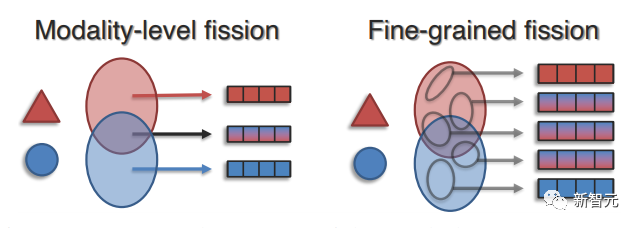
与联合表征和协调表征相比,表征裂变可实现细致的解释和细粒度的可控性,根据解耦因素的粒度,可将方法分为模态级裂变和细粒度裂变。
挑战2:对齐(Alignment)
对齐的作用是识别多种模态元素之间的跨模态连接和互动,例如在分析人类主体的语音和手势时,应该如何才能将特定手势与口语单词或语句对齐?
模态之间的对齐可能存在长距离的依赖关系,或是涉及模糊的分割(如单词或语句),而且可能是一对一、多对多或根本不存在对齐关系,所以非常具有挑战性。
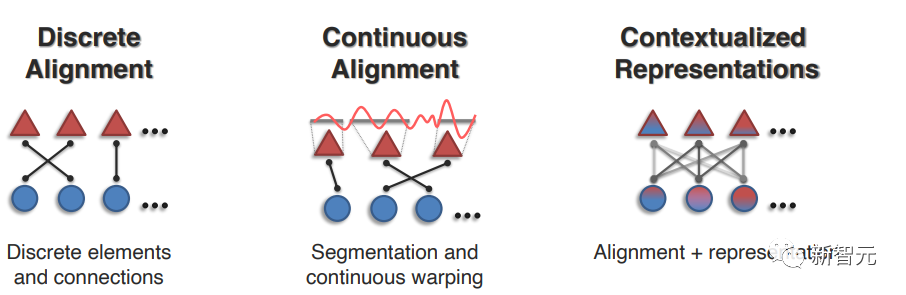
1. 离散对齐(Discrete Alignment)
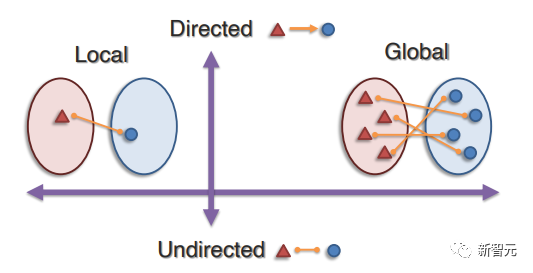
其目标为识别多种模态离散元素之间的联系,最近的工作主要包括两种方法:局部对齐发现给定匹配的一对模态元素之间的连接;全局对齐,必须在全局范围内进行对齐,以学习连接和匹配。
2. 连续对齐(Continuous Alignment)
之前的方法基于一个重要假设,即模态元素已经被分割和离散化。
虽然某些模态存在清晰的分割(如句子中的单词/短语或图像中的对象区域),但在许多情况下,分割边界并不容易找到,如连续信号(如金融或医疗时间序列)、时空数据或没有清晰语义边界的数据(如核磁共振图像)。
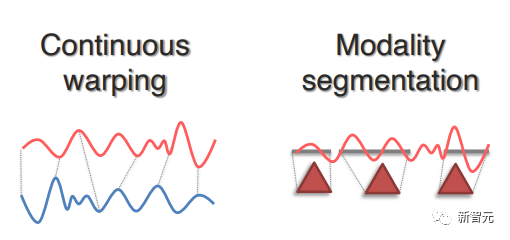
在最近的一些工作中提出了基于连续扭曲(Continuous warping)和以适当的粒度将连续信号分割为离散元素的模态分割(Modality segmentation)的方法。
3. 上下文表征(Contextualized Representations)
其目的是为所有模态连接和交互建模,以学习更好的表征,可以当作是中间步骤(潜在步骤),能够在语音识别、机器翻译、媒体描述和视觉问题解答等一系列下游任务中取得更好的性能。
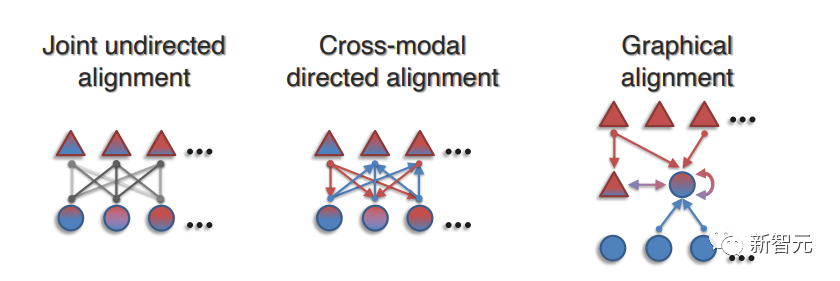
文中将上下文表征方面的工作分为:
(1)联合无向对齐(Joint undirected alignment),可以捕捉跨模态对的无向连接,这些连接在任一方向上都是对称的;
(2)跨模态有向对齐(Cross-modal directed alignment),以有向方式将源模态中的元素与目标模态联系起来,可建立非对称连接模型;
(3)图网络对齐(Graphical alignment),将无向或有向对齐中的顺序模式推广到元素之间的任意图结构中。
挑战3:推理
推理的定义为结合知识,通常通过多个推理步骤,利用多模态排列和问题结构。
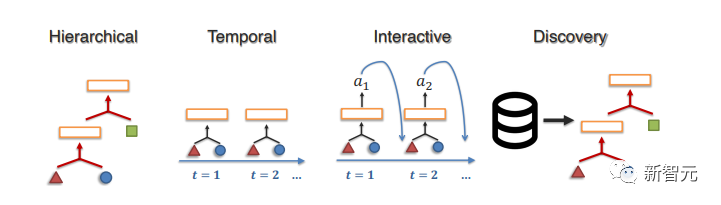
1. 结构建模(Structure Modeling)
这一步的目的在于捕捉组合的层次关系,通常是通过参数化原子、关系和推理过程的数据结构来实现。
常用的数据结构包括树、图或神经模块,文中介绍了最近在潜在层次结构、时间结构和交互结构建模方面的工作,以及在潜在结构未知的情况下发现结构的工作。
2. 中间概念(Intermediate Concepts)
这个问题研究了如何在推理过程中对单个多模态概念进行参数化。
虽然在标准神经架构中,中间概念通常是密集的向量表征,但在可解释的注意力图(attention map)、离散符号和语言作为推理的中间媒介方面,也有大量相关工作。
3. 推理范式( Inference Paradigms)
这一部分主要解决如何从单个多模态证据中推断出越来越抽象的概念。
虽然局部表征融合(如加法、乘法、基于张量、基于注意力和顺序融合)方面的进展在此也普遍适用,但推理的目标是通过有关多模态问题的领域知识,在推理过程中提高可解释性,文中主要举例说明通过逻辑和因果运算符对推理过程进行显式建模的最新方向。
4. 外部知识
从定义组成和结构的研究中推导知识,其中知识通常来自特定任务数据集上的领域知识。
作为使用领域知识预先定义组成结构的替代方法,近期的研究工作还探索了使用数据驱动方法自动推理的方法,例如在直接任务领域之外广泛获取但监督较弱的数据。
挑战4:生成
模型需要学习生成过程,通过摘要、翻译和创造,生成反映跨模态交互、结构和连贯性的原始模态,这三个类别沿用了文本生成的分类方法,根据从输入模态到输出模态的信息变化来进行区分。
1. 摘要(Summarization)
摘要的目的是压缩数据,创建一个能代表原始内容中最重要或最相关信息的摘要,除了文本格式外,还包括图像、视频、音频等模态的摘要。
虽然大多数方法只关注从多模态数据中生成文本摘要,但也有几个方向探索了生成摘要图像以补充生成的文本摘要。
2. 翻译(Translation)
翻译的目的是将一种模态映射到另一种模态,同时尊重语义联系和信息内容,例如为图像生成描述性标题有助于提高视觉内容对盲人的可及性。
多模态翻译也带来了新的难题,例如高维结构化数据的生成及其评估,主流方法可分为基于范例的方法和生成模型的方法,前者仅限于从训练实例中检索以在不同模态之间进行翻译,但能保证翻译的保真度;后者可翻译成数据之外的任意插值实例,但在质量、多样性和评估方面面临挑战。
尽管存在这些挑战,最近在大规模翻译模型方面取得的进展已经在文本到图像、文本到视频、音频到图像、文本到语音、语音到姿态、说话者到听众、语言到姿态以及语音和音乐生成等方面产生了令人印象深刻的高质量生成内容。
3. 创造(Creation)
创造的目的是从小规模的初始示例或潜在的条件变量生成新颖的高维数据(可涵盖文本、图像、音频、视频和其他模态),该条件解码过程极具挑战性,需要模型具有:
(1)有条件:保留从初始种子到一系列远距离并行模态的语义映射;
(2)同步:跨模态的语义一致性;
(3)随机:在特定状态下捕捉许多可能的后代;
(4)在可能的远距离范围内自动回归。
挑战5:迁移(Transference)
其目的是在模态及其表征之间迁移知识,主要它探索从第二种模态中学到的知识(如预测标签或表征)如何帮助在第一模态上训练的模型?
当主模态的资源有限(如缺乏标注数据、输入噪声大或标签不可靠)时,解决这一问题尤为重要,因为次模态信息的迁移会产生主模态从未见过的新行为。
1. 跨模态迁移(Cross-modal Transfer)
在大多数情况下,收集第二模态的标注或非标注数据并训练强大的监督或预训练模型可能更容易,然后可以针对涉及主模态的下游任务对这些模型进行调节或微调,从而将单模态迁移和微调扩展到了跨模态环境中。
2. 多模态协同学习(Multimodal Co-learning)
多模态协同学习旨在通过共享两种模态之间的中间表征空间,将通过次模态学习到的信息迁移到包含主模态的目标任务中,这些方法的本质是在所有模态中建立一个单一的联合模型。
3. 模型归纳(Model Induction)
与协同学习不同,模型归纳方法将主模态和次模态的单模态模型分开,但目的是归纳两个模型的行为。
联合训练就是模型归纳的一个例子:在联合训练中,两种学习算法分别在数据的每个视图上进行训练,然后使用每种算法的预测对未标记的新示例进行伪标记,以扩大另一个视图的训练集,也就是说,信息是通过模型预测而不是共享表示空间在多个视图之间传递的。
挑战6:量化
量化的目的是对多模态模型进行更深入的实证和理论研究,以获得洞察力并提高其在实际应用中的稳健性、可解释性和可靠性。
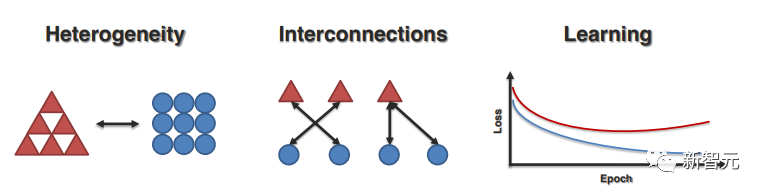
1. 异质性的维度(Dimensions of Heterogeneity)
这部分主要了解多模态研究中常见的异质性维度,以及后续如何影响建模和学习。
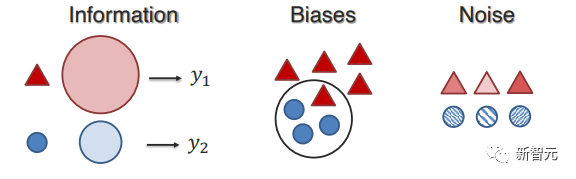
2. 模态互联(Modality Interconnections)
模态之间的连接和交互是多模态模型的重要组成部分,激发了可视化和理解数据集和训练模型中模态互连性质的相关工作。
研究人员将近期的工作分为以下两个方面的量化:
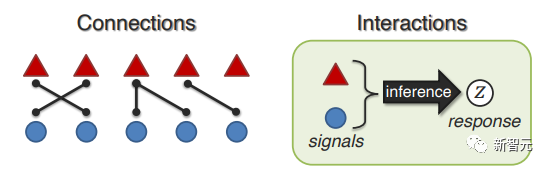
(1)连接:模态之间如何关联并共享共性;
(2)交互:推理过程中模态元素如何交互。
3. 多模态学习过程(Multimodal Learning Process)
最后一个问题主要解决模型从异构数据中学习时所面临的学习和优化挑战,文中主要从三方面介绍了相关工作:
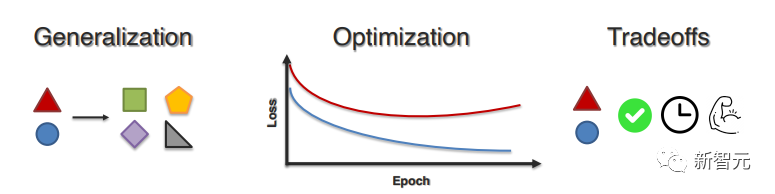
(1) 跨模态和跨任务的泛化;
(2) 更好地优化以实现均衡高效的训练;
(3) 在实际部署中性能、鲁棒性和复杂性之间的权衡。


















