本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
MIT的这项新成果,让取物机器人变得更聪明了!
不仅能理解自然语言指令,还可以拾取没见过的物体。
麻麻再也不用担心我找不到东西了!
研究人员将2D特征嵌入了三维空间,构建出了用于控制机器人的特征场(F3RM)。
这样一来,在2D图像中构建的图像特征和语义数据,就能被三维的机器人理解并使用了。
不仅操作简单,训练过程中需要的样本量也很小。
低训练样本实现轻松取物
我们可以看到,在F3RM的帮助下,机器人可以娴熟地拾取目标物体。

哪怕要找出机器人没遇见过的物体,同样不是问题。
比如……大白(玩偶)。

对于场景中的同种物品,可以根据颜色等信息进行区别。
比如分别拾取同一场景中蓝色和红色两种不同的螺丝刀。
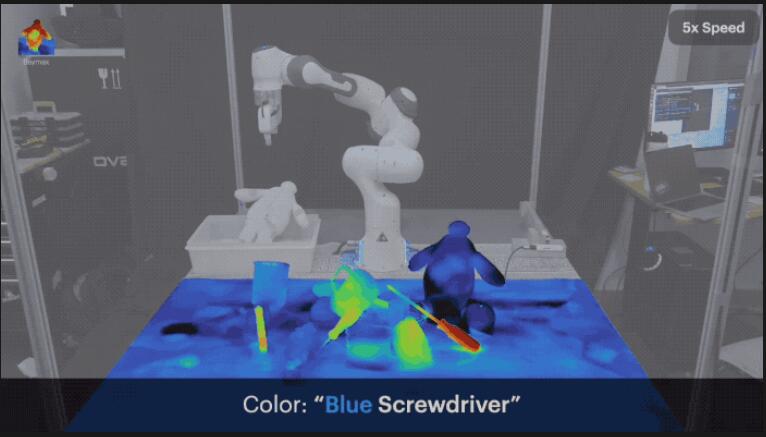
 不仅如此,还可以要求机器人抓取物体的特定位置。
不仅如此,还可以要求机器人抓取物体的特定位置。
比如这个杯子,我们可以指定机器人抓住杯身或者杯把。


除了拾取问题,还可以让机器人把拾到的东西放到指定位置。
比如把杯子分别放到木制和透明的支架上。

团队提供了完整的,没有经过筛选的实验结果。他们在实验室周边随机选取了 out-of-distribution (训练集外)测试样本。
其中使用 CLIP ResNet 特征的 特征场 在三成以上的测试样本中 (78%)成功抓取和放置。在基于开放性人工语言指令的任务上,成功率在 60%。该结果没有经过人工选择 (cherry-picking),因此对特征场在零微调情境下的表现有客观的描述。

那么,如何利用F3RM帮助机器人工作呢?
将2D特征投射到三维空间
下面这张图大致描述了利用F3RM帮助机器人拾取物品工作流程。
F3RM是一个特征场,要想让它发挥作用,首先要得到有关数据。
下图中的前两个环节就是在获取F3RM信息。

首先,机器人通过摄像头对场景进行扫描。
扫描过程会得到多个角度的RGB图像,同时得到图像特征。
利用NeRF技术,对这些图像做2D密度信息提取,并投射到三维空间。
图像和密度特征的提取使用了如下的算法:

这样就得到了这一场景的3D特征场,可供机器人使用。

得到特征场之后,机器人还需要知道对不同的物体需要如何操作才能拾取。
这一过程当中,机器人会学习相对应的六个自由度的手臂动作信息。

如果遇到陌生场景,则会计算与已知数据的相似度。
然后通过对动作进行优化,使相似度达到最大化,以实现未知环境的操作。

自然语言控制的过程与上一步骤十分相似。
首先会根据指令从CLIP数据集中找到特征信息,并在机器的知识库检索相似度最高的DEMO。

然后同样是对预测的姿势进行优化,以达到最高的相似度。
优化完毕之后,执行相应的动作就可以把物体拾起来了。

经过这样的过程,就得到了低样本量的语言控制取物机器人。
团队简介
研究团队成员全部来自MIT的CSAIL实验室(计算机科学与人工智能实验室)。
该实验室是MIT最大的实验室,2003年由CS和AI两个实验室合并而成。
共同一作是华裔博士生William Shen,和华人博后杨歌,由Phillip Isola 和Leslie Kaelbling监督指导。他们来自于MIT CSAIL(计算机和人工智能实验室)和IAIFI(人工智能和基础相互作用研究院 )。 其中杨歌是2023年CSAIL具身智能研讨会 (Embodied Intelligence Seminar) 的共同筹办人.

左:William Shen,右:杨歌
论文地址:https://arxiv.org/abs/2308.07931
项目主页:https://f3rm.github.io
MIT 具身智能 团队https://ei.csail.mit.edu/people.html
具身智能研讨会https://www.youtube.com/channel/UCnXGbvgu9071i3koFooncAw