Hugging Face上的开源大模型排名榜又更新了,这次荣登榜一的是:鸭嘴兽(Platypus 2-70B)!
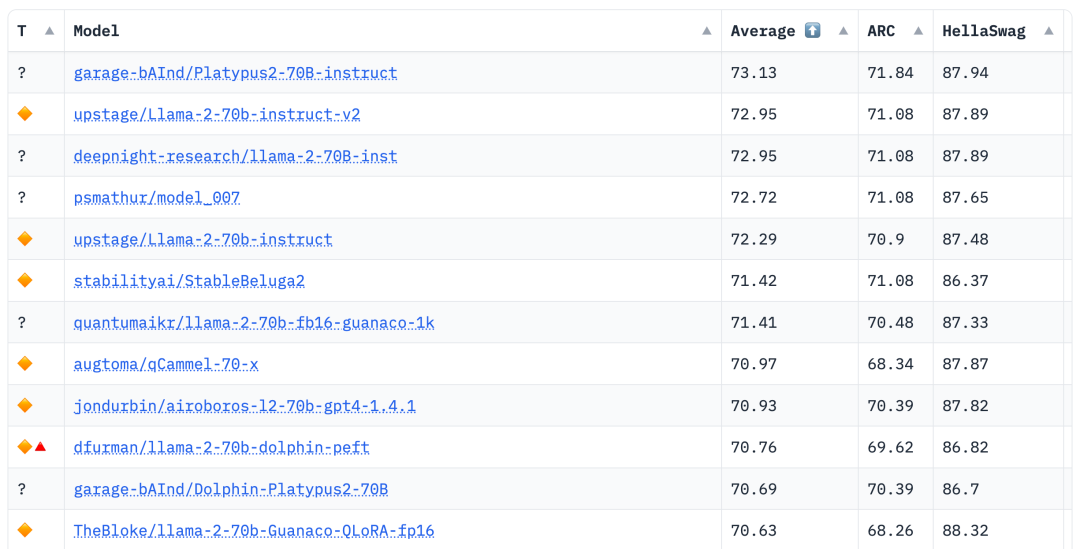
和现在抱脸开源榜单上大部分的模型一样,鸭嘴兽是来自波士顿大学的研究人员基于Llama2微调而来。
同时,鸭嘴兽的进步就像之前所有的开源大模型那样:在提升性能的同时,使用更少的计算资源和数据。
一个13B的鸭嘴兽模型可以在单个A100 GPU使用25k个问题在5小时内完成训练。

论文地址:https://arxiv.org/pdf/2308.07317.pdf
根据研究人员的论文描述,鸭嘴兽70B变强的原因主要是两点:
1. 编辑数据集:删除相似和重复的问题
2. 使用LoRA和PEFT对模型进行了优化,重点关注非注意力模块
而在检查测试数据泄漏和训练数据污染方面,鸭嘴兽也做出了自己的贡献,这为未来的研究提供了有价值的参考。
多快好省的鸭嘴兽
鸭嘴兽主要是通过在一个小而强大的数据集Open-Platypus上使用参数高效调整(PEFT)和LoRA中对非注意力部分的微调来改进模型的性能。
与一般专注于专业领域的模型在微调是耗时又昂贵不同,鸭嘴兽既做到了在总体上的模型性能提升,同时在特定领域的表现也很优秀。
在研究中发现,领域特定的数据集可以提高在所选任务类别上的性能。当与模型合并结合使用时,能够显著减少训练时间。
开源数据集
研究团队通过Hugging Face向公众开放了鸭嘴兽的数据集Open-Platypus:
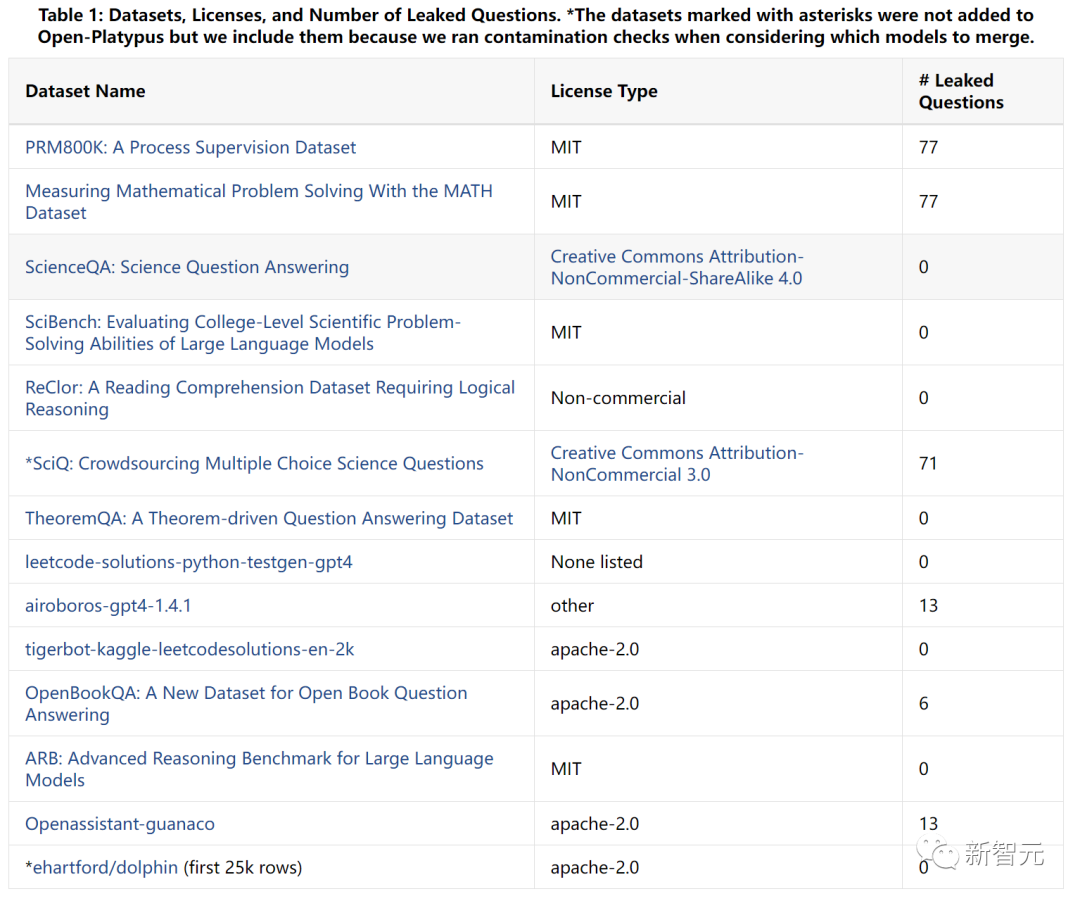
Open-Platypus由11个开源数据集组成,主要由人为设计的问题组成,只有大约10%的问题由LLM生成,能够以最小的微调时间和成本实现强大的性能。侧重于提高LLM的STEM和逻辑能力。
同时,研究团队也对这些数据集进行了优化,这有助于缩小数据集并最大限度地减少数据冗余。
具体操作包括:
通过相似性排除的方法来最小化记忆,删除了所有逐字逐句的重复指令,然后删除了与训练集中其他指令的SentenceTransformers 嵌入具有80%余弦相似度的指令。
并且默认保留具有更详细答案的问题与答案对。因为较长的答案很可能对应更详细的解释和/或逐步解决方案。
解决数据污染
研究团队深入探索了开放式LLM训练集中的污染问题,并介绍了对鸭嘴兽数据进行过滤过程。
研究团队数据过滤的方法,其核心是确保基准测试题不会无意中泄漏到训练集中,这是为了防止测试数据的记忆对基准结果造成歪曲。
考虑到这一点,在确定是否应将问题标记为重复问题并从训练集中删除时,应留有余地。
在确定可疑问题时允许一定的灵活性,因为查询有多种措辞方式,同时,通用领域知识可能会阻止问题被视作重复。
为此,研究团队开发了以下启发式方法,用于指导人工筛选来自 Open-Platypus 的、与任何基准问题相似度大于 80% 的问题。
研究团队将潜在问题分为三类:重复、灰色区域和相似但不同。但为了谨慎起见,研究团队会将它们全部从训练集中删除。
1. 重复:
这些问题几乎是测试集问题的完全复制品,可能只有一个微小的词语变化或轻微的重新排列。
这是我们将之定义为“真正”的污染类别,如上表中泄漏问题的数量所示。这种情况的具体示例如下:

2. 灰色区域
这组问题被称为灰色区域,包括并非完全重复的问题,属于常识范畴。
虽然我们将这些问题的最终评判权留给了开源社区,但我们认为这些问题往往需要专家知识。
值得注意的是,这类问题包括指令完全相同但答案却同义的问题:

3. 相似但不同:
最后一类问题包括尽管具有较高的余弦相似性分数,但答案却截然不同的问题。
这通常可以归因于问题结构的细微变化,从而产生完全不同的答案。
下图中的第一个问题就是一个很好的例子,其中对旋转轴和象限定义的修改极大地改变了最终答案。

微调与合并模型
在完善数据集并对污染进行三重检查后,研究团队对模型进行了微调与合并。
方法主要是低秩逼近(LoRA)训练和参数高效微调(PEFT)库。
与完全微调不同,LoRA 保留了预先训练的模型权重,并在转换层中整合了秩分解矩阵。
这可以减少可训练参数,并节省训练的时间和成本。
例如,鸭嘴兽的13B模型使用1个A100 80GB进行了5个小时的微调,70B模型使用4个A100 80GB进行了22个小时的微调。
而作为比较基准,斯坦福大学对Alpaca-7B 的全面微调是在8 个 A100 80GB 上进行的,并花费了3个小时。
研究团队对模型的微调最初主要针对的是注意力模块,如 v_proj、q_proj、k_proj 和 o_proj。
后来,研究人员转向了对gate_proj、down_proj 和 up_proj 模块的微调,与注意力模块相比,除了可训练参数小于总参数的 0.1% 时,微调这些模块模型的性能表现更好。
为了保持一致性,研究团队对13B和70B模型统一采用了这一方法,可训练参数分别为0.27%和0.2%。
唯一的差异在于这些模型的初始学习率。
研究团队的模型合并策略则旨在评估与Instruct和Beluga等广泛模型或Camel 等专业模型合并的协同效应。
研究团队发现,合并模型能够有效拓宽模型的知识基础,但选择何种模型进行合并,是广泛合并还是集中合并,在决定性能结果方面起着关键作用。
同时,模型合并的效果因测试的具体领域而异。
所有领域的性能提升和下降并不一致,意味着在最终确定合并之前进行特定领域评估的必要性。
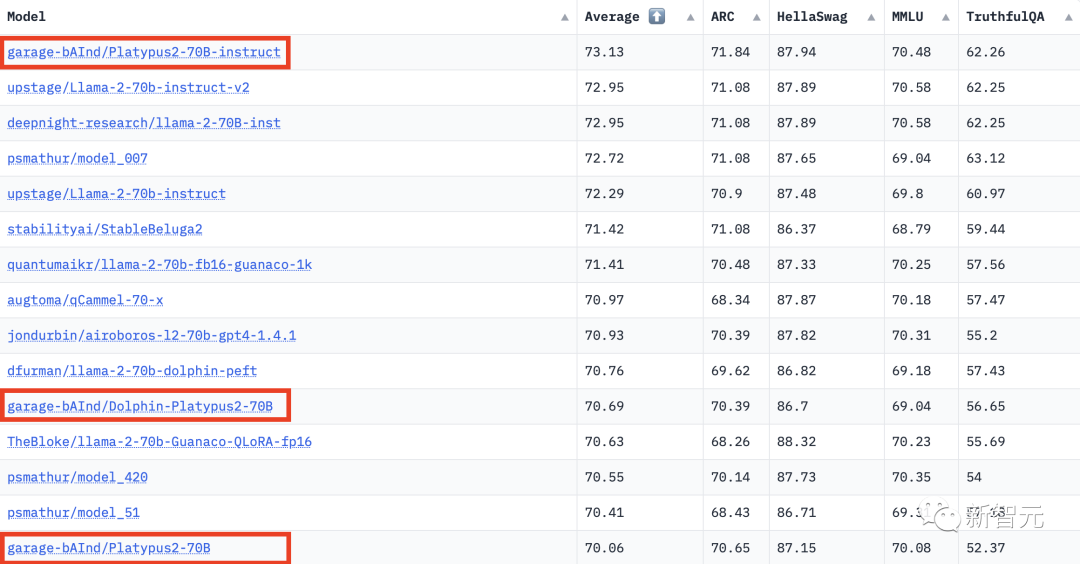
鸭嘴兽排名第一
截止到今天的Hugging Face开源LLM排行榜数据,Platypus2-70B依旧稳坐第一,而它的变体也在众多LLM中排名前列。
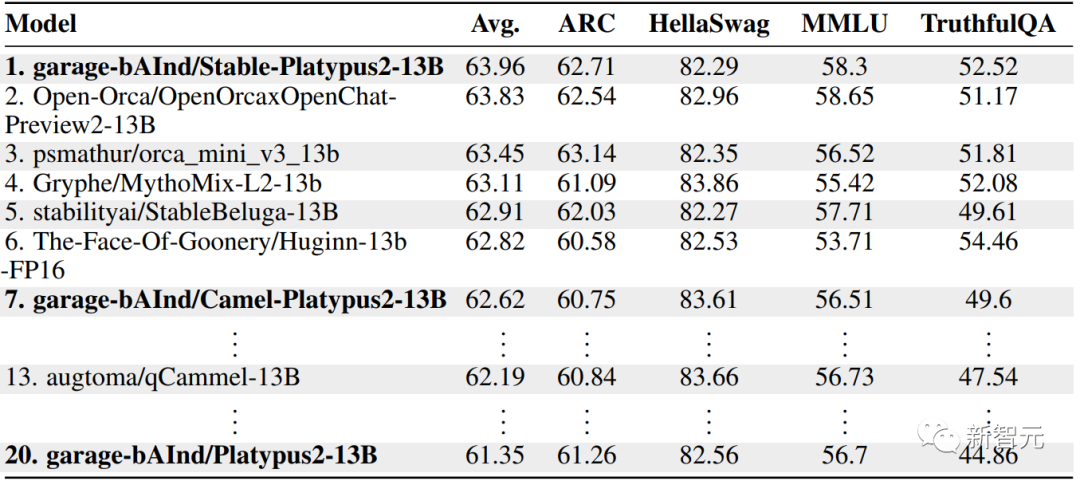
而在13B的尺寸上,鸭嘴兽的表现也同样亮眼,以平均分63.96脱颖而出,成为13B模型的领跑者。
Hugging Face的Open LLM排行榜
Huggingface的Open LLM排行榜目前是开源社区使用最多,同时也是参与模型最多的排行榜。
Open LLM排行榜使用Eleuther AI语言模型评估框架,这是一个在大量不同评估任务上测试生成式语言模型的统一框架,会在 4 个关键基准上对模型进行评估。
1. AI2 :针对科学问题的推理测试,共有25次测试。
2. HellaSwag:常识推理测试,但对大语言模型来说具有相当的挑战性,总共进行10次测试。
3. MMLU:用于测量文本模型的多任务准确性。该测试涵盖 57 项任务,包括初等数学、美国历史、计算机科学、法律等,总共测试10次。
4. TruthfulQA:用于测试模型复制网上常见虚假内容的倾向。
整个测试框架都是开源的,网友可以直接在本地用这个框架测试模型,或者提交模型给Hugging Face来在线跑分。
全世界大大小小的模型都有机会打榜,成功登顶就可以标榜自己是世界第一。

一个韩国团队训练的开源模型,在被鸭嘴兽超越之前曾经是世界第一。他们就很自豪地将这个成果展示在公司主页最瞩目的地方。
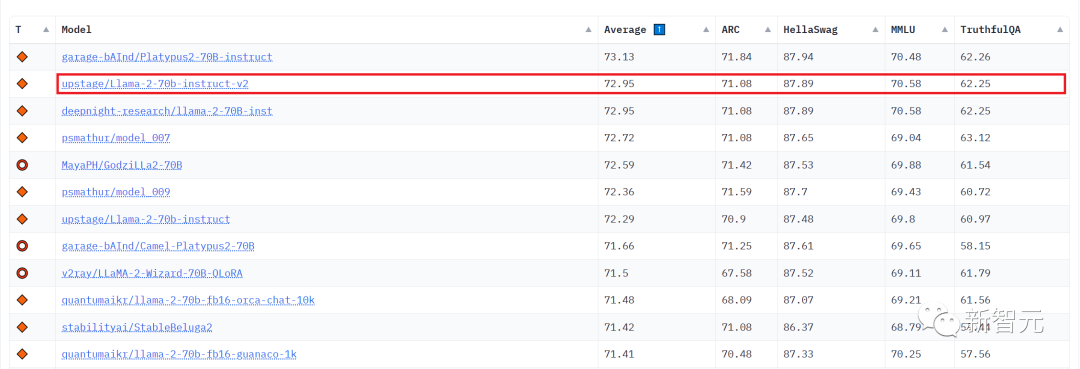
Hugging Face的Open LLM排行榜,不仅能让技术人员客观对比模型的能力,还能给开源社区模型提供一个展示自己以获取外部资源,最终进一步发展的机会。
这也与开源社区的宗旨一致:
秉持高性价比的理念,允许各种改进模型的尝试,拥抱开放和共同进步.....
也许这就是开源社区如此生机勃勃的原因。