













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
人工标注数据告急?
Mata新方法仅用少量种子数据,就构建了一个高质量的指令遵循( instruction following)语言模型。
换言之,大语言模型需要大量人工标注的指令数据进行微调,而现在模型可自动从网络语料库未标记的文本中推理出指令。
然后用自己生成的指令数据进行训练,堪比自产自销。
并且用这种方法训练出的模型在Alpaca基准测试上,超越开源羊驼及其一系列衍生模型。
LeCun发推认为该研究在模型自对齐方面具有轰动性:

用网友的一句话总结:
羊驼开始自我训练了。

两句话总结是这样婶儿的:
原本需要指令>响应数据集(需要人工标注),现在只需要简单训练一个“反向模型”做响应>指令。任何文本可随意转换为指令数据集。

还有网友发出灵魂拷问:
是只有我一个人,觉得这看起来像是通往超级智能的道路?如果你不需要额外的高质量外部数据,就能获得越来越智能的LLM,那么这就是一个自我改进的封闭系统。
也许只需要一种强化学习系统来提供信号,然后LLM自身的迭代就可以完成其余的工作。

羊驼:我自己搞数据训练了一头鲸
这种可扩展的新方法叫做指令回译,Mata为用这种方法训练出的模型起了个名字——Humpback(座头鲸,又称驼背鲸)。
(研究人员表示,之所以起这么个名字,是因为它和骆驼背的关系,而且鲸鱼体型更大,对应模型规模更大)
训练一个Humpback的步骤简单来说就是,从少量标注数据开始,使用语言模型生成未标注文本所对应的指令,形成候选训练数据。再用模型评估数据质量,选择高质量数据进行再训练。然后重复该过程,进一步改进模型。

如上图所示,需要准备的“材料”有:
- 一个基础模型——LLaMa
- 一个由Open Assistant数据集中的3200个示例构成的种子数据(Seed Data),每个示例包括一个指令和对应的输出。
- 从ClueWeb语料中抽取了502K段已去重、过滤、删除了潜在低质量段落的未标注文本(Unlabeled Data)。
标注示例和语料来源都有了,下一步就是自增强(Self-augment)阶段。
研究人员用种子数据对基础模型LLaMa进行了微调,获得指令预测模型。然后用这个指令预测模型,为未标注文本推理出一个候选指令。之后组合候选指令与文本(指令-输出对),作为候选增强训练数据,也就是上图中的Augmented Data A。
但还不能用A的数据直接训练,因为未标注文本本身质量参差不齐,生成的候选指令也存在噪声。
所以需要关键的自管理(Self-curate)步骤,使用模型预测数据质量,选择高质量样本进行训练。

具体来说,研究人员使用仅在种子数据上微调的指令模型对候选数据打分。满分五分,分数较高的才会被挑选出来作为下一轮的候选数据。
为了提高模型指令预测质量,研究人员用候选数据迭代训练了模型,在迭代训练中,数据质量也会越来越好。
此外,在组合种子数据和增强数据微调模型时,他们还使用不同的系统提示标记区分了这两个数据源:
- 种子数据使用提示“Answer in the style of an AI Assistant.”
- 筛选数据使用提示“Answer with knowledge from web search.”
进行两轮迭代后,最终模型就新鲜出炉啦。
合并两种训练数据:1+1>2
下面再来看看研究人员的分析结果:

△种子数据和增强数据的指令多样性。内圈是常见的根动词,外圈是与其对应的常见名词。
上图是用8%种子数据和13%的增强数据统计的指令多样性。
可以很直观地看到,在长尾部分增强数据多样性更强,且增强数据与现有的人工标注种子数据相辅相成,补充了种子数据中未出现的类型。
其次,研究人员比较了三个增强数据集:Augmented data,all(无自管理)、 、数据更少但质量更高的
、数据更少但质量更高的
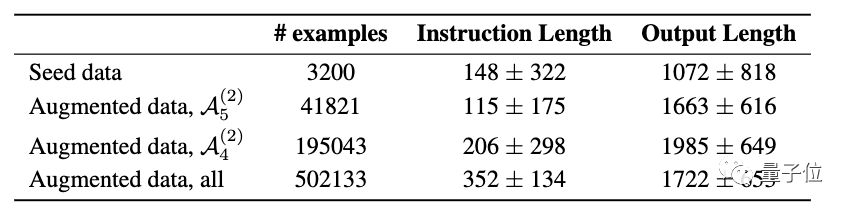
实验观察到,尽管数据集变小,但伴随着训练数据质量的提升模型性能也有了很好的提升。

△使用自筛选评估不同数据大小和质量的自增强数据。y轴表示在使用给定数据大小和质量微调LLaMa 7B时与text-davinci-003的胜率。
(text-davinci-003,一种基于GPT-3的指令遵循模型,使用强化学习在人类编写的指令数据、输出、模型响应和人类偏好上进行了微调)
最后来看一下Alpaca排行榜上的结果。Humpback在不依赖蒸馏数据的情况下,表现明显优于其它方法,并且缩小了与专有模型之间的差距。
非蒸馏(Non-distilled),指不依赖于任何外部模型作为任何形式监督的训练模型;蒸馏(Distilled),指在训练过程中引入更强大的外部模型,例如使用从外部模型蒸馏的数据;专有(Proprietary),指使用专有数据和技术进行训练的模型。

△相对于text-davinci-003的胜率
在与开源模型LIMA 65B、Guanaco 65B、Falcon-Instruct 40B和专有模型davinci-003、Claude的比较中,Humpback的表现也都更符合人类偏好。

此外,研究人员还指出了该方法的局限性:
由于用于训练的文本数据来自网络语料库,微调后的模型可能会放大网络数据的偏差。虽然和基础模型相比,微调后的模型提高了检测偏差的准确性。然而,这并不意味着会完全解决这个问题。
传送门:https://arxiv.org/abs/2308.06259(论文链接)























